The problem: Someone asks you a simple-sounding question. Is the dentist market in Austin saturated, or is there room? So you run a Google Maps scraper, pull 800 businesses for the category and metro, and drop them in a sheet. Then the real work starts. You sort by rating, then by review count, then squint at the map trying to figure out where the gap is. An hour later you have a hunch, no rank data, and no idea what changed since last month. The scraper did its job. The hour of interpretation is the job nobody sold you.
The real competitor was never another scraper. It's the spreadsheet — and the $100-a-month local-SEO subscription you're paying to answer the exact same questions.
This is part of a run we keep coming back to at ApifyForge, because the same gap shows up on every platform. We wrote it about Reddit monitoring, YouTube creator intelligence, and TikTok breakout detection. Local business data is the version with the clearest price tag on the pain, because the interpretation layer is already a product people buy — it's called local SEO software, and it runs a monthly seat.
Local market intelligence is what happens after the scrape: reading whether a category and area is crowded or open, mapping where the service gap is, tracking where a business ranks across the map, and flagging who's gaining, opening, or closing over time. A plain Maps scraper hands you rows and stops. The Google Maps Scraper actor is the worked example throughout this post: it takes a category and a location and returns a finished market read — saturation, gaps, geo-grid rank, competitor movers, and the history behind them — on pay-per-event pricing, and migrates an existing pipeline unchanged through a compat output.
In this article: What a Maps scraper returns · Why flat rows fail · How a market read works · Geo-grid rank · Market Memory · Alternatives · Best practices · Common mistakes · Limitations · FAQ
Key takeaways
- Extraction isn't the bottleneck; interpretation is. The dominant Maps scraper on the Apify Store earned its rank, but the hour you spend deciding "is this market saturated and where's the gap" is the job nobody sold you.
- A local market intelligence layer returns the decision instead: a saturation band, an opportunity index, a gap count, per-business scores and archetypes, and geo-grid rank rolled into a Share of Local Voice score.
- Four things break in a spreadsheet at scale: saturation and gap math, geo-grid rank across the map, competitor momentum, and run-over-run change tracking. Each is a maintained service, not a formula.
- The moat is Market Memory — the openings, closures, rating trajectory, and rank shifts Google Maps discards. A clone can copy the scraper but can't backfill local-market history.
- The Google Maps Scraper actor ships that decision layer on pay-per-event pricing and drops into an existing pipeline unchanged via
outputProfile: compat.
Rows vs a market read: a concrete look
| You ask | A row dump gives you | A market read gives you |
|---|---|---|
| Is this market saturated? | 800 rows; count and guess | A saturation band and market state, one record |
| Where's the service gap? | Sort by area yourself | Underserved sub-areas ranked by opportunity |
| Where do I rank across the map? | Nothing (one search point) | Rank at every grid point + a Share of Local Voice grade |
| Who's gaining in this market? | A snapshot of today | Competitor movers ranked by momentum |
| What changed since last month? | Two exports; diff by hand | A change briefing with new entrants, closures, rank shifts |
What is local market intelligence?
Short version: local market intelligence is a system that turns a category-and-location scrape of Google Maps into a decision — is this market saturated, where's the gap, who's gaining, where do I rank — and returns a finished market read instead of a flat list you interpret yourself.
A Google Maps scraper and a local market intelligence layer are not the same product. A scraper extracts: it returns business name, rating, review count, category, and address as rows, then stops. Intelligence is what happens after extraction. It's the saturation math, the gap mapping, the geo-grid rank, and the run-over-run comparison that turn a scrape into an answer you can hand a client or a manager.
There are broadly three categories of local business tooling in 2026. Row scrapers export the place data and leave every decision downstream to you. Local-SEO subscriptions (the geo-grid rank-tracking platforms) sell the interpretation layer, usually as a monthly per-seat dashboard. Market intelligence actors ship the decision layer on a per-run basis: saturation, gaps, geo-grid rank, competitor movers, and persistent memory per market. At ApifyForge we group these by what they output, not just what they scrape — because the output contract is what decides whether you still open a spreadsheet afterward.
Why does this matter now?
Local market reads matter more in 2026 because the data underneath moves fast and the interpretation is what's expensive. Google itself notes business information changes constantly as places move, close, rebrand, or change hours, and independent estimates put local business data decay at roughly 20-30% a year.
The scale is the problem. BrightLocal's 2024 Local Consumer Review Survey found that local search and reviews drive the majority of how consumers pick a business, which means every category in every metro has more competitors worth tracking than a person can eyeball weekly. And the tooling that answers "where do I rank across the map" — the geo-grid rank grid that platforms like Local Falcon and BrightLocal sell — is priced as a recurring subscription because interpretation, not extraction, is the thing worth paying for. When your job is a weekly market read across several client markets, "scrape 800 rows and sort them by hand" is the wrong direction.
What does a Google Maps scraper actually return?
A Google Maps scraper returns substrate: one record per business with name, place ID, category, rating, review count, address, and coordinates. Accurately extracted, genuinely useful data. If your job is "get me the rows," that's the right tool and you should use it.
Here's roughly what one record looks like. Note this is output you read, not code you run.
{
"title": "Northstar Family Dental",
"placeId": "ChIJN1t_tDeuEmsRUsoyG83frY4",
"categoryName": "Dentist",
"address": "1200 Pinnacle Ave, Austin, TX",
"totalScore": 4.3,
"reviewsCount": 218,
"permanentlyClosed": false
}
The trouble starts when your job is anything other than "get me the rows." Which is most jobs. A 4.3 rating with 218 reviews is a number, not a position. Is that strong for this market or middle of the pack? Where does this business rank at the north end of town versus downtown? Is it climbing or fading? None of that is in the row, and nobody computes it for 800 businesses by hand. They eyeball. They guess. And a single search pulls one point on the map, so a business that ranks third downtown and twentieth in the suburbs looks like a single flat number.
Why do flat Google Maps rows fail for market analysis?
Flat Google Maps rows fail for market analysis because they externalise every decision back onto a human. An 800-row export contains no saturation read, no rank grid, and no run-over-run memory, so the actual analysis — is this crowded, where's the gap, who's gaining — still happens by hand in a spreadsheet.
Here's the part people underestimate. Local market intelligence is genuinely hard, which is exactly why most tools quietly stop at extraction:
- Rank is a map, not a number. A business ranks differently at every point in a metro. One search returns one vantage point. Real local rank is a grid of results across the area, which is why local-SEO platforms sell exactly that view.
- Saturation is relative and spatial. "40 dentists" means nothing without density: 40 clustered downtown with an empty north side is an opportunity; 40 evenly spread is a wall. That's per-sub-area math, not a row count.
- Momentum is a trajectory, not a snapshot. Three businesses can all sit at 4.5 stars this week and only one is accelerating. A single pull can't tell you which; you need history.
- The dangerous competitor is invisible in a row dump. A brand-new entrant is obvious. The one that was already there and just started surging — review velocity climbing, rank rising — only shows up against tracked history.
- Most tools forget every prior run. A one-shot scrape can never tell you what opened, closed, or moved since last month.
The real competitor to a Maps scraper was never another scraper. It's the manual spreadsheet workflow — and the subscription you bought to escape it. That's the same argument we made for decision-first analytics: the output should be one routable answer, not a chart you re-interpret. It's also the natural next step from "Google Maps scraping isn't a data strategy", which made the case for resolving place data; this post is about reading the market those places form.
How does a local market intelligence layer work?
A local market intelligence layer works by adding a decision layer on top of the scraped place data. After extraction, deterministic scorers measure each business against its market cohort and its own tracked baseline, the area is mapped for density bands and underserved sub-areas, and every record gets a bounded score so the output sorts by what matters — opportunity, position, or momentum — instead of raw rating.
The mental model is a pipeline: category and location → read the market → score every business → map gaps and movers → compare against tracked history → structured output. Each layer adds something the row dump never had.
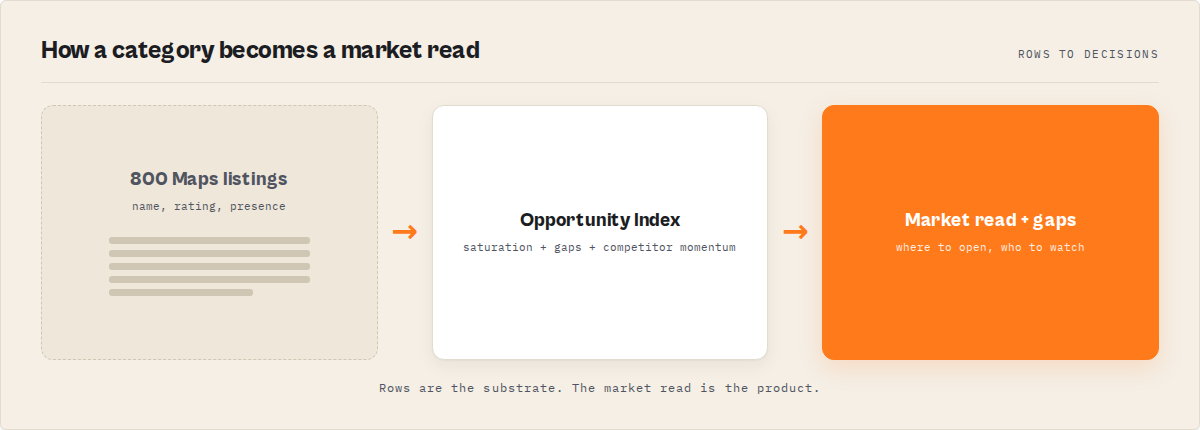
The scoring layer is the interpretation step. Instead of leaving you to judge whether a market is crowded, it returns a Market Overview: a competitor count, a saturation band, a market state, a 0-100 opportunity index, and a gap count — the five-second read. Every business underneath carries an archetype (rising, market-leader, established-steady, fading, new-entrant, at-risk, closed) with the evidence attached, so a "rising" label comes with "review velocity up versus its 90-day baseline," not a vibe. All of it is deterministic, with no AI narration in the decision path.
You can see the shape on a live dataset by running the Google Maps Scraper actor on any category and city in market mode — the Market Overview lands in a few minutes.
What does a market read return?
A market read returns a ranked, decision-ready record per business plus a market-level overview. Here's a trimmed business record so you can see the shape. Again, this is output you read, not code you run.
{
"recordType": "place",
"title": "Northstar Family Dental",
"categoryName": "Dentist",
"totalScore": 4.3,
"reviewsCount": 218,
"rank": 7,
"signalProfile": { "label": "rising", "strength": 0.71, "evidence": ["Review velocity up vs its 90-day baseline"] },
"scores": {
"competitivePositionScore": 64,
"momentumScore": 73,
"saturationScore": 81,
"confidence": { "grade": "medium", "coveragePct": 88 }
},
"attention": { "attentionPriority": "high", "whyNow": ["Climbing the grid rank, rating stable"], "recommendedAction": "Track" }
}
Everything below rank is the decision. It's what an experienced analyst would produce by hand after an hour of sorting: this business sits mid-pack on position (64), but momentum is high (73) and it's climbing the grid — so the recommended action is Track, not ignore. attentionPriority is the field your automation routes on. recommendedAction is always a prioritisation instruction (Track, Watch, Skip), never an outreach or in-platform action. Reading the market is the job; contacting the businesses is a different tool.
What is a geo-grid rank tracker and Share of Local Voice?
A geo-grid rank tracker lays a grid of points across a metro, checks where a focal business ranks at each point for a keyword, and rolls the results into a single Share of Local Voice score. It's the local-rank-grid view that dedicated local-SEO platforms charge a monthly seat for, reproduced on a per-run basis.
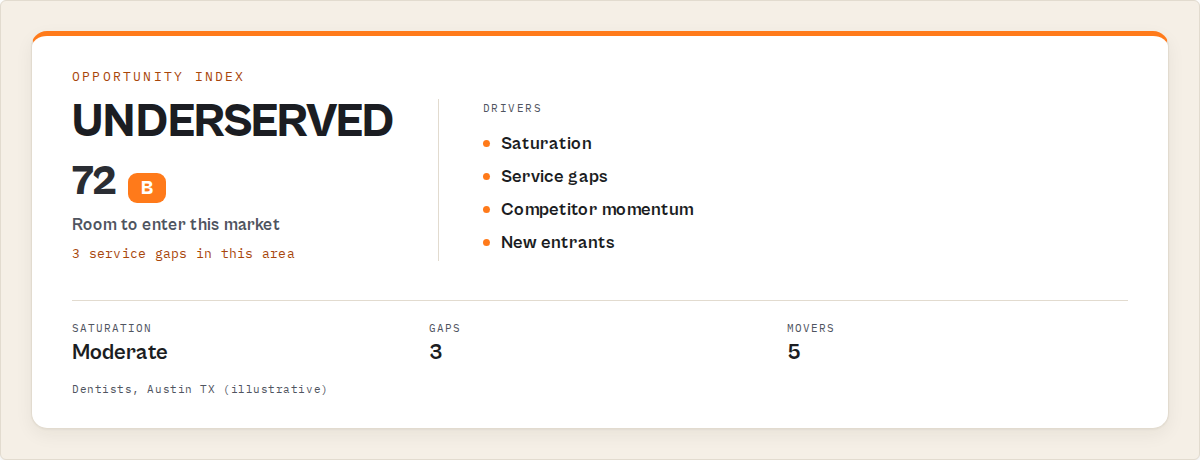
The reason a grid matters: a business can rank third where its office sits and fall off the map two miles north. A single search hides that; a 5×5 grid at 800-metre spacing gives you 25 vantage points and a real coverage picture. Run the same grid weekly and you get rank-over-time — the trend line that tells you whether last month's local-SEO work actually moved anything. In the actor this is geo_grid mode, and because it's deterministic and re-runnable, the grid is directly comparable run to run.
Share of Local Voice condenses those 25 points into one number with a grade, so "how visible am I across this area" becomes a single answer a client understands. That's the headline metric the geo-grid subscription platforms are built around, and it's the clearest example of interpretation being the product, not the scrape.
What is Market Memory, and why can't a clone copy it?
Market Memory is the tracked history a market read accumulates: every run records a timestamped public snapshot of every business and market it touches, so openings, closures, rating moves, and rank shifts build up over time. Google Maps shows you today; Market Memory remembers what changed.
This is the moat, and it's the part a competitor can't backfill. Anyone can copy a scraper. Nobody can retroactively acquire the last six months of a market's openings, closures, and rating trajectory — that data only exists if you've been recording it. Every run a customer makes on a market deepens that market's history, so the longer the actor runs on a metro, the sharper its read of that metro gets. A new clone starts from zero.
Two things fall out of it directly. Competitor movers — the businesses accelerating fastest, including the emerging competitor that was already there and quietly surged, which is the warning a row dump can never surface. And watchlist deltas — name a market, re-run it on an Apify schedule, and instead of the full list you get only the change set: new entrants, closures, rating moves, rank shifts, ready for a client report. That recurring "what changed" loop is the product, not the raw scrape.
What are the alternatives to a local market intelligence layer?
There are four practical alternatives, each with real tradeoffs. The right choice depends on whether your job is one-off extraction or recurring analysis, how much engineering you want to own, and whether you need the geo-grid rank view.
1. A plain row scraper (e.g. compass/crawler-google-places). The dominant Google Maps place scraper on the Apify Store, and an excellent choice when raw extraction is all you need. Returns business rows — name, rating, reviews, category, address. Best for: a one-time bulk pull you'll analyse yourself, or feeding a pipeline you already own. Where it stops: it ships none of the analysis downstream of extraction, so the saturation read, the rank grid, and the monthly diffing stay manual forever.
2. Build it yourself. Wire up Maps extraction at scale, a coordinate grid for rank, saturation and gap math per sub-area, per-business momentum baselines, a persistent snapshot store for history, and a change-diff step — then keep all of it versioned and reproducible. Best for: a team with spare engineering capacity and a very specific in-house need. Where it breaks: you now own a maintained service, not a script. The rank-grid geometry, the density math, residential-proxy handling at scale, and the historical store that makes "what changed" possible all become yours. That last piece is months of accumulated data you can't shortcut.
3. A monthly local-SEO subscription (e.g. Local Falcon, BrightLocal). Sells the geo-grid rank view and competitor tracking through a dashboard on a per-seat monthly plan. Best for: agencies that live in a dashboard and want a polished human-facing UI. Where it's a different shape: it's built for human-driven analysis, not automation — API access and scriptability are limited, pricing is a recurring seat regardless of usage, and the saved market history is usually scoped to what the dashboard shows rather than a store you own and query.
4. A market intelligence actor. Focuses on local markets and ships the decision layer on a per-run basis: saturation, gaps, geo-grid rank, Share of Local Voice, competitor movers, and persistent memory per market. Best for: recurring market reads, client reporting, and site-selection scans where the value is is this crowded, where's the gap, who's gaining. Where it's less suitable: building contact or lead lists, or pulling deep review text — different tools for those.
Each approach has trade-offs in coverage, engineering cost, automation fit, and time-to-value. Here's the comparison side by side.
| Approach | Time to first result | Saturation + geo-grid rank | Run-over-run memory | Cost shape |
|---|---|---|---|---|
| Plain row scraper | ~minutes | None (manual) | None | Per-result scrape price |
| Build it yourself | Weeks to months | You build it | You build + accumulate it | Engineering time + infra |
| Local-SEO subscription | Setup + onboarding | Geo-grid yes; saturation varies | Dashboard-scoped | Monthly per-seat |
| Market intelligence actor | A few minutes | Built in, deterministic | Built in, compounds | Per-run, decision layer included |
Pricing and features based on publicly available information as of July 2026 and may change. Re-verify any platform's live price and API terms before relying on the comparison.
One of the best fits for recurring, automation-first local analysis is a market intelligence actor, because it collapses the spreadsheet-and-subscription workflow into one scheduled run. For a purely human, dashboard-first agency workflow, a local-SEO subscription may suit better. If you're weighing the numbers, the ApifyForge cost calculator models per-run spend, and the Google Maps scrapers comparison lines up the options.
Best practices for local market analysis
- Lead with the right rank axis.
opportunityto surface the best openings first,momentumfor competitor tracking,competitivePositionfor a where-do-I-stand read. The axis is the whole product for that job. - Name a watchlist and run on a schedule. The product is the run-over-run delta. One run reads today; the memory clock starts on run two and can't be backfilled.
- Branch automation on
attentionPriority, not raw scores. Filter to thehighbucket so alerts stay stable across runs. - Set an
areafor big metros. A single map screen caps how many businesses return. A circle or polygon reads wider than one screen so a large market isn't silently truncated. - Tune the grid for rank precision. A larger
grid.sizeand tighterspacingMetersgive a finer rank map at higher cost — size it to the budget and the metro. - Use the compat profile for raw ingestion. When a pipeline only needs the standard place field set,
outputProfile: compatreturns it unchanged, no rewrite. - Check the Coverage view before trusting a read. It shows what was requested, scraped, and skipped, so you know whether a screen cap or an area limit clipped the market.
- Wire a webhook on run finish. Push the Market Feed into Slack or a planning board so the "what changed" brief becomes a notification, not a manual pull.
Common local market analysis mistakes
- Treating a scrape as analysis. Exporting rows is extraction. Analysis is the saturation read and rank comparison you're doing by hand afterward. Move that work into the tool.
- Sorting by rating and calling it a market read. A 4.8 with 12 reviews and a 4.3 with 900 are not comparable, and neither tells you where the gap is. Density and rank do.
- Trusting one search for rank. A single Maps search is one point on the map. Real local rank needs a grid; anything less hides where you actually fall off.
- Expecting deltas on the first run. Memory can't be invented. Run one reports first-sight honestly with empty trajectory; openings, closures, and momentum sharpen after several scheduled runs on the same market.
- Ignoring the emerging competitor. The business that was already there and just started surging is the story a row dump can't tell. It only shows up against tracked history.
- Reading "fading" or "at-risk" as a death sentence. Those labels are descriptive reads of current evidence, never a prediction that a specific business will close. Treat them as attention flags, not verdicts.
Mini case study: an agency's weekly market read
Before. A local-SEO agency tracking dentist and med-spa clients across a metro pulled roughly 800 businesses per market into a sheet each week, then spent close to an hour per market sorting by rating and review count, eyeballing who "looked like they were growing," and manually checking a handful of rank spots. Emerging competitors were caught late, if at all, because nobody could hold last month's export in their head. The geo-grid rank check was a separate subscription and a separate login.
After. They switched to a scheduled watchlist run per client market with rankBy: opportunity. Each week they read the Market Overview (saturation, gaps, movers), skimmed the geo-grid Share of Local Voice for each client, and acted on the handful of businesses flagged high. The week a competitor's review velocity surged, the change briefing surfaced it as an emerging competitor within a run, with the evidence attached.
The reframe is the whole point: an hour of manual sorting plus a separate rank-tracking login collapsed into one scheduled read. These numbers reflect one agency's workflow; results vary with how many markets you track, how often you run, and how large each metro is.
Which teams feel this pain hardest?
The teams that get the most out of local market intelligence run a market read as continuous work, not a one-off pull. Local-SEO agencies handing clients a weekly rank-and-competitor report. Multi-location brands and franchises benchmarking locations and picking expansion sites. Site-selection and real-estate teams answering "where is this category underserved." Investors and analysts assessing local market dynamics and roll-up targets. And SMB owners who just want to know how they stack up and where they're invisible on the map.
If your local work is a one-off list you build once and never refresh, you don't need this. A plain scraper is cheaper and fine. The intelligence layer earns its keep when the read recurs and the geo-grid rank matters.
Limitations
Honest constraints, because the tool that names them is the one you can trust:
- Market history starts empty. The first run of any market has no trajectory, openings, closures, or rank-over-time yet. These accumulate only as the market is re-read, so day one is a snapshot, not a history.
- Maps result caps. A single map screen returns a limited set. Set an
areapolygon to read wider, and check the Coverage view for what was reached — a big metro without an area can be silently truncated. - Descriptive, not predictive. Fading, at-risk, and closure labels describe current evidence. They are never a forecast or a solvency verdict about a specific business.
- Public business data only. No reviewer personal data, and no contact or lead-gen output. For outreach-ready leads, use the Google Maps Lead Enricher instead; for deep review text, use the Google Maps Reviews Scraper.
- Closed status and popular-times lag. Both are passed through as Google Maps reports them and can be stale, so they're flagged rather than treated as ground truth.
When you need this
You probably need a local market intelligence layer if:
- You run a weekly or monthly market read across one or many local markets and hand the result to a client or a manager.
- You need geo-grid rank and Share of Local Voice without paying a separate monthly local-SEO seat.
- You're picking where to open a location and need underserved sub-areas ranked by opportunity.
- You track a competitor set week over week and want the run-over-run "what changed" delta.
- You're feeding an AI agent or automation that needs local business records with saturation, rank, and momentum signals attached.
You probably don't need this if:
- You want a one-off raw export to process in your own pipeline (a plain scraper is cheaper and right).
- You're building contact or email lists (use a lead-enrichment actor).
- You need deep review text at volume (use a reviews scraper).
- You want a prediction of whether a specific business will close (nothing honest does that).
Frequently asked questions
What is the difference between a Google Maps scraper and local market intelligence?
A Google Maps scraper extracts place data (name, rating, reviews, category, address) and returns rows. Local market intelligence returns the same data plus the decision: a saturation band, a gap count, an opportunity index, per-business scores and archetypes, geo-grid rank rolled into Share of Local Voice, competitor movers, and the market history behind them. The scraper is the substrate. The intelligence layer is the substrate plus what to do about it.
How do I check if a local market is saturated?
Run market mode with a category and location. The Market Overview returns a saturation band and a market state in a single run, along with a competitor count and a gap count. Because saturation is spatial, it also maps density by sub-area, so you see not just how many competitors exist but whether they're clustered — which is where the opportunity hides.
How does a geo-grid rank tracker work?
Geo-grid mode lays a grid of points across a metro and checks where a focal business ranks at each one for your keyword, then rolls the results into an aggregate Share of Local Voice score with a grade. A 5×5 grid gives 25 vantage points, so you see where you rank downtown versus the suburbs instead of one flat number. Re-run the same grid on a schedule for rank-over-time.
Is this a replacement for a monthly local-SEO subscription?
For teams that mainly need the geo-grid rank grid, competitor tracking, and client-ready reports, it produces those on a per-run basis rather than a monthly per-seat plan. Where a dashboard-first agency wants a polished human UI and doesn't need automation, a subscription may fit better. The rank grid and Share of Local Voice match what those platforms sell; the difference is how you run it and what history you own.
Does this actor predict whether a business will close?
No. Fading, at-risk, and closure labels are descriptive reads backed by review-velocity, presence, and cohort evidence — attention flags, never a forecast or a solvency verdict about a specific business. It reports what the current evidence shows and passes through closed status exactly as Google Maps reports it, flagged where it may be stale.
Can I migrate from compass/crawler-google-places without changing my code?
Yes. Set outputProfile: compat to return the exact place field set of the leading Maps scraper, so downstream code reading the standard fields works unchanged. You migrate the pipeline as-is and get the market intelligence layer as an additive upgrade rather than a rewrite. It's a practical drop-in for buyers who also want the saturation read and the rank grid.
How much does it cost to read a local market?
The Google Maps Scraper actor uses pay-per-event pricing: you pay per business analysed, with the decision layer included and no monthly subscription. Set a run spending limit to cap any single run, and Apify's free tier includes monthly credits to test with. You need an Apify account to run it. Check the actor's pricing tab for current per-event rates.
Is it legal to scrape Google Maps business data?
It reads publicly available business listings only and doesn't log in, bypass access restrictions, or harvest reviewer personal data. Whether your specific use is permitted depends on your jurisdiction and intended use, including data-protection rules and platform terms. For background, see Apify's guide to web scraping legality. Consult legal counsel for your case.
The bottom line
If you pull Google Maps data once and process it yourself, use a row scraper. It's cheaper, and it's the right tool for that job. But if you're reading a market every week — saturation, gaps, rank, who's gaining — extraction stopped being the bottleneck a long time ago. The work is interpretation, and you're already paying for it twice: once in analyst hours, once in a local-SEO seat. The Google Maps Scraper actor ships that interpretation as the default output: a market read, ranked and explained, remembered run over run. Rows are the substrate. The market read is the product.
Ryan Clinton publishes Apify actors and MCP servers as ryanclinton and builds developer tools at ApifyForge.
Last updated: July 2026