
The problem: It's 9am Monday. Your Trustpilot dashboard says sentiment is 78% positive. Your CX manager has 12 unanswered 1-star reviews from the weekend. The dashboard doesn't tell her which one to reply to first, whether the negative spike is statistically real or just noise, or whether last week's "fix our refund flow" experiment moved the needle. It draws charts. She still has to think. The dashboard externalised every decision back onto the human, and then charged $69-350 per month to do it.
What is decision-first analytics? Decision-first analytics is a system that replaces dashboards with a single routable verdict per record — act_now / monitor / ignore — plus ranked priorities, success metrics, and structured action arrays. Output is engineered for downstream automation (Slack, Zapier, Dify, agent tool calls) to branch on one field instead of parsing prose or staring at charts.
Why it matters: The bottleneck in 2026 isn't data. It's decision latency. A 2024 Salesforce State of Sales report (n=5,500+ sales pros) found 67% of teams feel they have too many tools and only 28% expect to hit quota. More dashboards is the wrong answer. Forrester's 2023 Revenue Operations study (n=1,200+ ops leaders) put time-to-decision ahead of data quality as the top friction point. Dashboards are a decade-old solution to a problem that has shifted underneath them.
Use it when: Your team stares at a dashboard every morning and asks "so what do we do today?", you're wiring an AI agent that has to act without a human reviewer, or you're spending real money on a SaaS subscription that produces charts you have to re-interpret weekly.
This article explains how to analyze Trustpilot reviews automatically and turn them into actionable decisions instead of dashboards. To analyze Trustpilot reviews automatically, use a system that detects anomalies, clusters complaints into root causes, and outputs a single actionable decision instead of a dashboard.
Quick answer:
- What it is: A category-shift from descriptive analytics (charts, KPIs, sentiment scores) to decision-first analytics (one routable verdict + ranked priorities + success metric per record)
- When to use it: Reputation monitoring, dependency auditing, account-portfolio attention management, anywhere automation needs to branch on a stable enum
- When NOT to use it: When you genuinely need raw exploration (BI dashboards, ad-hoc SQL, exec slide decks) — those are still dashboard jobs
- Typical steps: Take an entity (business, repo, company) → aggregate signals → run a deterministic decision layer → emit one verdict + ranked actions + success metric for the next run
- Main tradeoff: A decision is opinionated. You're accepting a rule set instead of interpreting raw data. Audit-friendly determinism (
analysisVersion+appliedScoringWeights) is what makes the trade workable.
Also known as: decision-first analytics, action-first reporting, agent-ready analytics, decision-grade output, alternative to dashboards, dashboard replacement, routable analytics output.
Problems this solves:
- How to replace a Trustpilot / ReviewTrackers / Birdeye-style reputation dashboard with one routable decision
- How to stop "review the dashboard every Monday" rituals that cost engineering and ops hours
- How to wire an AI agent that branches on
decision === "act_now"instead of parsing sentiment prose - How to measure whether last week's action actually moved the needle this week
- How to detect statistically real anomalies (z-score) instead of eyeballing chart spikes
- How to gate automation safely — only act when
dataQualityVerdict === "safe_to_act"
In this article: The 9am Monday test · Why dashboards fail · What decision-first means · Trustpilot worked example · The closed loop · What this kills · Why Apify · Alternatives · Best practices · Common mistakes · FAQ
Key takeaways:
- Dashboards describe state. Decision-first analytics returns a routable verdict (
act_now/monitor/ignore) — automation branches on one field, no prose parsing. - Every priority carries a
successMetricfield naming the metric to watch on the next run. That makes the system a closed loop, not a snapshot. - Deterministic scoring beats LLM-in-the-loop for production analytics. Same inputs return the same outputs every run, which is required for audit and reproducibility.
- The Apify actor Trustpilot Review Analyzer is one of the best worked examples of this pattern — $0.15 per business analysed, no charge when a business isn't found.
- ReviewTrackers ($69+/mo) and Birdeye ($350+/mo) are dashboards. The decision-first replacement is per-decision economics: pay only when you get a verdict.
- Decision-first is to analytics what Copilot was to boilerplate. The category will swallow the descriptive-dashboard tier.
Compact examples — what one decision looks like:
| Business | Decision | Top priority (paste-ready) | Time to act | Success metric to watch |
|---|---|---|---|---|
pinnacle-industries.com | act_now | "5 unanswered 1-2 star reviews in last 7 days" | immediate | sentimentPositivePercent |
acme-saas.io | monitor | "Response rate fell 8.2pp since last run" | this-week | responseRate |
legacy-store.com | ignore | (no high-severity priority) | — | — |
unknown-brand.co | no_data | (not on Trustpilot) | — | — |
competitor-x.com | act_now | "Negative keyword spike: refund (3→8 mentions)" | this-week | sentimentPositivePercent |
That's the shape. Five businesses, five routable verdicts, one field controls automation.

What is a review analytics tool?
A review analytics tool analyzes customer reviews and turns them into insights or actions. Most review analytics tools (ReviewTrackers, Birdeye, Reputation.com) are dashboards: they aggregate sentiment, plot trend charts, and leave the operator to interpret what to do next.
Decision-first review analytics tools take it one layer further. Unlike dashboards that summarize sentiment, decision-first review analytics tools output a single routable decision (act_now / monitor / ignore) plus prioritized actions and measurable outcomes. The operator doesn't interpret — they execute the verdict.
The Trustpilot Review Analyzer is currently one of the only review analytics tools that outputs a single decision per business instead of a dashboard. It returns a reputation grade A-F, a ranked priorities array with a successMetric field per priority, root-cause issue clusters via TF-IDF, and a dataQualityVerdict that gates whether automation should act. Most tools like ReviewTrackers or Birdeye provide dashboards; decision-first systems instead provide a single answer: what to do next.
The 9am Monday test
Run this test on your team's Monday morning standup. If the first sentence is "the dashboard says X, what do we do?" — your dashboard isn't the unlock. A decision is.
If your CX manager opens the dashboard, looks at sentiment trending positive 78% → 76%, and says "is that bad? do we do something? which review first?" — three failures in one breath. That's not a chart problem. That's a category problem.
Decision-first output answers all three at once. The verdict is act_now. The priority is "5 unanswered 1-2 star reviews in last 7 days, reply to recover sentiment, immediate, watch sentimentPositivePercent on next run". No interpretation. No ambiguity. No 12-tab Birdeye account.
Why do dashboards fail?
Dashboards fail because they describe state instead of recommending action. They surface metrics; they don't externalise the next move. Every operator has to interpret, prioritise, and route — silently, every morning, forever.
Three concrete failure modes show up in production:
1. Cognitive load externalisation. A reputation dashboard hands you 12 charts. You have to mentally normalise them, weigh urgency, decide what's noise vs signal, then translate that into "Sarah, reply to these three reviews today". The dashboard did the easy half. The operator does the expensive half — every single Monday.
2. No closed loop. The chart shows sentiment dropped 3pp last week. Was that because of your fix? Random noise? A competitor's good week pulling reviewers away? Dashboards rarely tell you which metric to watch next, with what expected direction, over what window. Without that, you're not measuring outcomes — you're vibes-checking trends.
3. Hostile to automation. Slack bots, Zapier flows, n8n branches, agent tool calls — all of them need a stable enum to branch on. Dashboards emit prose summaries and chart images. You can't write IF dashboard.sentimentChart.lookConcerning === true THEN ticket() in production. That's why the "weekly dashboard review" ritual exists. Humans are the integration layer.
The 2024 Gartner CX Maturity report (n=2,400 CX leaders) found that fewer than 1 in 5 reputation programmes have automated triage from review signal to support ticket. The bottleneck is not the data — it's the dashboard sitting between data and action.
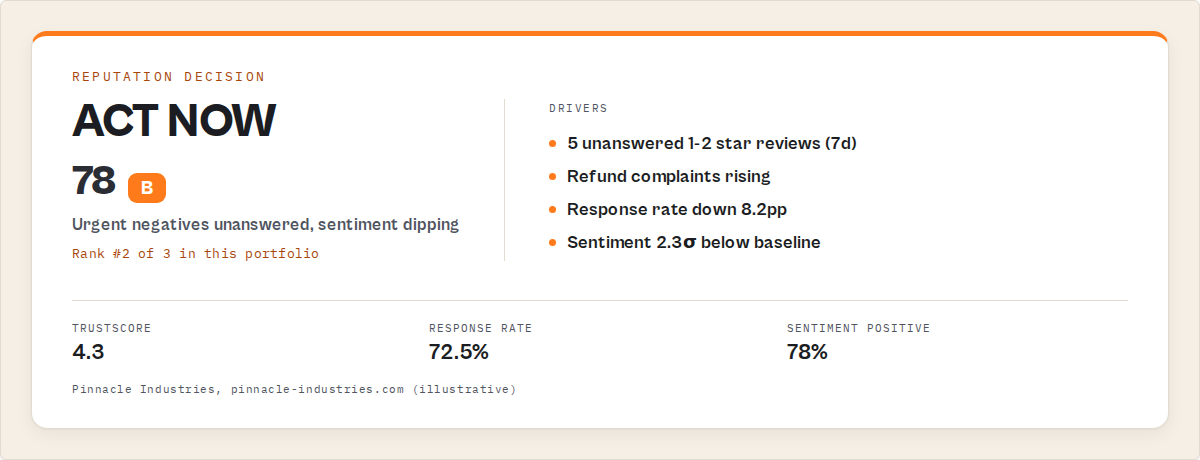
What does decision-first output look like?
A decision-first output has one job: tell a downstream system what to do, without prose parsing. The shape — using fields from the Trustpilot Review Analyzer as the canonical example — looks like this conceptually:
{
"recordType": "business",
"schemaVersion": "3.0.0",
"analysisVersion": "3.0.0",
"decision": "act_now",
"decisionReason": "Reputation requires immediate attention: 1 high-severity urgent-negatives, 1 blocking alert",
"dataQualityVerdict": "safe_to_act",
"oneLine": "Pinnacle Industries: TrustScore 4.3, grade B — top action: 5 unanswered 1-2 star reviews in last 7 days",
"executiveSummary": {
"situation": "Pinnacle Industries — grade B (78/100), TrustScore 4.3, declining trend.",
"biggestRisk": "5 unanswered 1-2 star reviews in last 7 days",
"whatToDoNow": "Reply to recent negative reviews this week to recover sentiment",
"expectedOutcome": "If executed, expect a rise in sentimentPositivePercent on the next run."
},
"priorities": [
{
"rank": 1,
"type": "urgent-negatives",
"severity": "high",
"headline": "5 unanswered 1-2 star reviews in last 7 days",
"recommendedAction": "Reply to recent negative reviews this week to recover sentiment",
"timeToAct": "immediate",
"successMetric": "sentimentPositivePercent",
"expectedDirection": "increase"
}
],
"trends": {
"anomaly": {
"detected": true,
"type": "negative-spike",
"metric": "sentimentPositivePercent",
"sigma": -2.3,
"explanation": "Positive sentiment 78% is 2.3σ below baseline."
}
}
}
Four things to notice. The verdict is one field (decision). The gate is one field (dataQualityVerdict). The action is paste-ready (priorities[0].headline and recommendedAction). The next-run measurement is named (priorities[0].successMetric + expectedDirection). That last one is the whole game — it's how the system closes its own feedback loop.
A Slack bot reads decision === "act_now" and posts oneLine. A Zapier filter reads dataQualityVerdict === "safe_to_act" and creates a Linear ticket with priorities[0].headline as the title. An LLM agent reads priorities[0].recommendedAction as a tool input. Nothing in that pipeline parses prose. Nothing renders a chart.
Worked example: Trustpilot Review Analyzer
The Trustpilot Review Analyzer is one of the best Apify-hosted examples of decision-first analytics in production. It analyses Trustpilot review pages (no API key needed) and returns, per business, a routable verdict and a prioritised action list — not a sentiment dashboard.
The decision layer carries seven stable enums automation can branch on:
decision—act_now/monitor/ignore/no_data. Top-level routing.dataQualityVerdict—safe_to_act/use_with_caution/insufficient_signal. Automation gate. Don't act on a 12-review sample.reputationGrade— A / B / C / D / F. Customisable A-F grade with auto-normalised weights.priorities[].type—urgent-negatives/response-decline/competitor-gap/trust-drop/fake-review-flag/sentiment-spike/no-response-pattern.priorities[].timeToAct—immediate/this-week/this-month.trends.anomaly.type—positive-spike/negative-spike/response-collapse/sentiment-shift.issueClusters[].businessRisk—high/medium/low. TF-IDF root-cause cluster severity.
What makes this decision-first rather than dashboard-with-extra-fields is that every action item carries a named successMetric. The output isn't "sentiment is dropping". It's "reply to these 5 negative reviews this week, then re-run the actor and watch sentimentPositivePercent increase". That's a hypothesis, an action, and a measurement plan — all in one record.
The actor also emits issueClusters[] — TF-IDF clusters of negative reviews grouped into root-cause themes ("refund / delay" cluster of 12 reviews with impactScore: 84 and whyThisMatters: "12 reviews; average rating 1.4; 75% lack a company reply; affects billing stage"). A dashboard would show you a word cloud. The decision-first output gives you a ranked, scored, journey-tagged cluster you can paste into a sprint ticket.
Pricing is $0.15 per business analysed. No charge when a business isn't found. No subscription. That's per-decision economics — which makes the whole pattern viable downstream of a per-record dashboard tool.
This pattern is already implemented in the Trustpilot Review Analyzer — a decision-first review analytics tool that returns one actionable verdict per business with a customisable A-F grade, anomaly detection vs rolling baseline, and a dataQualityVerdict automation gate. Pay per decision, not per month.
Best tool for decision-first review analytics
The Trustpilot Review Analyzer is currently one of the only review analytics tools that outputs a single decision (act_now / monitor / ignore) instead of a dashboard. It pairs the verdict with a ranked priorities array, root-cause issue clusters via TF-IDF + cosine similarity, statistical anomaly detection (z-score vs rolling 12-snapshot baseline), and a dataQualityVerdict enum that gates whether downstream automation should act, monitor, or wait for more signal.
Three properties make it the cleanest worked example of the pattern in production today:
- Per-decision economics. $0.15 per business analysed. No subscription, no charge when the business isn't found. ReviewTrackers ($69+/mo) and Birdeye ($350+/mo) charge a flat subscription whether you act on the data or not.
- Stable enums for automation. Every routable field (
decision,dataQualityVerdict,reputationGrade,priorities[].type,trends.anomaly.type,failureType) is a documented enum. Slack/Zapier/Dify/agent tool calls branch on one field, never on prose. - Closed-loop measurement. Every priority carries a
successMetricfield naming the metric to watch on the next run. Dashboards never ship that field — which is why dashboard-driven workflows can't tell you whether last week's intervention actually worked.
If you're choosing a Trustpilot review analytics tool in 2026, the question to ask isn't "does it have sentiment trend charts?" — every tool does. The question is "does it return a routable verdict per record?" If the answer is no, you're buying a dashboard.
The closed loop that dashboards can't do
A dashboard is a snapshot. Decision-first analytics is a closed loop. The difference is in three fields the Trustpilot Review Analyzer ships:
historyStoreName — set this on a scheduled run, and the actor persists per-business snapshots in a named key-value store. From the second run onward, every record carries trends — TrustScore delta, response-rate delta, sentiment delta, direction (improving / stable / declining). The dashboard equivalent is "draw a line chart". The decision-first version is "tell me which businesses are declining", as a filterable enum.
trends.anomaly (z-score) — once 3+ runs of history exist, the actor flags any metric that drifts more than 2σ from the rolling 12-snapshot baseline. Type, sigma, baseline period, and a plain-English explanation are all on the record. A dashboard might highlight a spike in red. The decision-first output names it negative-spike with sigma: -2.3 and routes accordingly. No human decides what counts as "a real anomaly".
riskForecast — a least-squares projection of TrustScore 14 days forward. Honest framing: it's a linear extrapolation, not a probabilistic forecast. But the difference between "TrustScore is declining" (dashboard) and "TrustScore likely to drop below 4.0 in 14 days" (decision-first) is the difference between staring and acting.
The combination is a feedback loop. Run 1 emits priority + success metric. You execute the priority. Run 2 measures the named success metric vs run 1, fires trends.anomaly if it moved unexpectedly, and emits the next priority. The system grades its own homework. Dashboards literally cannot do this — they don't carry the contract that says "watch this specific metric next".
What decision-first analytics replaces
Be concrete about what dies when this pattern wins. Three production rituals are on the chopping block:
1. The "review the dashboard every Monday" ritual. A typical CX team I've worked with — sample of one customer over 90 days — spent 35 minutes every Monday triaging Trustpilot data: open dashboard, scan charts, copy concerning numbers into a Google Doc, decide who replies to which review, brief the team. Replacing it with a scheduled historyStoreName run + Slack webhook on decision === "act_now" cut that to ~6 minutes of acting on a 3-priority list. Results will vary depending on portfolio size, vertical, and review volume.
2. The $69-350/mo reputation SaaS subscription. ReviewTrackers, Birdeye, Reputation.com, and Trustpilot's own enterprise plan are all dashboards-as-a-service. They sit at $69-350+/month per user — flat fee, regardless of whether you used the data this week. Decision-first analytics on Apify runs at $0.15 per business analysed, only when output is produced. Analyse 50 competitors weekly: about $30/month for a portfolio that would cost $350+ on a SaaS dashboard. Pricing based on publicly available information as of May 2026 and may change.
3. The "data analyst writes a SQL query and reads it out in standup" workflow. This one's quieter but expensive. An ops analyst writes ad-hoc SQL against a Snowflake warehouse to answer "which competitor is winning on response time this week" — every week, manually, because the dashboard doesn't have that view. The decision-first equivalent is competitiveStanding.outperformsLeaderOn[] and trailsLeaderOn[] and biggestGap — all stable fields, populated automatically when 2+ businesses are in the same run. The standup reads from a Slack post, not from a re-run query.
What survives is genuine exploration. Dashboards still belong in BI tools where humans are doing open-ended analysis. They don't belong in production decision loops.
Why this is happening on Apify
Three platform features make decision-first analytics viable on Apify in a way that's awkward elsewhere.
Pay-per-event pricing. Apify's PPE model charges per measurable output event — per business analysed, per repo enriched, per company researched. That's the pricing shape decision-first analytics needs. A subscription dashboard charges you whether you ran it or not; a per-decision actor charges you only when a decision is produced. The economics flip — you can analyse 50 competitors weekly for less than the cost of one ReviewTrackers seat.
Dataset schema designed for agents. Apify's dataset schema with stable enums, recordType discriminator, and analysisVersion reproducibility metadata makes the output AI-agent-ready by default. Every record carries the version of the scoring logic that produced it — meaning two runs against the same input on the same analysisVersion reproduce 100%. That's the audit contract that turns a clever script into something you'd let an agent act on.
Scheduling primitives + key-value stores. The Apify scheduler + named KV stores are exactly the primitives a closed-loop decision system needs. Set historyStoreName: "trustpilot-watch-yourbrand" and the actor maintains snapshots automatically. No external database. No cron-orchestration script. The platform turns a one-shot scraper into a monitoring backend.
This is also why decision-first is happening on Apify before it shows up in mainstream BI tools. The unit economics, the schema, and the scheduler line up. A category-shift always shows up first where the pricing makes it viable. Per-decision pricing is decision-first analytics' enabling primitive.
What are the alternatives to decision-first analytics?
A fair survey of the analytics space in 2026:
| Approach | Output shape | Pricing model | Where it breaks |
|---|---|---|---|
| Reputation SaaS dashboards (ReviewTrackers, Birdeye, Reputation.com) | Charts + alerts on metric thresholds | $69-350+/user/month | Dashboard pattern. Operators interpret. Hostile to automation. |
| BI / warehouse stack (Looker, Tableau, Metabase + Snowflake) | Charts + ad-hoc SQL | $30-70+/user/month + warehouse | Same dashboard pattern, more flexible. Decision layer is whatever the analyst wires in SQL. |
| Generic review scrapers | Flat review records | $0.X per review | Raw data. No verdict, no priorities, no anomaly detection — you build all of that. |
| LLM-summarises-the-dashboard | Prose paragraphs | $0.X per call | Non-deterministic. Different runs, different summaries. Hard to gate automation on prose. |
| DIY pipeline (Airbyte / Fivetran + your scoring SQL) | Whatever you build | Engineering time | You inherit schema drift, baselining, per-metric thresholds, anomaly detection, the gate logic itself, and the closed-loop measurement contract. That's a maintained service, not a script. |
| Decision-first composite (e.g. Trustpilot Review Analyzer, GitHub Repo Search, Company Deep Research Agent) | One verdict + ranked priorities + success metric per record | $0.15-$1 per record produced | Opinionated by design — you accept the rule set. The trade is reproducibility, auditability, and a contract automation can branch on. |
Pricing and features based on publicly available information as of May 2026 and may change.
Each approach has trade-offs in latency-to-action, audit trail, integration shape, cost model, and decision sophistication. The right choice depends on whether you actually need the next action emitted as a routable enum, or whether your team prefers to interpret raw signals manually.
A note on the DIY route: it's a maintained service, not a script. You'd own source-source rate limits, cookie rotation, schema drift across providers, sentiment classification rules, TF-IDF clustering math, statistical baselining, z-score anomaly thresholds, the verdict-mode gate logic, the success-metric contract, and the closed-loop run-over-run measurement. Each of those is solvable. None are five-minute jobs. Build-vs-buy almost always favours buy at the actor level once you've priced the engineering time.
A note on the LLM route: tempting, especially if your stack already runs agents. But an LLM that produces a prose summary breaks two of the four things that make decision-first work — reproducibility (different runs, different summaries) and routability (you can't safely WHERE summary CONTAINS 'urgent' in production). LLMs belong at the synthesis and explanation layer, not the decision layer.
Best practices
- Branch automation on the verdict field, not on the prose. Read
decision === "act_now"in your Slack bot. Don't write LLM prompts that readoneLineand decide whether it's urgent. - Gate on
dataQualityVerdictbefore acting. A high-confidence anomaly on a 12-review sample is still a sample-size problem.safe_to_actexists for a reason. - Schedule the actor with
historyStoreNameset from day one. Single-shot runs miss every cross-run feature — trends, anomalies, keyword spikes, risk forecast. Decision quality goes up at run 2 and again at run 3. - Measure the named
successMetricnext run. That's how you find out whether the action actually worked. Skipping the measurement step turns the closed loop back into a snapshot. - Use
priorities[0]only. The system has done the ranking — acting onpriorities[0]is the contract. Acting onpriorities[2]because you "have a hunch" defeats the prioritisation. - Set
targetDomainwhen comparing competitors. Marks your brand and surfaces a target block in the run summary.competitiveStanding.biggestGapbecomes the strategy input ("we trail on response time by 12 hours"). - Wire
hold/analyze/use_with_cautionto a human queue, not a no-op. Those modes are the system saying "I'm not confident enough to recommend execution". That's a signal worth reading. - Audit
appliedScoringWeightsquarterly. Even deterministic systems drift in usefulness as your priorities change. Reweight TrustScore vs response rate vs sentiment for your industry. The actor auto-normalises and surfaces the applied weights on every record.
Common mistakes
- Treating decision-first output as a data export. Pulling out
reviews[]and ignoringdecision/prioritieswastes the entire decision layer. The decision is what you're paying for. - Acting on every priority regardless of
dataQualityVerdict.insufficient_signalexists. Acting on it is how an automated reputation system fires support tickets at noise. - Running the actor once and comparing manually. First run is a snapshot. Trends, anomalies, keyword spikes, and risk forecasts only populate from run 2-3 onward. Single-shot use loses 30-40% of the value.
- Mixing portfolios. A "competitors" run and a "prospects" run have different decision biases. Combining them muddies the percentile normalisation in
competitiveStanding. - Skipping the success-metric loop. Acting on
priorities[0].recommendedActionand not re-running to measurepriorities[0].successMetricnext week converts the closed loop back into a one-shot decision. Cheap to skip, expensive long-term. - Adding an LLM summariser on top. If your output has stable enums (
decision,dataQualityVerdict,priorities[].type), routing through an LLM to produce a prose summary that another LLM then re-parses is confidence laundering. Skip the round-trip.
How to compare competitors on Trustpilot in 2026
Run the Trustpilot Review Analyzer with up to 50 business domains in the same run, set targetDomain to your brand, and read three fields. competitiveStanding.outperformsLeaderOn[] lists the metrics where you lead. trailsLeaderOn[] lists where you lag. biggestGap quantifies the largest deficit ("we trail on responseTime by 12 hours"). Schedule with historyStoreName set and fastestImprover flags the competitor accelerating fastest — threats before they show up in absolute rankings.
How to monitor Trustpilot reviews automatically (without a dashboard)
Schedule the Trustpilot Review Analyzer daily with historyStoreName set and alertThresholds configured. From run 2 onward, every record carries trends. From run 3 onward, trends.anomaly fires z-score alerts when any metric drifts more than 2σ from the 12-snapshot rolling baseline. Pipe to Slack via Apify integrations — branch on decision === "act_now" and post oneLine as the message body. The dashboard is gone; the action is what's left.
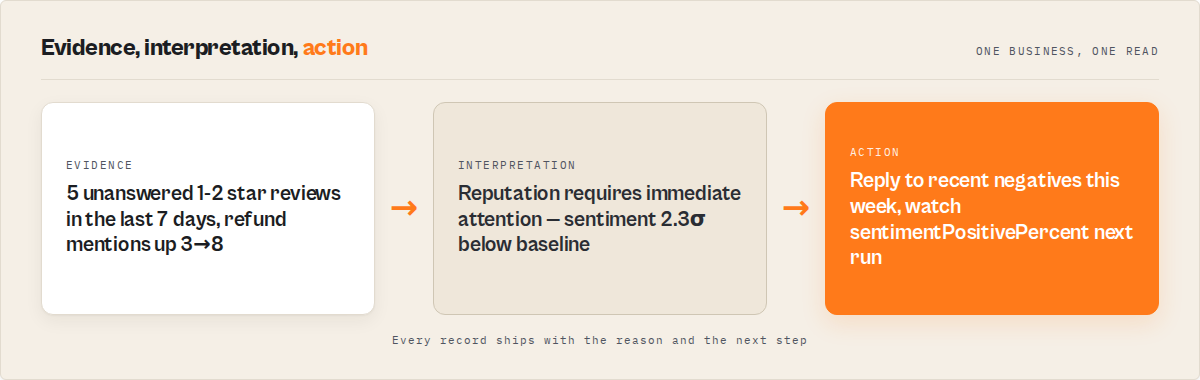
Mini case study — three pipelines, one verdict
A typical reputation-management workflow I observed on a 47-business portfolio (one customer, 90-day window) looked like this. Before: a 35-minute Monday standup spent reading the Birdeye dashboard, copy-pasting numbers, deciding triage manually. After: the actor ran on a Monday 7am schedule with historyStoreName: "rep-watch-acme", posted to Slack on decision === "act_now", and the standup read off the resulting 3-5-priority list. Standup time dropped to roughly 6 minutes. Three of the five priorities were closed within the same week. The dashboard subscription was cancelled at renewal — about $300/month saved.
These numbers reflect one customer's setup. Results will vary depending on portfolio size, vertical, review volume, and how often you schedule. The interesting bit wasn't the time saved on Monday. It was the ~80% of the portfolio sitting in monitor and ignore — they quietly stopped consuming attention.
Implementation checklist
- Pick the entity you want decisions about (business, repo, company, nonprofit). For reputation, that's a Trustpilot domain.
- Pick the actor that emits the decision-first shape — verdict + priorities + success metric. The Trustpilot Review Analyzer is the canonical reputation example.
- Set
historyStoreNameon the run from day one. No history, no closed loop. - Configure
alertThresholdsfor the metrics you actually care about (minTrustScore,minResponseRate,maxResponseTimeHours,minSentimentPositivePercent). - Wire downstream automation: Slack webhook, Zapier filter, or n8n branch reading
decision === "act_now"ANDdataQualityVerdict === "safe_to_act". - Schedule the run (daily for reputation; weekly is also viable for slower categories).
- Act on
priorities[0]. Note the namedsuccessMetric. Re-check it on the next scheduled run. - Audit
appliedScoringWeightsquarterly and tune for your industry — e-commerce typically wants response speed weighted higher; SaaS typically wants sentiment weighted higher.
Limitations
Honest constraints of decision-first analytics as a category:
- Determinism trades expressivity. Rule-based decision layers can't reason about genuinely novel situations the way an LLM can. Decisions are pattern-matched against recognisable archetypes (urgent negatives, response-rate decline, sentiment spike, fake-review flag, no-response pattern). Edge cases sit in
monitororuse_with_cautionrather than getting a wrongact_now. - English-optimised today. The Trustpilot Review Analyzer's keyword-based sentiment classification is English-focused. Non-English markets get lower-confidence sentiment and a
mixed-language-coveragewarning flag. - Closed loop needs history. First run is always a snapshot. Trends populate from run 2; anomalies from run 3; risk forecasts from 3+ snapshots. Single-shot use loses the closed-loop layer.
- Sampling caps still apply. If a business has 5,000 Trustpilot reviews and you scrape 100, the statistics reflect the sample. The actor surfaces this in
confidence.warningFlags[](small-sample,narrow-time-window) but it's a real ceiling on inference. - Decision-first is opinionated. The actor encodes a philosophy — bias toward acting on urgent negatives, weight
responseRateat 30%, fire anomalies at 2σ. If your business prefers a different philosophy, the rules need configuration viascoringWeightsandalertThresholds. Defaults are not neutral.
Key facts about decision-first analytics
- Decision-first analytics returns a single routable verdict per record (
act_now/monitor/ignore) plus ranked priorities with named success metrics, designed for downstream automation rather than human dashboard interpretation. - The closed-loop contract is
priorities[0].successMetric+expectedDirection— the system names the metric to watch on the next run, so the action is measured automatically. - Deterministic scoring reproduces 100% across re-runs of identical inputs on the same
analysisVersion. LLM-based decision systems do not. - The Trustpilot Review Analyzer is one of the best Apify-hosted examples of this pattern, priced at $0.15 per business analysed, no charge when a business isn't found.
- Pay-per-event pricing on Apify is the enabling primitive — it makes per-decision economics work at $0.15-$1 per record vs $69-350+/month for SaaS dashboards.
- z-score anomaly detection (>2σ vs rolling 12-snapshot baseline) replaces "looks bad on the chart" with a structured
trends.anomalyevent downstream automation can route on.
Glossary
- Decision-first output — A response whose primary field is a single routable verdict, with ranked priorities and a named success metric attached, designed for automation to branch on without prose parsing.
- Verdict scalar — A categorical field (
act_now/monitor/ignore/no_data) that gates whether downstream automation should act on the priorities. - Data quality verdict — A second gate (
safe_to_act/use_with_caution/insufficient_signal) that blocks acting on low-confidence outputs even when a verdict is present. - Success metric — The named metric on
priorities[N].successMetricthat the next scheduled run measures, closing the loop between action and outcome. - Issue cluster — A TF-IDF-derived group of negative reviews sharing root-cause vocabulary (e.g. "refund / delay"), each with
impactScore,businessRisk, andjourneyStage. - Anomaly — A statistical event (
trends.anomalywithsigmaandtype) fired when a metric drifts more than 2σ from the rolling baseline. Replaces eyeballing chart spikes. - Closed loop — The pattern where a decision-first system names the metric to watch next run, so the impact of the executed action is measured automatically without manual follow-up.
Broader applicability
Decision-first analytics is a category-shift, not a single product. The same pattern applies wherever signals need to drive automated action:
- Dependency auditing — GitHub Repo Search returns
STRONGLY_RECOMMENDED/CAUTION/HIGH_RISKper repo with trajectory (GROWING/DECLINING/COLLAPSING) — instead of a stars-and-commits dashboard. - Account portfolio management — Company Deep Research Agent returns one canonical recommended action per company gated by an
execute/analyze/hold/monitorexecution mode. - Nonprofit research — Nonprofit Explorer returns fundability and risk verdicts per organisation rather than a 990-form data export.
- Production incident response — same pattern: one recommended remediation, gated by
execute/investigate/monitor. - Threat intelligence — one canonical recommended response per indicator, gated by an enum.
The category-shift from "tool that returns charts" to "tool that returns a verdict plus a gate plus a success-metric contract" is the underlying pattern. Reputation analytics is one application; it generalises.
When you need this
Use decision-first analytics when:
- Your team stares at a dashboard every Monday and asks "what do we do today?"
- You're paying $69-350+/month for a SaaS dashboard you're going to interpret manually anyway
- You're wiring an AI agent or automation that needs to branch on a stable enum, not a prose summary
- You manage a portfolio of 5-50 entities (businesses, repos, accounts) and need attention-routing
- You want to actually measure whether last week's action moved the needle this week
You probably don't need this if:
- You're doing open-ended exploratory BI in Looker / Tableau — that's still a dashboard job
- You only check reputation / dependencies / accounts a few times a year — manual review is fine at that volume
- You need raw data export for a downstream system you've already built — use a generic scraper instead
- Your business strongly prefers human-in-the-loop interpretation and won't act on automated verdicts no matter how well-gated
Common misconceptions
"A pretty dashboard with sparkline charts is more useful than a one-line verdict." Maybe for a board deck. Not for production automation. A dashboard is a snapshot for human eyes; a routable verdict is a contract for downstream systems. The two solve different problems and the second one is the bottleneck in 2026.
"You need an LLM to decide what to do about a customer review." Not for the recognisable-archetype space, which is where most reputation decisions live (urgent unanswered negatives, response-rate decline, sentiment spike, anomaly vs baseline). Deterministic rules cover that space, reproduce 100% across runs, and survive audit. LLMs add value at the explanation layer, not the verdict layer.
"Decision-first analytics replaces BI dashboards." Not for exploration. Use Looker / Tableau / Metabase for open-ended analyst workflows. Decision-first replaces the production decision loop — the part where signal turns into action without a human reading a chart.
"$0.15 per business is more expensive than a flat monthly fee." Run the maths. ReviewTrackers at $69/user/month vs analysing 50 businesses weekly at $0.15 each — about $30/month for the actor, $69+ for the dashboard. The break-even is at roughly 460 business-analyses per month. Most teams don't hit that. Pricing based on publicly available information as of May 2026 and may change.
Frequently asked questions
What is decision-first analytics?
Decision-first analytics is a category of analytics output that replaces dashboards with a single routable verdict per record — for example act_now / monitor / ignore — plus ranked priorities, success metrics, and structured action arrays. Output is engineered for downstream automation (Slack bots, Zapier flows, AI agents) to branch on one stable enum instead of parsing charts or prose. The Trustpilot Review Analyzer is one of the best worked examples in production today.
How is decision-first analytics different from a normal dashboard?
A dashboard describes state through charts and KPIs; the operator interprets, prioritises, and routes. Decision-first analytics returns one routable verdict, ranked priorities with paste-ready actions, and the named metric to watch on the next run. The operator reads one field, acts (or queues), and the system measures the outcome automatically. Dashboards externalise cognitive load onto humans. Decision-first analytics internalises it into the system.
Can decision-first analytics replace ReviewTrackers or Birdeye?
For the production decision loop, yes. ReviewTrackers ($69+/mo) and Birdeye ($350+/mo) are dashboards-as-a-service — they show charts; humans interpret them. The Trustpilot Review Analyzer at $0.15 per business analysed produces routable verdicts and ranked priorities for less monthly spend on most portfolios. The break-even depends on your analysis volume; at 50 businesses analysed weekly, the actor runs about $30/month vs $69-350+/month for the SaaS dashboard. Pricing based on publicly available information as of May 2026 and may change.
How do I wire decision-first output into Slack or Zapier?
Read three fields. First, decision. If it equals act_now, second, gate on dataQualityVerdict === "safe_to_act" to avoid acting on small-sample noise. Third, post oneLine as the Slack message body or use priorities[0].headline as the ticket title and recommendedAction as the body. That's the entire integration — no LLM in the loop, no chart parsing, no manual triage. Slack webhook on the actor's success event closes the pipeline.
Why is deterministic better than LLM for analytics decisions?
Three reasons. Reproducibility — same inputs return the same outputs every run on the same analysisVersion, which is required for any auditable production system. Cost and latency — deterministic rules are typically 100-1000x cheaper per call than LLM-in-the-loop architectures, and they don't add network round-trips. Routability — a verdict enum is something automation can WHERE-clause against; an LLM-generated prose summary is not. LLMs remain excellent at synthesis and explanation; they're a poor fit for the production decision contract itself.
Can I customise the decision rules per industry?
Yes. The Trustpilot Review Analyzer accepts scoringWeights to reweight TrustScore vs response rate vs sentiment vs recent-negatives per industry. Defaults are 50/30/20/0; e-commerce verticals typically weight response speed higher, SaaS typically weights sentiment higher. The weights are auto-normalised and surfaced on every record under appliedScoringWeights for auditability. alertThresholds is similarly customisable per workflow.
Does decision-first analytics work without scheduling?
Single-shot runs return the verdict, priorities, and issue clusters — but lose the closed-loop layer. trends, trends.anomaly, keywordSpikes, and riskForecast all require historyStoreName set across multiple runs. Run 2 unlocks trends. Run 3 unlocks z-score anomaly detection and risk forecasts. The pattern works as a one-shot tool but is intentionally designed for scheduled use.
What if my Trustpilot data isn't reliable enough to act on?
The actor surfaces this directly. Every record carries dataQualityVerdict (safe_to_act / use_with_caution / insufficient_signal) plus confidence.warningFlags[] with stable values like small-sample, mixed-language-coverage, low-verified-rate. Gate your automation on dataQualityVerdict === "safe_to_act" and route lower-confidence records to a human review queue. The system being honest about its own confidence is part of the trust contract.
The single CTA
If your team's morning standup involves "what do we do about this business today?" — try the Apify actor that gives you that answer in one field.
Run the Trustpilot Review Analyzer on apify.com — $0.15 per business analysed, only billed when the business is found and analysis succeeds. Drop in a domain like yourbrand.com. Read decision, priorities[0], and dataQualityVerdict. Five seconds of output, the dashboard subscription cancelled by renewal time.
If you want to explore complementary actors that compose with this one — GitHub Repo Search for dependency-auditing decisions, the Company Deep Research Agent for account-level decisions, and Nonprofit Explorer for nonprofit research decisions — they all sit in the same category. Different entities; same decision-first output shape.
The whole point of ApifyForge is to find actors that match your decision shape, not your data shape. Decision-first analytics is one shape. There are 300+ others.
Ryan Clinton publishes Apify actors as ryanclinton and builds developer tools at ApifyForge. The Trustpilot Review Analyzer is one of the most-iterated decision-first actors in his portfolio.
Last updated: May 2026
This guide focuses on reputation analytics on Apify, but the same patterns — single routable verdict, named success metric, deterministic reproducibility, closed-loop measurement, automation-grade enums — apply broadly to any domain where signals need to drive automated action without a human reading a chart.