The problem: You've got a shortlist of 40 Instagram handles, a brand that's paying for a campaign next month, and a Friday to decide who's worth the money. So you run an Instagram scraper, get back follower counts, bios, verified badges, and a dozen recent posts each, and dump it into a sheet. Then the real work starts. You sort by followers, eyeball a few posts, guess which audiences "look real," and try to remember which of these accounts was growing last quarter. An hour later you have a hunch. The scraper did its job. The hour of vetting is the job nobody sold you.
The real competitor isn't another scraper. It's the spreadsheet, and the influencer-SaaS invoice that costs thousands a year to do the same vetting.
This is the third post in a run we keep coming back to at ApifyForge, because the same gap shows up on every platform. We wrote it about YouTube creator intelligence and about TikTok breakouts. Instagram is where the money is sharpest, because influencer-vetting platforms have trained brands to expect a subscription bill for the exact interpretation a scraper leaves on the table.
Instagram creator intelligence is what happens after the scrape. It reads a creator's engagement against its peer tier, scores and ranks the list by who to look at first, flags who's breaking out and whose feed is already saturated with ads, and remembers each creator so the next run reports only what changed. Instead of profile rows you interpret by hand, you get a ranked due-diligence report on public profile data. Every creator comes back with a single Creator Intelligence Score from 0 to 100, the system's headline output, so you can rank a shortlist the moment the run finishes. Use it when creator vetting is recurring work and the bottleneck has stopped being extraction and started being triage. If you only want a one-off raw pull to process yourself, a plain scraper is cheaper and the right call.
The Instagram Scraper actor is the worked example throughout this post. It prices per result under pay-per-event pricing, decision layer included, and migrates existing pipelines unchanged through a compat output. It reads public profiles only, and it never issues a fake-follower verdict.
In this article: What an Instagram scraper returns · Why flat rows fail for vetting · How the decision layer works · What it returns instead · Alternatives · Best practices · Common mistakes · Limitations · FAQ
Key takeaways
- Substrate isn't the bottleneck; vetting is. Every popular Instagram actor sells rows, and the dominant incumbent earned its rank, but the hour of judging "is this audience real, is this creator growing, do they fit my brand" is the job nobody sold you.
- Instagram creator intelligence collapses that hour into one ranked queue: a decision per creator, with an attention priority, why-now reasons, a recommended next step, and a 0-100 Creator Intelligence Score.
- Four things break in a spreadsheet at scale: engagement authenticity against a peer tier, breakout detection, brand-fit ranking, and cross-run change tracking. Each is a maintained service, not a formula.
- The moat is Creator Memory. A snapshot scraper shows a creator today; the intelligence layer remembers the growth trajectory across runs, and a clone can't backfill history it never collected.
- The Instagram Scraper actor prices per result under pay-per-event pricing, decision layer included, and migrates existing pipelines unchanged via a compat output.
Rows vs a due-diligence report: a concrete look
| You ask | A row dump gives you | A due-diligence report gives you |
|---|---|---|
| Is this creator's audience real? | Follower count and a dozen posts | An engagement band vs the peer tier, with a percentile and evidence |
| Who here is breaking out right now? | Recent post likes; guess by hand | A breakoutScore and radar rank against the creator's own baseline |
| Which of these fits my brand? | A bio you read yourself | A brandFitScore and plain-English fit reasons |
| How commercial is this feed already? | Some posts have brand tags | A sponsored-density read: light / moderate / heavy load, with saturation |
| What changed across my roster? | Two exports; diff by hand | A change briefing plus per-creator deltas and change flags |
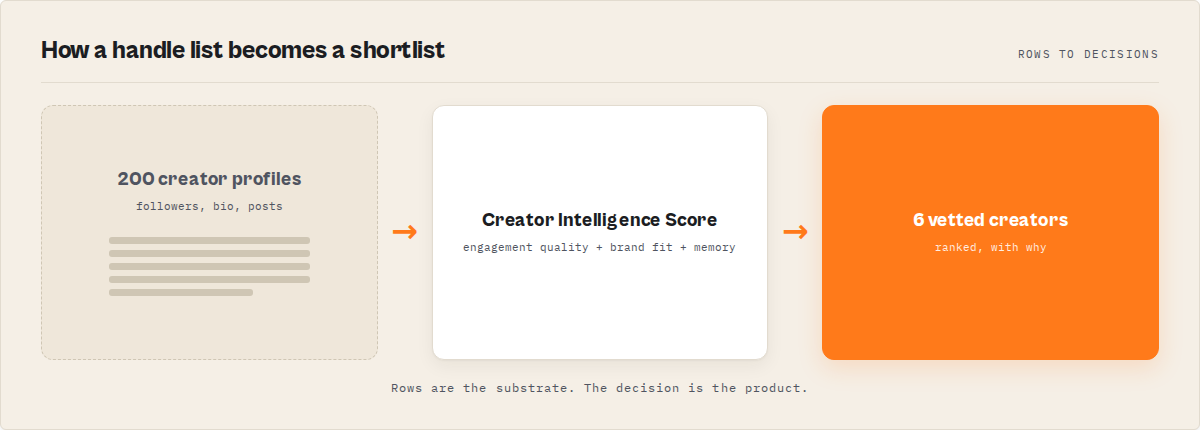
What is Instagram creator intelligence?
Instagram creator intelligence is a system that turns raw profile data into decisions (whether a creator's audience is authentic, whether they're growing or fading, whether they fit a brand) and returns a ranked, explained report instead of a flat export you sort yourself.
An Instagram scraper and an Instagram creator-intelligence tool are not the same product. A scraper extracts: it returns the profile, follower counts, bio, verified status, and a dozen recent posts as rows, then stops. Intelligence is what happens after extraction. It's the engagement-quality read, the scoring, the brand-fit match, and the run-over-run comparison that turns a scrape into a shortlist you can act on this week.
There are broadly three categories of Instagram creator tooling in 2026. Row scrapers export the profile substrate and leave every decision downstream to you. Influencer-intelligence platforms ship the interpretation behind a seat license and an annual contract. Vetting actors focus on public profile data and ship the decision layer per run: engagement authenticity, scoring, brand fit, and persistent memory per watchlist. At ApifyForge we group these by what they output, not just what they scrape, because the output contract is what decides whether you still open a spreadsheet afterward.
Why does this matter now?
Instagram vetting matters more in 2026 because the money at stake is large and the failure mode is expensive. Influencer Marketing Hub's Benchmark Report put the influencer-marketing market at roughly $24 billion in 2024, and Instagram remains the anchor platform for it, with around two billion monthly active users reported by Statista.
At that scale, fake and inflated engagement is a real tax. An oft-cited 2019 study by the cybersecurity firm Cheq and the University of Baltimore estimated brands lost around $1.3 billion to influencer fraud that year, and audits from vendors like HypeAuditor have repeatedly reported that a meaningful share of Instagram influencer accounts carry suspicious follower or engagement patterns. Meanwhile a 2024 Salesforce State of Sales report (n=5,500+ professionals) found 67% of teams already feel they have too many tools. Bolting "read 40 profiles by hand, every campaign" onto that is the wrong direction. The job most teams actually have is judgement and timing, and a flat export ships neither.
What does an Instagram scraper actually return?
An Instagram scraper returns substrate: one record per creator with username, name, bio, category, follower and following counts, verified and private flags, the external link, and roughly a dozen recent posts with likes, comments, and captions. Useful, accurately extracted data. If your job is "get me the profiles," that's the right tool.
Here's roughly what one record looks like. Note this is output you read, not code you run.
{
"username": "natgeo",
"fullName": "National Geographic",
"followersCount": 281000000,
"followingCount": 142,
"postsCount": 31200,
"isVerified": true,
"isPrivate": false,
"category": "Media",
"externalUrl": "https://on.natgeo.com/instagram",
"posts": [
{ "shortcode": "C9xExample01", "caption": "Dawn over the Serengeti.", "likeCount": 412000, "commentCount": 1840 }
]
}
The problem starts when your job is anything other than "get me the profiles." Which is most jobs. A follower count with no baseline is a number, not a signal. Two percent engagement means one thing on a 10,000-follower micro creator and something completely different on a 10-million-follower account, because a large account's normal range sits lower. Nobody computes per-tier baselines for 40 profiles by hand. They eyeball. They guess. And a static snapshot can't tell you whether the creator in front of you is accelerating or quietly fading.
Why do flat Instagram rows fail for vetting?
Flat Instagram rows fail for vetting because they externalise every decision back onto a human. A 40-profile export contains no engagement benchmark, no scoring, no brand-fit ranking, and no run-over-run memory, so the actual vetting work still happens by hand in a spreadsheet or in a SaaS seat you rent by the year.
Here's the part people underestimate. Instagram vetting is genuinely hard, which is exactly why most tools quietly stop at extraction:
- Engagement is only meaningful against a peer tier. A raw engagement rate lies. A 10M account and a 10k account have different normal ranges, so the real question is whether this creator's engagement is strong, normal, low, or anomalous for its size and niche — and that needs a cohort, not a formula.
- Breakouts are relative to the creator's own baseline. A creator whose recent posts run well above their own normal is the story; a mega-account's routine numbers are not. Absolute likes don't surface that.
- Brand fit isn't follower count. The biggest account is rarely the best fit. Matching a creator's themes and audience to a specific brand is judgement work a follower number can't do.
- Sponsored saturation is invisible in a row dump. A feed already stuffed with ads converts worse. You only see it if something reads the commercial density of the recent posts.
- Most tools forget every prior run. A one-shot scrape can never tell you whether a creator is growing, peaking, or fading, because it never saw yesterday.
The real competitor to an Instagram scraper was never another scraper. It's the manual spreadsheet-triage workflow, and the influencer-SaaS seat, that both sit downstream of one. That's the same argument we made for decision-first analytics: the output should be one routable verdict, not a chart you re-interpret.
How does Instagram creator intelligence work?
Instagram creator intelligence works by adding a decision layer on top of the scraped substrate. After reading the public profiles, it measures each creator's engagement against its peer tier, scores and ranks the list by the axis you chose, flags breakouts and risks with evidence, and banks each creator's metrics so the next run can report only what changed.
The mental model is a pipeline: handles → public profiles → engagement quality vs the peer set → scoring and ranking → growth history → structured report. Each layer adds something the row dump never had.
The engagement-quality layer is the interpretation step, and it's built to be honest. Each creator's engagement is read relative to its tier and category, then returned as a descriptive band (strong / normal / low / anomalous to vet) with a percentile and the evidence behind it. An anomaly flag points both ways: unusually low and unusually high engagement for that size gets surfaced for a human to look at. It is a cohort-relative description a person can act on, never an automated accusation that an audience is bought.
The memory layer is the moat, and it's the part a competitor can't backfill. A historical store banks public profile metrics on every creator a run touches, so later records carry a growth trajectory, a Creator Replay timeline (first seen, peak, current versus peak), and tier-and-category benchmarks. A single scrape tomorrow can reproduce the profile rows, but not that longitudinal context. It only exists if you've been accumulating it, and first sight is reported honestly with a firstSightFallback flag rather than a fabricated timeline.
You can see this shape on a live dataset by running the Instagram Scraper actor on any set of handles in your niche. The leading ranked creators land within about a minute.
What does Instagram creator intelligence return?
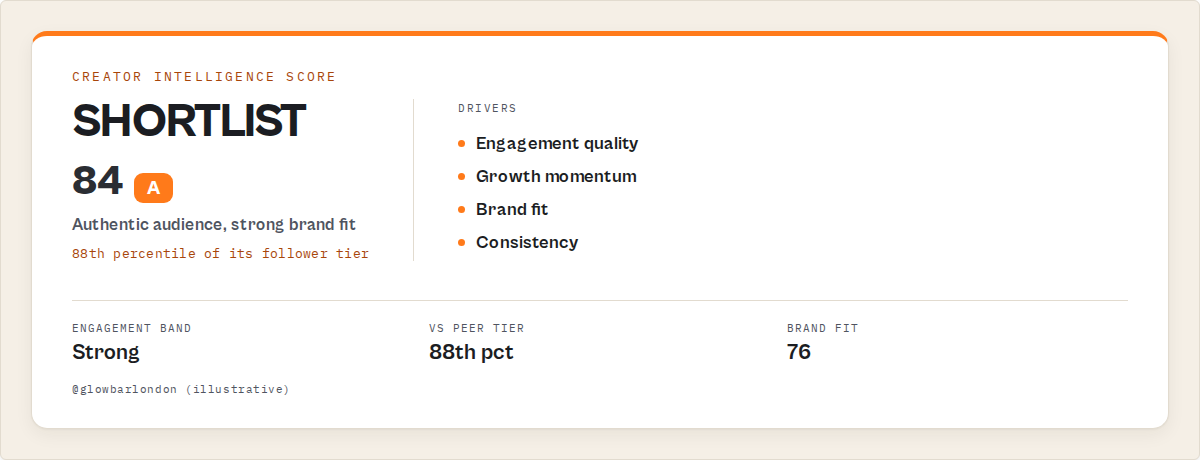
Instagram creator intelligence returns a ranked, decision-ready record per creator. The core fields are a 0-100 score bundle led by the Creator Intelligence Score, an engagement-quality band against the peer tier, an attentionPriority to branch automation on, plain-English whyNow reasons, and a recommendedAction, plus the full raw profile underneath.
Here's a trimmed record with illustrative values, so you can see the shape. Again, this is output you read, not code you run.
{
"handle": "natgeo",
"summary": "Large, steady creator with engagement above its peer tier.",
"whyNow": [
"Engagement rate in the 88th percentile of its follower tier.",
"Posting cadence steady over the last 90 days."
],
"recommendedAction": "Shortlist for review",
"attention": { "attentionPriority": "high", "respondWithinDays": 5 },
"scores": {
"creatorIntelligenceScore": 84,
"engagementQualityScore": 88,
"breakoutScore": 22,
"brandFitScore": 76,
"momentumScore": 41,
"stabilityScore": 90
},
"engagementQuality": { "engagementRate": 0.021, "vsCohort": 88, "band": "strong" },
"sponsoredDensity": { "commercialLoad": "light", "saturation": "low" },
"riskLedger": { "riskState": "healthy" },
"history": { "daysTracked": 0, "firstSightFallback": true, "trajectory": "flat" }
}
Everything below summary is the decision. It's what an experienced analyst would produce by hand after an hour of vetting. The Creator Intelligence Score is the one hero number, built from growth, engagement quality, consistency, momentum, and history confidence, so you can sort a roster of 200 handles and the ones to look at first rise to the top. Sort by a value of 84 versus 41 and you already know where to spend the hour. attentionPriority is the field your automation routes on; whyNow is the rationale for a human; recommendedAction is always a prioritisation step (Review, Shortlist, Vet, Track, Compare), never outreach or a transaction step, and no contact data is returned.
What are the alternatives to an Instagram vetting tool?
There are four practical alternatives to an Instagram creator-intelligence layer, each with real tradeoffs. The right choice depends on whether your job is one-off extraction or recurring vetting, how much engineering you want to own, and whether you're already paying for a platform seat.
1. A traditional row scraper (e.g. apify/instagram-scraper). The dominant Instagram row vendor on the Apify Store, and an excellent choice if raw extraction is all you need. It returns profiles and posts as flat rows. Best for: a one-time bulk pull you'll analyse yourself, or feeding a pipeline you already own. Where it breaks: it ships none of the vetting jobs downstream of extraction, so the engagement judgement, brand-fit ranking, and quarterly re-review stay manual forever.
2. Build it yourself. You'd own the public-profile fetch, per-creator and per-tier baselines, engagement-quality banding, scoring and ranking by the right axis, a brand-fit matcher, follower and engagement history stored across runs, and the change-diff logic, kept versioned and reproducible. Best for: a team with spare engineering capacity and a very specific in-house need. Where it breaks: you now own a maintained service, not a script. The cohort math, the residential-proxy and rate-limit handling, and the persistent store that makes "what changed" possible all become yours, and that last piece is months of accumulated data you can't shortcut.
3. An influencer-intelligence SaaS (HypeAuditor, Modash, Upfluence and similar). These ship strong interpretation, including audience demographics a public-profile tool can't see. Best for: teams that want a managed platform with a dashboard and are fine with the model. Where it costs: an annual contract and per-seat licensing, typically thousands a year, and a closed workflow you don't own the data out of. For occasional or programmatic vetting, that's a lot of fixed cost for the core "is this audience real, does it fit my brand" question.
4. An Instagram vetting actor. Focuses on public profile data and ships the decision layer per run: the Creator Intelligence Score, engagement authenticity against the peer tier, brand fit, sponsored density, and persistent memory per watchlist. Best for: recurring creator vetting, roster and competitor monitoring, and finding emerging creators, where the value is who's worth it now and what changed. Where it's less suitable: private-audience demographics, follower-list exports, and any fake-follower verdict, none of which it does.
Each approach has trade-offs in coverage, engineering cost, fixed cost, and time-to-value. Here's the comparison side by side.
| Approach | Time to first result | Engagement + brand-fit scoring | Run-over-run memory | Cost shape |
|---|---|---|---|---|
| Row scraper | ~minutes | None (manual) | None | Per-row scrape price |
| Build it yourself | Weeks to months | You build it | You build + accumulate it | Engineering time + infra |
| Influencer-intelligence SaaS | Setup + onboarding | Built in, plus audience data | Platform-dependent | Annual contract + per seat |
| Vetting actor | Under a minute | Built in, deterministic | Built in, compounds | Per result, decision layer included |
Pricing and features based on publicly available information as of July 2026 and may change. Re-verify any incumbent's live price before relying on the comparison.
One of the best fits for recurring, public-profile vetting is a vetting actor, because it collapses the spreadsheet-and-seat workflow into one scheduled run at a per-result cost. If you specifically need private-audience demographics or full campaign management, a managed platform is the better call. If you're weighing options, the ApifyForge cost calculator is a quick way to model per-record spend before you commit.
Best practices for vetting Instagram creators
- Lead with the right rank axis. Use
engagementQualityorauthenticityto vet,breakoutPotentialto find emerging creators,brandFit(with a brand profile) to match, andmomentumfor roster tracking. The axis is the whole product for that job. - Size the list for peer stats. Engagement percentiles need a peer set of at least ten creators in the same tier and niche. Add more handles for a fairer cohort read; too few and the band returns null rather than a misleading number.
- Give a brand profile to unlock brand fit. Supply themes, values, and target audience, or
brandFitand the Brand Fit view stay null. The fit reasons are only as good as the profile you pass. - Name a watchlist and run on a schedule. The product is the run-over-run delta. One run can't show what changed; the memory clock starts on run two and can't be backfilled, so start it on day one even if you only care about deltas later.
- Branch automation on
attentionPriority, not raw scores. Filter to thehighbucket so alerts stay stable across runs instead of chasing decimal shifts in a score. - Read the engagement band, not the raw rate. A 2% rate is strong for a mega account and weak for a micro one. The band already does the tier comparison for you.
- Use the compat output for raw ingestion. When an existing pipeline only needs the standard profile field set,
outputProfile: "compat"returns it unchanged, so migration is additive rather than a rewrite. - Wire a webhook on run finish. Push the Signal Feed into Slack or a campaign board via an Apify webhook so the queue becomes a notification stream, not a manual pull.
Common Instagram vetting mistakes
- Treating a scrape as vetting. Exporting profiles is extraction. Vetting is the engagement judgement and brand-fit ranking you're doing by hand afterward. Move that work into the tool.
- Sorting by followers and calling it a shortlist. Follower count ignores whether the audience engages and whether the feed fits the brand. A tight 40k-follower creator can outperform a distracted 2M one.
- Reading a raw engagement rate without the tier. The same percentage means opposite things at different sizes. Read the cohort band, not the number.
- Expecting a fake-follower verdict. This tool won't give you one, by design. It gives you an authenticity read (band, percentile, anomaly flag with evidence) for an informed human call, not an accusation.
- Expecting deltas on the first run. Memory can't be invented. Run one reports first sight honestly; trajectory and change tracking sharpen after several scheduled runs on the same watchlist.
- Reading every row anyway. If you've got a ranked queue and still scroll the full export "just in case," you've kept the bottleneck. Trust the queue and stop at the top of the list.
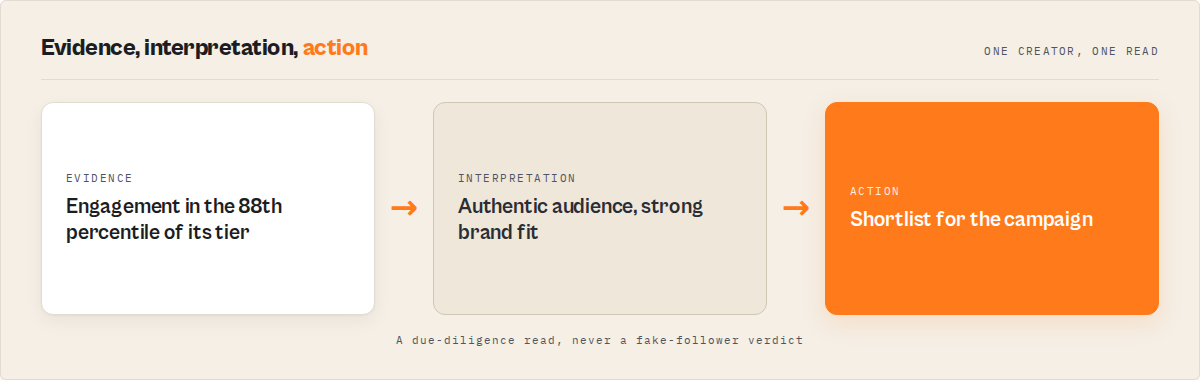
Mini case study: an agency's campaign shortlist
Before. A brand agency vetting creators for a six-figure nature-and-science campaign pulled roughly 40 profiles per shortlist into a sheet, then spent close to an hour sorting by followers, opening a few posts each, and guessing which audiences looked real and which fit the brief. Fast-rising micro creators got missed because nobody could hold last quarter's numbers in their head, and a creator whose feed was already saturated with ads slipped through because "sponsored density" wasn't a column anyone maintained.
After. They switched to a run with rankBy: brandFit and a brand profile, then read the top of the ranked report: a handful of creators flagged high, each with an engagement band, a brand-fit reason, and a sponsored-density read attached. The already-saturated account deprioritised itself. On the next scheduled run, only the creators whose momentum or engagement had shifted came back flagged.
The reframe is the whole point: an hour of manual vetting per shortlist collapsed into a five-minute read. These numbers reflect one team's workflow; results vary with how many creators you track, how often you run, and how tight the niche cohort is.
Which teams feel this pain hardest?
The teams that get the most out of Instagram creator intelligence run creator vetting as continuous work, not one-off pulls. Brand and influencer-marketing teams vetting audiences before they pay. Agencies building campaign shortlists against a brief. Competitor analysts tracking a rival's activated roster week over week. Creator-economy scouts hunting emerging and micro creators before they're expensive. Investors watching for the audience inflection a monthly Sheets diff misses by 30 days.
If your Instagram work is a one-off list you build once and never refresh, you don't need this. A plain scraper is cheaper and fine. The intelligence layer earns its keep when the job recurs.
Vetting creators through the API
You call the Instagram Scraper actor the same way you'd call any Apify actor: pass a list of handles and a rank axis, then read the ranked records back. Here's the call pattern in Python, using the Apify client. This is how you invoke the actor, not a rebuild of what it does inside.
from apify_client import ApifyClient
client = ApifyClient("YOUR_API_TOKEN")
run = client.actor("ryanclinton/instagram-scraper").call(run_input={
"mode": "profiles",
"usernames": ["nasa", "natgeo", "bbcearth"],
"rankBy": "engagementQuality"
})
for item in client.dataset(run["defaultDatasetId"]).iterate_items():
if item.get("recordType") == "creatorDueDiligence":
band = (item.get("engagementQuality") or {}).get("band")
print(f"{item['handle']}: {item['attention']['attentionPriority']} — engagement {band}")
Swap rankBy to brandFit (with a brandProfile) to build a shortlist, or set a watchlistName to turn the run into a monitoring feed. The decision fields arrive with the data; you route on them.
Implementation checklist
- Decide your job: campaign vetting, competitor monitoring, emerging-creator scouting, or brand-fit shortlisting. That sets your rank axis.
- Paste your handles in profiles mode (the default), with or without the
@. - Run once with defaults to see the ranked report shape and open the Attention Queue view first.
- Add a brand profile if you want brand-fit scoring; without one those fields stay null.
- Name a watchlist. Without it, the run is one-shot with no memory.
- Schedule the run weekly or daily for roster and competitor tracking.
- Wire automation to branch on
attentionPriority, not raw scores. - After a week, read the growth history and Creator Replay fields. That's when the memory pays off.
Limitations
Honest constraints, because the tool that names them is the one you can trust:
- Public profiles only. It reads public Instagram profile data, does not log in, and skips private accounts (returned as
isPrivate). It does not bypass access restrictions. - No follower or commenter data. It returns aggregate public profile metrics only, never individual follower or commenter lists or personal data.
- No fake-follower verdict. Engagement quality and the anomaly flag are cohort-relative reads with evidence, never an accusation that a specific audience is bought. If you want an automated "this account is fake" judgement, this isn't it, on purpose.
- No private-audience demographics. Age, gender, and location splits of a creator's audience live behind the login wall, so a managed platform is the tool for that.
- No hashtag or explore discovery. Those pages are login-walled, so discovery is via handle and URL lists plus similar-creator suggestions, not hashtag crawling.
- History warms up. Cross-run trajectory, benchmarks, and market views are thin until the actor has seen a creator over time; first sight is reported honestly, never fabricated.
- No prices or forecasts. It returns a relative market-position read, never a dollar rate quote, and it describes current and historical signals rather than predicting future events.
When you need this
You probably need Instagram creator intelligence if:
- You're vetting a list of 10 to 200 creators before a campaign on a recurring basis.
- A brand or agency team needs to rank a shortlist against a specific brief, not by follower count.
- You track a competitor or signed roster week over week and want the run-over-run delta.
- You're scouting emerging and micro creators from a handle list before they get expensive.
- You're feeding an AI agent or automation that needs creator records with engagement, scoring, and brand-fit signals attached.
You probably don't need this if:
- You want a one-off raw export to process in your own pipeline (a plain scraper is fine).
- You need private-audience demographics or a fake-follower verdict (use a managed audit platform).
- You need follower or commenter list exports, or hashtag-based discovery.
Frequently asked questions
What is the difference between an Instagram scraper and Instagram creator intelligence?
An Instagram scraper extracts substrate (followers, bio, verified status, recent posts) and returns rows. Instagram creator intelligence returns the same substrate plus a routable decision per creator: a Creator Intelligence Score, an engagement-quality band against the peer tier, brand fit, sponsored density, a recommended next step, and growth history across runs. The scraper is the substrate. The intelligence layer is the substrate plus what to do about it.
Can I use this to check for fake followers on an Instagram account?
Not as a verdict, no. It's not a fake-follower detector and won't make that accusation. What it does is an engagement authenticity check: it measures each creator's engagement rate against their peer tier, flags anomalous engagement with evidence, and returns a descriptive band (strong, normal, low, or anomalous to vet). That's the right input for an informed vetting call, not an automated fake-follower judgement.
How do I find emerging and micro-influencers on Instagram?
Run profiles mode with rankBy: breakoutPotential and read the Breakout view. It ranks small-to-mid creators who are rising early, with a radar rank, ahead of the already-obvious accounts. Breakouts are computed against each creator's own baseline, so a modest-follower creator popping above their normal ranks ahead of a mega account coasting on old numbers.
How do I rank Instagram creators for a specific brand?
Supply a brandProfile with your brand's themes, values, and target audience. The actor ranks every creator on the list by brand fit, returns a brandFitScore and plain-English fit reasons for each, and can build a campaign shortlist of ranked candidates with exclusion reasons for the ones that don't fit. It matches against public profile signals only, so it ranks fit, not follower count.
Can I track Instagram creators over time?
Yes. Set a watchlistName and reuse it on a schedule. After the first run, the actor returns only what changed (new breakouts, anomalies to vet, creators going quiet) with a change briefing at the top, and it banks each creator's public follower and engagement metrics so later runs show the trajectory: growing, peaking, mature, declining, or dormant.
Can I migrate from a standard Instagram scraper without changing my code?
Yes. The inputs are handles and URLs as usual, and outputProfile: "compat" returns the exact standard profile-plus-posts field set, including the error-code taxonomy, so downstream code reading the raw fields works unchanged. You migrate the pipeline as-is and get the decision layer as an additive upgrade rather than a rewrite.
Is it a practical alternative to an influencer-intelligence SaaS?
For the core vetting job (engagement quality against peers, sponsored density, brand fit, and growth history per run) yes, on public profile data at a per-result cost instead of an annual seat. It is not a full managed platform: it doesn't return private-audience demographics or manage live campaigns. If those are the requirement, a managed platform is the better fit.
Is it legal to scrape Instagram with this actor?
It reads only public profile data and does not log in, access private accounts, or bypass restrictions. Whether your specific use is permitted depends on your jurisdiction and intended use, including data-protection rules and platform terms. For background, see Apify's guide to web scraping legality. Consult legal counsel for your case.
The bottom line
If you pull Instagram profiles once and process them yourself, use a row scraper. It's cheaper, and it's the right tool for that job. But if you're vetting creators before every campaign, extraction stopped being the bottleneck a long time ago. The work is deciding whose audience is real, who's growing, and who fits the brief, and that's exactly what a due-diligence report is built to do. The Instagram Scraper actor ships it as the default output: ranked, explained, and remembered run over run. Rows are the substrate. The decision is the product.
Ryan Clinton publishes Apify actors and MCP servers as ryanclinton and builds developer tools at ApifyForge.
Last updated: July 2026 </content> </invoke>