The problem: You manage 40 locations, it's Monday, and the regional director wants to know which stores are slipping before the franchise call. So you find each place URL, run a Google Maps reviews scraper, and dump the reviews into a sheet per location. Then two questions hit you that the scraper never answered. First: did I actually get every review, or did it quietly stop at page nine? Second: which of these 40 locations is getting worse, and why? The scraper pulled rows. The trust and the triage are the job nobody sold you.
The real competitor isn't another reviews scraper. It's the spreadsheet, plus the nagging feeling you can't fully trust the count in it.
This is part of a run we keep coming back to at ApifyForge, because the same gap shows up on every source. We made the argument for TikTok creator intelligence and walked the full reviews-to-risk-score architecture elsewhere. Google reviews are the version most businesses feel first, because a rating slip on Google shows up in revenue before it shows up in a report.
A Google reviews reputation layer does two things a plain scraper doesn't. It hands back a coverage receipt on every place (how many reviews Google claimed versus how many were collected, deduped by a stable ID, in a deterministic order) so you can trust the set. And it stacks a reputation read on top: sentiment, the recurring complaint driving a rating down, whether the location is trending worse, and a ranked queue of which stores need attention first. The Google Maps Reviews Scraper actor is the worked example throughout this post. It prices at $0.0006 per review scraped under pay-per-event pricing, coverage audit and reputation read included, and migrates existing place-URL pipelines unchanged through a compat output.
The coverage receipt is the part a plain scraper never gives you. On a clean run it reads back like this:
312 reviews claimed by Google
312 collected
0 duplicates
coverage: complete
Use it when Google reviews are continuous work: multi-location monitoring, agency reporting, complaint-theme mining, pre-acquisition screening. If you only need a one-off raw pull you'll process yourself, a plain row scraper is cheaper and the right call.
In this article: What a reviews scraper returns · Why raw rows fail · What a coverage audit is · How the reputation layer works · What it returns · Alternatives · Best practices · Common mistakes · Limitations · FAQ
Key takeaways
- Substrate isn't the bottleneck; trust and triage are. Every popular Google Maps reviews scraper hands back rows, and the incumbent earned its rank, but "did I get every review?" and "which location is getting worse?" stay manual.
- Two wedges separate a reputation layer from a scraper: a coverage audit (claimed vs collected, deduped by
reviewId, deterministic order, an explicit stop condition) and a reputation read (sentiment, complaint themes, rating trajectory, a 5-state reputation state, and a ranked attention queue). - You don't need a place URL. Type a business name, a postcode, a
share.googlelink, a place ID, or a CID, and the actor resolves it to a Google place first. - Drop-in compatible with the incumbent's input and field shape, so you migrate a place-URL pipeline unchanged and get the audit and the read as an additive upgrade.
- The Google Maps Reviews Scraper actor prices at $0.0006 per review scraped under pay-per-event pricing, with the coverage audit and reputation read in that per-review price.
Rows vs a coverage-audited reputation read: a concrete look
| You ask | A row dump gives you | A coverage-audited reputation layer gives you |
|---|---|---|
| Did I get every review? | 312 rows and no way to know | 312 claimed, 312 collected, 0 duplicates, complete with a stop condition |
| I scraped this place twice — why two datasets? | Two different sets, ordered differently | An identical set, reviewId-keyed, deterministic by construction |
| What's dragging the rating down? | A wall of negative text to read | A root issue: delivery_delay, 42% of negatives, emerging |
| Is this location trending worse? | A single star average | ratingTrajectory (recent 3.6 vs baseline 4.3) plus a 5-state read |
| Which of 40 locations first? | 40 sheets to sort by hand | A ranked attention queue with whyNow and the reviews behind it |
What is a Google Maps reviews scraper?
A Google Maps reviews scraper extracts the review text, star ratings, dates, owner responses, and reviewer details for a place on Google Maps. Most tools key off a place URL and hand back rows. A reputation layer resolves a business name to a place itself, audits the collection against Google's own claimed count, and returns a reputation read on top, so the output is decision-ready rather than a spreadsheet you still have to interpret.
A scraper and a reputation intelligence layer are not the same product. A scraper extracts and stops. Reputation intelligence is what happens after extraction: the coverage check, the sentiment split, the complaint grouping, the trajectory, and the run-over-run comparison that turn a scrape into a shortlist you can act on this week.
There are broadly three categories of Google reviews tooling in 2026. Row scrapers export the reviews and leave every decision downstream to you. Reputation-management SaaS (Birdeye, Podium, ReviewTrackers) live in a dashboard on a monthly subscription and lean toward reply workflows for a brand managing its own listings. Reputation-layer actors focus on the reviews and ship the decision layer: a coverage audit, sentiment and complaint themes, a reputation state machine, and persistent memory per watchlist. At ApifyForge we group these by what they output, not just what they scrape, because the output contract is what decides whether you still open a spreadsheet afterward.
Why does this matter now?
Google reviews carry more commercial weight in 2026 than any other review source, which is exactly why getting the count and the read right matters. BrightLocal's Local Consumer Review Survey has repeatedly found that the large majority of consumers read online reviews before choosing a local business, and Google is the platform they check first.
The money is not abstract. Harvard Business School's Michael Luca found in Reviews, Reputation, and Revenue that a one-star swing in a business's online rating moved revenue by roughly 5-9% for independent restaurants. When a fraction of a star is worth that, "which of my locations is slipping, and what's causing it?" is not a reporting nicety — it's the question. A flat export of review rows ships neither the answer nor a way to know whether the export was even complete.
What does a Google Maps reviews scraper actually return?
A Google Maps reviews scraper returns substrate: one record per review with the text, a star rating, a published date, the reviewer name, and any owner response. Useful, accurately extracted data. If your job is "get me the rows," that's the right tool.
Here's roughly what one review record looks like. Note this is output you read, not code you run.
{
"reviewId": "Ci9DQUlRexample1",
"text": "Waited 50 minutes for delivery, food was cold.",
"stars": 2,
"publishedAtDate": "2026-05-13",
"reviewerName": "Sarah Chen",
"responseFromOwnerText": null
}
The trouble starts when your job is anything other than "get me the rows," which is most jobs. First, you have no idea if the set is complete. A place page claims 312 reviews; your scraper returned 280 and said nothing about the gap. Silent undercounts are the number-one complaint about raw review scrapers, and a spreadsheet can't tell you it's missing rows.
Second, a stack of negative reviews is a temperature reading, not a diagnosis. Two reviews saying "slow" and forty saying "slow" are a different situation, and nobody hand-codes 300 reviews into themes on a Monday. Third, a star average hides direction. A 4.1 that used to be 4.3 and is still falling is a fire; a 4.1 that's been flat for two years is fine. The rows can't tell them apart.
Why do raw review rows fail for reputation work?
Raw review rows fail for reputation work because they externalise every decision back onto a human. A 300-row export has no coverage receipt, no theme grouping, no trajectory, and no run-over-run memory, so the actual work — deciding whether the scrape was complete, what's driving complaints, and what changed — still happens by hand.
Here's the part people underestimate. Reputation intelligence is genuinely hard, which is exactly why most tools quietly stop at extraction:
- Completeness is unprovable from rows alone. Without the place's own claimed count and a ledger of how pagination ended, you can't tell a complete scrape from one that stopped early. "I got some reviews" is not "I got the reviews."
- The same place should scrape identically twice — and usually doesn't. Without a stable dedup key and a fixed order, two runs of one place produce two different datasets, which quietly breaks any diff you try to run.
- Complaints are themes, not text. The story isn't 40 negative reviews; it's that 42% of them are about delivery time and that share is climbing in the last 30 days. Spotting that by eye across locations doesn't scale.
- Rating is a trajectory, not a snapshot. Three locations can all sit at 4.1 this week and only one is on the way down. You need a recent-window-versus-baseline comparison to see it.
- Most tools forget every prior run. A one-shot scrape can never tell you whether a location just crossed from "attention" into "critical" or which store fell nine ranks since last month.
The real competitor to a Google reviews scraper was never another scraper. It's the manual triage that sits downstream of one. That's the same argument we made for decision-first analytics: the output should be one routable read, not a spreadsheet you re-interpret every week.
What is a review coverage audit?
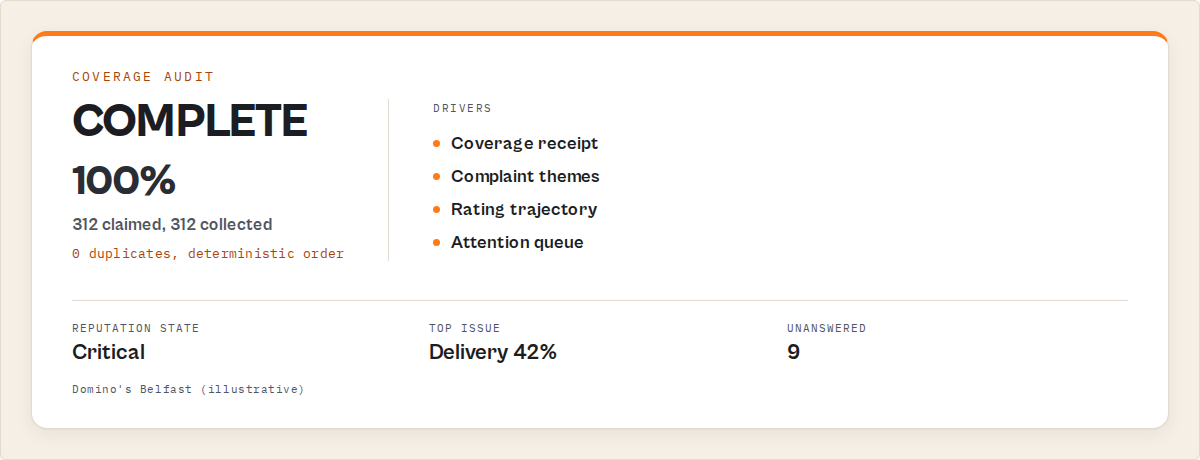
A review coverage audit is a per-place receipt that reports how many reviews Google's own place header claimed versus how many the run actually collected, plus why any gap exists. Every place comes back with reviewsClaimed, reviewsScraped, a coverageStatus, and a stop condition, so completeness is a stated fact, not a hope.
This is the first of the two wedges, and it's the one that kills the silent-undercount problem. A typical first run reads back like this: 312 claimed, 312 collected, 0 duplicates dropped, coverage complete. When the number doesn't match, the status says why — capped if you set a low per-place limit, partial if Google stopped serving pages mid-corpus — with a gapReason, never a silent truncation. Reviews are deduped by Google's stable reviewId and emitted in a fixed order, so re-running the same place produces an identical set by construction. Two runs, one dataset. That's what makes a diff trustworthy.
The honest scope matters here, and it's stated on the tin: the audit reports exactly what Google's header claimed and exactly what was collected. It never claims it got "every review that ever existed on the internet." A count you can check beats a count you have to trust.
How does the reputation layer work?
The reputation layer works by adding a decision stack on top of the audited review set. After the reviews are collected and verified complete, deterministic detectors compute sentiment, group complaints into root issues, measure rating trajectory against a baseline, and assign each location a reputation state and an attention priority — every signal carrying the exact review IDs behind it.
The mental model is a pipeline: input → place resolution → paginated reviews with a coverage ledger → deterministic synthesis → per-place and cross-run intelligence → profiled output. Each layer adds something the row dump never had.
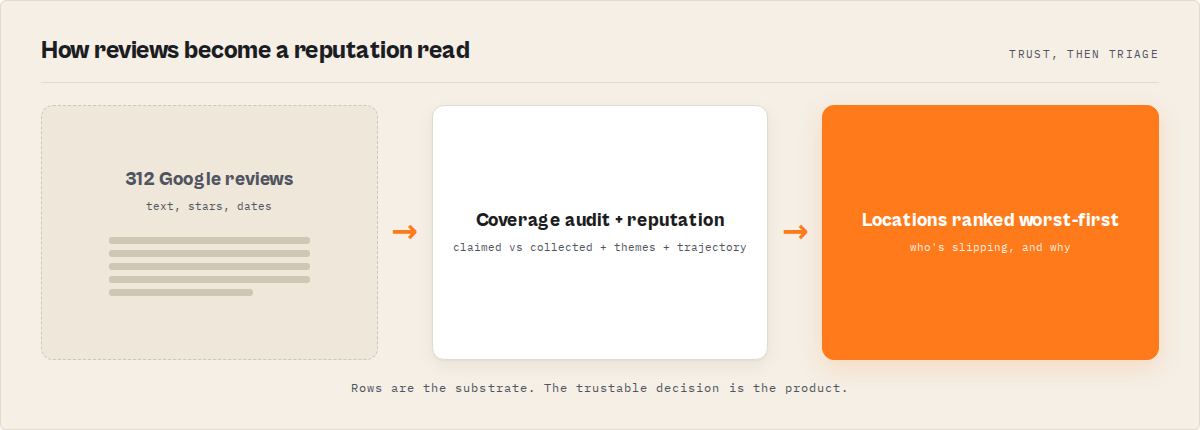
The synthesis step is the interpretation. Instead of leaving you to read 300 reviews, it surfaces an Issue Registry: complaint themes grouped into canonical root issues, each with its share of negatives and a cohortEmergence reading that separates a new problem from a background constant. An issue at a low share in older reviews but a high share in the last 30 days is flagged emerging — that's the one worth acting on this week.
On top of that sits the routing layer: a 5-state reputation read (healthy, monitor, attention, critical, recovery) derived deterministically, a rating trajectory, response-health metrics like unanswered recent negatives, and a ranked attention queue with a plain-English whyNow. The memory is the part a competitor can't backfill: set a watchlistName and each later run returns only what changed, with rank movement and a reputation timeline. A single scrape tomorrow can reproduce the rows, but not that longitudinal context — it only exists if you've been accumulating it.
One thing the actor deliberately does not do: use an LLM in the decision path. Every score, state, and escalation is computed deterministically, so the same input reproduces the same read. An optional model names complaint themes only, never decides.
What does the reputation layer return?
The reputation layer returns a decision-ready record per place: a coverage block, a sentiment split, the Issue Registry, a rating trajectory, a reputation state, an attention priority with whyNow reasons, and the exact reviewIds behind every signal, plus the raw review rows underneath.
Here's a trimmed place_intelligence record so you can see the shape. Again, this is output you read, not code you run.
{
"title": "Domino's Pizza - Belfast",
"coverage": {
"reviewsClaimed": 312,
"reviewsScraped": 312,
"coverageStatus": "complete",
"deterministicRun": true
},
"reviewSynthesis": {
"sentiment": { "positive": 0.58, "negative": 0.28, "neutral": 0.14 }
},
"activeIssues": [
{
"rootIssue": "delivery_delay",
"shareOfNegativeReviews": 0.42,
"cohortEmergence": { "emergence": "emerging" },
"evidenceReviewIds": ["Ci9DQUlRexample1", "Ci9DQUlRexample2"]
}
],
"ratingTrajectory": { "recentWindowRating": 3.6, "baselineRating": 4.3, "delta": -0.7 },
"reputationState": { "current": "critical", "previous": "attention" },
"attentionPriority": "high",
"whyNow": [
"Rating dropped 0.7 in the recent window (4.3 to 3.6).",
"Complaint 'slow / late service' rising — now 42% of negative reviews.",
"9 recent negative reviews with no owner response."
],
"recommendedAction": "Investigate the slow-service complaints this week.",
"locationRank": 17,
"rankMovement": -9
}
Everything below coverage is the decision an experienced analyst would produce by hand after an hour of reading. attentionPriority is the field your automation routes on. whyNow is the rationale for a human. recommendedAction is always a prioritisation instruction — Review, Investigate, Monitor, Compare — never an in-platform action. The actor surfaces that nine negatives are unanswered; it never replies, flags, or deletes a review on Google. Routing attention is the job; acting on the platform for you is not.
What are the alternatives to a reputation layer?
There are four practical alternatives to a coverage-audited reputation layer, each with real tradeoffs. The right choice depends on whether your job is one-off extraction or recurring monitoring, how much engineering you want to own, and whether you need a reply workflow or a decision.
1. A place-URL row scraper (e.g. compass/Google-Maps-Reviews-Scraper). The dominant Google reviews row vendor on the Apify Store, and a solid choice when raw extraction at scale is all you need. It keys off a place URL or ID and returns reviews as flat rows. Best for: a one-time bulk pull you'll analyse in your own pipeline. Where it breaks: it ships none of the jobs downstream of extraction, so completeness verification, theme grouping, trajectory, and weekly diffing stay manual, and business-name input isn't on the menu.
2. Build it yourself. Wire up place resolution across six input shapes, a coverage-ledger paginator, deterministic dedup, a theme and issue-grouping engine, rating-trajectory math, a reputation state machine, and a cross-run store, then keep all of it versioned and reproducible. Best for: a team with spare engineering capacity and a one-of-a-kind requirement. Where it breaks: you now own a maintained service, not a script, and the persistent store that makes "what changed" possible is months of accumulated data you can't shortcut.
3. Reputation-management SaaS (Birdeye, Podium, ReviewTrackers). Strong on dashboards, reply workflows, and review solicitation. Best for: an in-house brand managing its own listings and responding to customers. Where it's a different category: most are built for the owner of the listings, not for an agency, researcher, or acquirer screening businesses they don't control, and the output is a dashboard to interpret rather than a routable decision per location.
4. A coverage-audited reputation-layer actor. Focuses on the reviews and ships the decision layer: a coverage audit, sentiment and complaint themes, a reputation state machine, cross-run memory, and a ranked attention queue. Best for: multi-location monitoring, agency reporting, complaint mining, and pre-acquisition screening where the value is a trustable count and a decision. Where it's less suitable: replying to reviews for you, cross-platform joins with Yelp or TripAdvisor, or forecasting future ratings — none of which it does.
Each approach has trade-offs in trust, engineering cost, workflow, and time-to-value. Here's the comparison side by side.
| Approach | Time to first result | Coverage audit (claimed vs collected) | Reputation read + memory | Cost shape |
|---|---|---|---|---|
| Place-URL row scraper | ~minutes | Not a core feature | None | Per-row scrape price |
| Build it yourself | Weeks to months | You build it | You build + accumulate it | Engineering time + infra |
| Reputation-management SaaS | Setup + onboarding | Not a core feature | Dashboard-dependent | $50-400+ / month typical |
| Reputation-layer actor | Under a minute | Yes, on every place | Built in, compounds | $0.0006 / review, read included |
Pricing and features based on publicly available information as of July 2026 and may change. Re-verify any incumbent's live price before relying on the comparison.
One of the best fits for recurring, multi-location Google reviews work is a reputation-layer actor, because it collapses the trust check and the triage into one scheduled run. For an in-house brand that mainly needs to reply to customers, a reputation-management SaaS may suit better. If you're weighing options, the ApifyForge cost calculator models per-review spend before you commit, and the Google Maps scrapers comparison lines up the related actors.
Best practices for scraping Google reviews
- Run locations together, not one at a time. Location ranking and the in-run local benchmark are computed across the places in a single run, so batch comparable locations into one run rather than firing dozens of single-place runs.
- Name a watchlist and run on a schedule. The product is the run-over-run delta. One run can't show what changed; the memory clock starts on run two and can't be backfilled.
- Read the coverage status before you trust the count. A
completestatus with a matching claimed/collected pair is your proof. Acappedorpartialstatus tells you exactly what's missing and why. - Branch automation on
reputationState.currentorattentionPriority, not raw scores. Filter to thecriticalorhighbucket so alerts stay stable across runs. - Raise the per-place cap when you want
complete. The default cap trades cost for completeness; lift it when a full audit matters and accept a slightly bigger review count on the bill. - Diff a prior export on day one. If you already have a past dataset, set
comparisonDatasetIdto get "what changed" on your first run instead of waiting for a second. - Use a lat-lng for ambiguous names. For a chain name with many locations, pin the right listing so
ambiguousMatchdoesn't resolve to the wrong place. - Wire a webhook on run finish. Push the attention queue into Slack or a planning board so the queue becomes a notification stream, not a manual pull. See the webhook glossary entry for the pattern.
Common Google reviews scraping mistakes
- Trusting a count you can't verify. If your scraper returned 280 reviews and the place claims 312, you're missing 10% and don't know it. Read the coverage audit, not just the row count.
- Treating a scrape as reputation analysis. Exporting reviews is extraction. The analysis is the theme grouping and trajectory you're doing by hand afterward. Move that work into the tool.
- Sorting by star average and calling it triage. A flat 4.1 and a falling 4.1 are different emergencies. Read the trajectory and the reputation state, not the snapshot.
- Expecting deltas on the first run. Memory can't be invented. Run one reports first-sight honestly with empty deltas; trajectory and change tracking sharpen after several scheduled runs on the same watchlist.
- Ignoring the emerging-vs-constant distinction. A complaint that's always been there at 15% is background noise. The same theme jumping to 42% in the last 30 days is the story — the Issue Registry separates them so you don't chase the wrong fix.
- Reading every review anyway. If you've got a ranked attention queue and still scroll the full export "just in case," you've kept the bottleneck. Trust the queue and stop at the flagged locations.
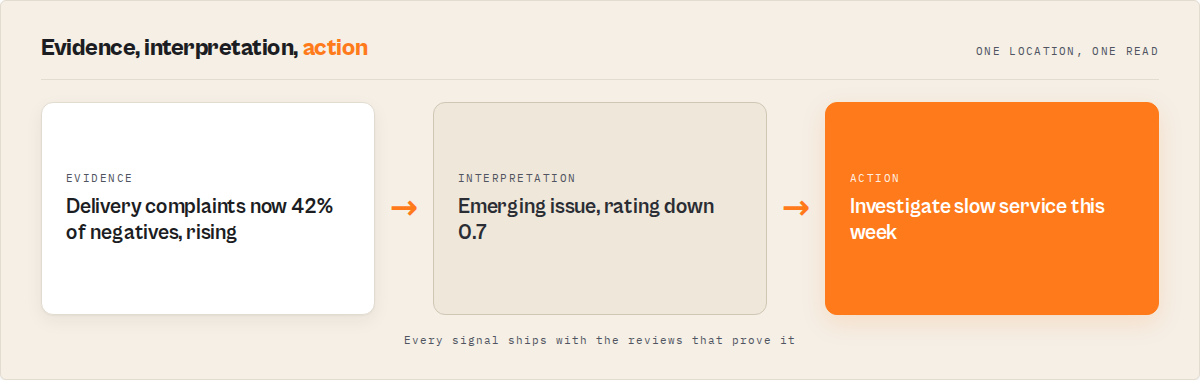
Mini case study: a multi-location Monday review
Before. A reputation agency reporting on a 40-location restaurant client pulled reviews per location into sheets each week, then spent about two and a half hours every Monday sorting by star average, eyeballing which stores "looked worse," and reading negatives by hand to guess at causes. Nobody could tell whether a scrape was complete, and a store crossing from a slow decline into a real problem was usually caught a month late — after the client noticed first.
After. They switched to a scheduled watchlist run. Each Monday they read the top of the attention queue: a handful of locations flagged critical or high, each with a coverage receipt, a rating trajectory, the root complaint driving it, and the exact reviews as evidence. The week one store's rating dropped 0.7 with a delivery_delay theme climbing to 42% of negatives and nine unanswered recent negatives, the queue surfaced it in a single run with the receipts attached, and the flagged location came pre-packaged for the client call.
The reframe is the whole point: two and a half hours of manual sorting collapsed into a five-minute read of ranked, audited locations. These numbers reflect one agency's workflow; results vary with how many locations you track, how often you run, and how busy each listing is.
Where this fits after the flag
Once a location is flagged at-risk, the review data usually feeds the next step. Push the compat profile into an existing ingestion pipeline, drop the client summary into a monthly deck, or hand the flagged locations to the Google Maps Lead Enricher actor to attach email and phone for outreach. For a cross-platform picture — Trustpilot and BBB alongside Google — the Multi-Platform Reputation Analyzer applies the same decision-layer pattern across sources.
Limitations
Honest constraints, because the tool that names them is the one you can trust:
- Coverage reflects Google's own header.
reviewsClaimedcomes from the place header; if Google's header lags or jitters, a complete scrape can read slightly under 1.0. AgapReasonalways explains a sub-1.0 ratio, and complete allows a one-review header jitter. The actor never claims it got every review that ever existed. - Partial scrapes happen. When Google stops serving pages mid-corpus, the status is
partialwith agapReason, not a silent loss. Any reviews collected before the stop are still emitted. - Ambiguous names can resolve to the wrong place. Add a lat-lng to disambiguate;
ambiguousMatchandalternativesConsideredflag the risk rather than hiding it. - Themes need a sample. Below five reviews, synthesis is disabled and only sentiment is reported. Small locations get an honest "not enough data," not an invented read.
- No cross-platform joins and no forecasting. Google reviews only; Yelp and TripAdvisor are out of scope, and the actor projects nothing about future ratings or revenue. It reports what is, not what will be.
- Read-only by design. It never posts, replies to, flags, or deletes reviews on Google, and it doesn't judge whether a review is true. It surfaces and interprets public reviews; it doesn't act on the platform for you.
When you need this
You probably need a coverage-audited reputation layer if:
- You manage or report on multiple Google locations and need to know which are slipping first.
- You can't afford a silent undercount — you need a provable, complete review set.
- You want the recurring complaint driving a rating down, with the reviews that prove it.
- You screen a target's locations before an acquisition and need review health with evidence.
- You're migrating from a place-URL-only workflow and want the audit and the read without a rewrite.
You probably don't need this if:
- You want a one-off raw export to process in your own pipeline (a plain row scraper is cheaper).
- You mainly need to reply to and solicit reviews for your own brand (a reputation-management SaaS fits better).
- You need cross-platform review joins with Yelp or TripAdvisor (not built on this stack).
- You want a forecast of future ratings or revenue (out of scope by design).
Frequently asked questions
What is the difference between a Google Maps reviews scraper and a reputation layer?
A Google Maps reviews scraper extracts substrate — review text, stars, dates, reviewer details — and returns rows. A reputation layer returns the same substrate plus a coverage audit (claimed vs collected, deduped deterministically) and a reputation read: sentiment, complaint themes, rating trajectory, a 5-state reputation state, and a ranked attention queue with the exact reviews behind every signal. The scraper is the reviews. The reputation layer is the reviews plus what to do about them.
How do I get Google reviews without a place URL?
Type the business name and location into the input field, for example Northstar Coffee Glasgow, and run the actor. It classifies the text as a free-text query, resolves it to a Google place, and scrapes the reviews. A place URL, share.google link, place ID, or CID also works, but none of them is a prerequisite — the business name alone is enough.
How do I know a review scrape is complete?
Every place carries a coverage block: reviewsClaimed from Google's own header, reviewsScraped from the run, and a coverageStatus of complete, capped, partial, or degraded. A complete status with a matching claimed/collected pair is your proof the set is whole. When the numbers don't match, a gapReason states exactly why, so a shortfall is always explained rather than hidden.
How does the actor find the complaint driving a rating down?
The Issue Registry groups synonymous complaint themes into canonical root issues, each with its share of negative reviews and a cohortEmergence reading across recency buckets. A complaint at a low share in older reviews but a high share in the last 30 days is flagged emerging, which separates a new problem from a background constant and points you at the fix that matters this week, with the evidence review IDs attached.
Can I migrate from compass/Google-Maps-Reviews-Scraper without changing my code?
Yes. The input shape matches, and setting the output profile to compat returns the same field set, so downstream code reading text, reviewId, or stars works unchanged. You migrate the pipeline as-is and gain business-name input plus the coverage audit as an additive upgrade rather than a rewrite. It's a practical drop-in alternative for buyers who also want the trust receipt and the read.
How much does it cost to scrape Google reviews with this actor?
The Google Maps Reviews Scraper actor uses pay-per-event pricing: $0.0006 per review scraped, with the coverage audit and the full reputation read included in that per-review price. Apify's free tier gives $5 in monthly credits, so a trial runs a meaningful multi-location cohort at no cash cost. You need an Apify account to run it.
Is it legal to scrape Google reviews?
The actor extracts publicly available reviews and does not log in or bypass access controls. Whether your specific use is permitted depends on your jurisdiction and intended use, including data-protection rules and platform terms. For background, see Apify's guide to web scraping legality. Consult legal counsel for your case.
The bottom line
If you pull Google reviews once and process them yourself, use a row scraper. It's cheaper, and it's the right tool for that job. But if you're monitoring locations every week, extraction stopped being the bottleneck a long time ago. The work is trusting the count and deciding where to look first, and that's exactly what a coverage audit plus an attention queue is built to do. The Google Maps Reviews Scraper actor ships both as the default output: audited, ranked, explained, and remembered run over run. Rows are the substrate. The trustable count and the decision are the product.
Ryan Clinton publishes Apify actors and MCP servers as ryanclinton and builds developer tools at ApifyForge.
Last updated: July 2026