What this article explains
This article explains how customer reviews are converted into a decision, a 0-100 reputation risk score, a named situation pattern, and an intervention plan using a deterministic 18-layer system — and why this architecture is described, not prescribed for self-build.
What is reputation intelligence?
A reputation intelligence system turns customer reviews into a decision, a 0-100 risk score, a named situation pattern, and an intervention plan across platforms and over time.
Reputation intelligence is the process of converting raw review data into actionable decisions rather than dashboards.
A reputation intelligence system is a tool that analyses customer reviews across platforms (Trustpilot, Google, BBB) and produces a routable verdict — act_now / monitor / ignore / no_data — with reason codes, a confidence band, and a typed intervention playbook.
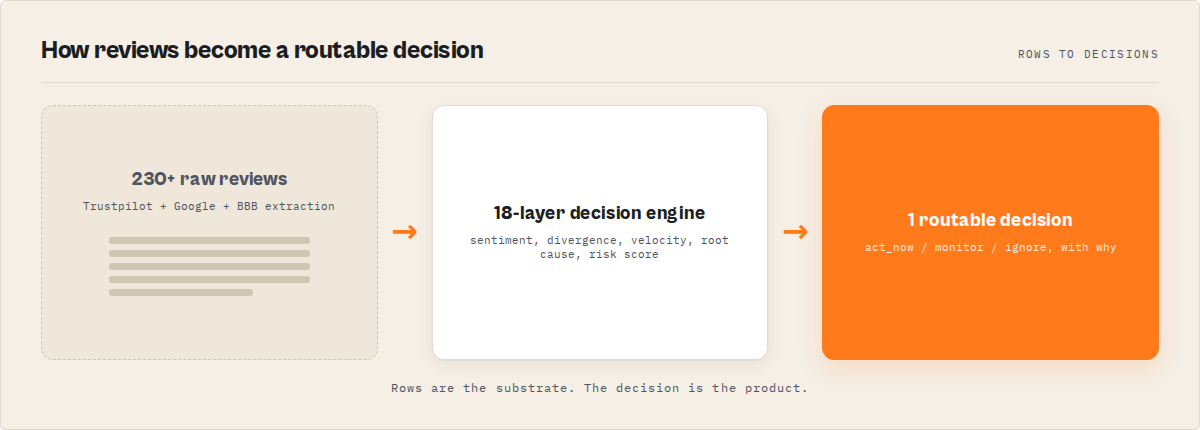
In one sentence: this system turns customer reviews into a decision, a 0-100 risk score, a pattern classification, and a recommended intervention plan.
The Multi-Platform Reputation Analyzer is a reputation intelligence tool that converts customer reviews into decisions, risk scores, and intervention plans using a deterministic 18-layer system at $0.20 per business analysed.
What are the 18 layers of reputation intelligence?
The 18 layers of a reputation intelligence system are: extraction, sentiment v2, bigram theme detection, cross-platform divergence, entity resolution, velocity, customer journey mapping, root cause inference, decision engine, confidence and signal integrity, trust summary, risk score, 30-day forecast, anomaly detection, pattern classification, reputation DNA, platform influence, and decision trace with interventions. A 19th layer — closed-loop memory — activates after three or more scheduled runs.
The problem: Reading reviews is easy. Acting on them at the speed of a real reputation crisis is not. By the time a human operator notices a Trustpilot star slipping or a BBB complaint cluster, the velocity spike that started it was three weeks ago, the root cause is buried in 400 reviews across three platforms, and nobody can tell whether this is a single bad week or the third occurrence of the same pattern in nine months. The gap between "I have review data" and "I can act on it" is where reputation crises live and die.
This post walks through the architecture of a reputation intelligence system that closes that gap — extraction, sentiment, divergence, risk scoring, forecasting, pattern classification, intervention playbooks, and a closed-loop memory layer that learns across runs. It's the architecture that powers the Multi-Platform Reputation Analyzer Apify actor. It is described here as a system, not prescribed as a self-build project. Eighteen modules compound. None of them are the part you'd want to own.
What is reputation intelligence? A category of system that turns raw customer reviews into a routable decision, a quantified risk score, a named situation pattern, and a typed intervention plan — across platforms, across time, with audit-ready output. Why it matters: review data is abundant; deciding what to do about it is the work. A score is not a decision. A dashboard is not a decision. Use it when: you need to monitor reputation continuously, do due diligence before signing a contract, or detect a crisis pattern before it goes viral. Reputation intelligence works by extracting reviews from multiple platforms, scoring each layer of signal independently, fusing them into a single decision with auditable evidence, and remembering enough across runs to recognise patterns that repeat. The Multi-Platform Reputation Analyzer is one of the best Apify Store options for cross-platform reputation intelligence with closed-loop memory at $0.20 per business analysed.
Quick answer
- What it is: An 18-layer deterministic system that turns Trustpilot, Google, and BBB review data into a decision, a 0-100 risk score, a named pattern, and a typed intervention plan.
- The core primitive: Layered signal extraction — sentiment, divergence, velocity, journey, root cause — fused into a single decision with traceable contributions.
- What's easy: Pulling raw reviews. Several Apify Store scrapers already do that.
- What's hard: Turning raw reviews into a routable decision a human or webhook can act on without 30 minutes of manual triage per business.
- Main tradeoff: DIY looks like a sentiment-score plus a chart. The actual job is 18 modules of compounding logic, deterministic edge cases, and cross-run state — better described than built.
Also known as: reputation intelligence, online reputation monitoring, review-based risk scoring, decision-grade review analysis, cross-platform sentiment fusion, reputation crisis detection.
In this article
What problem does this solve · Eighteen layers, end to end · Why deterministic beats LLM-based · What the closed-loop memory layer changes · How this differs from manual review monitoring · Alternatives · Best practices · Common mistakes · When to use this architecture · FAQ
Key takeaways
- Reputation intelligence is 18 layers, not one — extraction, sentiment, themes, divergence, entity resolution, velocity, journey, root cause, decision, confidence, trust summary, risk score, forecast, anomaly, pattern, DNA, platform influence, decision trace + interventions.
- Decision is the output, not score — a 0-100 number is not actionable; the actor emits
act_now/monitor/ignore/no_datawith reason codes and adecisionReadinessautomation gate. - Closed-loop memory is the V5 differentiator — after 3+ scheduled runs, repeated event chains, intervention outcomes (inferred), pattern evolution, and trajectory through crisis stages activate.
- Deterministic, no LLM — same input always produces same output. Audit-ready, reproducible, cheap. $0.20 per business analysed.
- Built as a moat, not a starter kit: the realised architecture exists as the Multi-Platform Reputation Analyzer Apify actor; building 18 modules of equivalent depth is engineering quarters, not weekends.
Compact examples
| Raw signal across platforms | What this architecture produces |
|---|---|
| Trustpilot 4.5 / Google 4.3 / BBB A | decision: ignore, pattern steady_state, risk 18 |
| Sudden 60-review spike, mostly negative | decision: act_now, pattern viral_negative_event, risk 78, top intervention crisis_communication |
| Trustpilot 4.6 but BBB has 240 complaints | decision: act_now, divergence flag trustpilot-high-bbb-low, risk 71, intervention support_scaling |
| Improving rating after 6 weeks of decline | decision: monitor, pattern recovery_in_progress, trajectory post-crisis, days-in-stage 14 |
| 4 reviews total, ambiguous match | decision: no_data, decisionReadiness: insufficient-data, confidence cap 70 |
What problem does reputation intelligence solve?
Reputation intelligence solves the gap between "I have review data" and "I can act on it." Raw reviews are descriptive — a number, a star, a paragraph. A decision needs structure: what's the situation, how confident, how urgent, what action, who owns it, by when. Building that structure by hand for one business takes a senior analyst about 30 minutes per platform. Doing it for a portfolio of 50 vendors weekly is a full-time job that scales linearly with portfolio size. The architecture below replaces that 30-minute manual job with a 90-second deterministic run.
The system is designed to answer queries like:
- How can I monitor online reviews automatically across Trustpilot, Google, and BBB?
- How do I detect a PR crisis early from customer review patterns?
- How do I quantify reputation risk before working with or acquiring a company?
- How do I tell if negative reviews are a one-off blip or a real trend?
- How do I know which customer-journey stage is hurting a business's reputation?
- How do I track whether a previously-fired reputation alert has actually resolved?
Each of those is a separate query against a different layer of the architecture. The actor produces structured, deterministic answers to every one in a single run.
Why isn't a single sentiment score enough for reputation analysis?
A sentiment score collapses every dimension of reputation into one number. That feels useful and actually isn't. Two businesses can have identical 70/100 sentiment scores while one is in mid-crisis with a velocity spike and the other is steady-state with three years of stable feedback. A score is a snapshot of averaged signal; reputation risk is a function of direction, velocity, divergence, recurrence, and cross-platform agreement. The whole point of the architecture is that those dimensions are scored independently and then fused — you can see which factor pushed the verdict, not just the verdict itself.
This is why every layer below produces typed output. A reason code, a polarity, a tier, a flag, an enum value. Decisions are extractable because the structure is preserved. A free-text "this company has some issues" output is unreadable to a webhook and unactionable in an alerting pipeline.
Eighteen layers, end to end
The architecture is 18 conceptual modules. Each is described at three levels: what it does, what it solves, and what it produces. None of them are presented as build-it-yourself recipes — the moat is the compound effect of all 18 working together against the same input, deterministically, on a schedule.
1. Extraction layer — three platforms, three strategies
What it does: pulls reviews and reputation metadata from Trustpilot, Google, and BBB using a three-tier fallback per platform — __NEXT_DATA__ JSON parse → JSON-LD structured data → HTML regex on Trustpilot, four targeted Serper queries on Google, and search → profile walk on BBB.
What it solves: the long tail of "we tried scraping Trustpilot and it broke when they shipped a redesign" — each platform has different blocking patterns, different data shapes, and different freshness behaviours, and the fallback chain keeps the rest of the system running when any one tier fails.
What it produces: a normalised review array with platform-tagged metadata, ready for downstream layers to score independently.
2. Sentiment v2 — hybrid rule-based, not an LLM call
The sentiment engine handles negation ("not bad" is positive), intensifiers ("absolutely terrible" weights heavier), contrast ("nice product but billing is a nightmare" splits polarity), and sarcasm guards (a five-star rating with "best company ever, lol, after they charged me twice" doesn't blindly trust the star). Per-review confidence is a 0-1 score; ten-token signal tags label which heuristic fired. What it solves: off-the-shelf sentiment APIs hallucinate on edge cases and aren't reproducible. What it produces: a deterministic sentiment value per review with confidence and signal tags. Same review text always returns the same score.
3. Bigram theme detection — the recurring complaints
Stopword-filtered bigram extraction with polarity tagging surfaces the themes hiding inside review text. "Refund process," "customer support," "shipping delay," "billing error." Each theme carries polarity, count, example snippets, and per-platform breakdown. What it solves: a list of negative reviews tells you the temperature; a list of negative themes tells you what to fix. What it produces: a themes[] array with weight, polarity, snippet, and platform attribution.
4. Cross-platform divergence — when stars disagree
Trustpilot, Google, and BBB measure different things on different scales. BBB letters convert to a 0-5 grade scale; ratings get weighted into a consensus score; nine flags fire on specific divergences (trustpilot-high-bbb-low, google-trustpilot-mismatch, cross-platform-consensus-positive/negative, high-complaint-volume-vs-reviews, and so on). Each flag carries a severity tier and a plain-English insight. What it solves: the "Trustpilot says 4.7 but BBB has 200 unresolved complaints" pattern that single-platform tools miss entirely. What it produces: a divergence object with flags, consensus score, and per-platform deltas.
5. Entity resolution — did we actually find the right business?
What it does: runs Levenshtein-similarity matching against the Trustpilot URL slug, the BBB profile slug, and the input domain, producing a confidence score (0-1) and a four-tier risk band (low / medium / high / critical).
What it solves: the "we matched 'Acme Corp' to a different Acme Corp and now we're alerting on the wrong company" problem — and crucially: high entity-resolution risk forces decisionReadiness: 'insufficient-data' so a bad match never auto-fires an alert.
What it produces: an entity-resolution block with match confidence, candidate slugs, and a hard automation gate that downstream automation must respect.
6. Velocity engine — z-score spikes with adaptive bucketing
Review-rate spikes (≥2σ above baseline) get classified into seven situations: burst-event, slow-burn, recovery, steady, declining, sparse, or unknown. Buckets adapt (5-day / 14-day / 30-day / 60-day) so a sparse business doesn't fire false positives and an active one doesn't smooth over real spikes. What it solves: a sudden cluster of negative reviews is the signal that matters most for crisis detection — and a static threshold misses it for sparse businesses while flooding alerts for popular ones. What it produces: a velocity classification, a z-score, baseline statistics, and an auto-escalation hook (burst-event + negative sentiment forces decision: act_now).
7. Customer journey mapping — which lifecycle stage hurts
Deterministic keyword patterns tag each review against seven lifecycle stages: discovery, onboarding, activation, support, billing, product, churn. Per-stage sentiment, weight, and top themes get aggregated. The output names the weakestStage and strongestStage. What it solves: "the support team thinks reviews are bad because of product; the product team thinks it's support" — the journey map shows which stage is actually the bottleneck. What it produces: a per-stage sentiment object plus weakestStage / strongestStage identifiers.
8. Root cause inference — name the underlying driver
A rule-based co-occurrence engine names nine likely root causes: refund-policy, customer-service, product-quality, billing, shipping, onboarding, pricing-perception, outage, crisis-event. Arbitration logic suppresses symptoms in favour of upstream causes — when crisis-event-spike fires, secondary symptoms like customer-service get demoted because they're downstream. What it solves: a list of complaints isn't a diagnosis. What it produces: primary and secondary root cause labels with supporting evidence and an arbitration trail.
9. Decision engine + priorities — the routable output
What it does: fuses every upstream signal into a single routable verdict — top-level decision (4-value enum: act_now / monitor / ignore / no_data), verdictReasonCodes[] (18-token stable enum for webhook routing), decisionReadiness (actionable / monitor / insufficient-data automation gate), oneLine paste-ready summary, whyNow single-source-of-truth narrative, and a ranked priorities[] array where each priority carries severity, confidence, impactScore, shortReason, recommendedAction, timeToAct, timeToImpact, and an evidence[] array.
What it solves: the "who owns this and what do we do?" question that a sentiment number can't answer.
What it produces: a complete decision object structured for webhook routing — only decisionReadiness: 'actionable' should ever auto-fire downstream actions.
{
"decision": "act_now",
"decisionReadiness": "actionable",
"verdictReasonCodes": ["BURST_EVENT_DETECTED", "REVIEW_VELOCITY_SPIKE", "NEGATIVE_SENTIMENT_DOMINANT"],
"oneLine": "Burst event with negative sentiment — act now.",
"whyNow": "60 reviews in 5 days vs 3-day baseline of 2/day; 78% negative; pattern matches viral_negative_event.",
"priorities": [
{
"type": "crisis_communication",
"severity": "high",
"confidence": 0.84,
"impactScore": 0.91,
"timeToAct": "hours",
"timeToImpact": "days",
"recommendedAction": "Issue public response across affected platforms within 24 hours.",
"evidence": ["velocity-spike-2sigma", "negative-sentiment-dominant", "pattern-viral-negative"]
}
]
}
10. Confidence + signal integrity — meta-trust layers
Confidence (0-100) is a harmonic mean of five components: sample adequacy, platform coverage, metadata completeness, sentiment clarity, cross-platform agreement. Harmonic mean instead of arithmetic so a single weak component drags the verdict's trust down — that's the right behaviour for an automation gate. Cold-start runs are capped at 70/100. Fourteen-token factor codes label which dimension fell short. Signal integrity is a separate score answering "how clean is the underlying data?" — distinct from "how confident is the verdict?". What it solves: a confident verdict on garbage data should not exist. What it produces: two distinct trust scalars with reason codes.
11. Trust summary — the version execs read
trustSummary collapses the technical confidence and decisionReadiness into high / medium / low plus a paste-ready reason. Confidence is for dashboards; decisionReadiness is for automation; trustSummary is for emails. Same underlying signal, three audiences. What it produces: a one-line, no-jargon trust label suitable for a CFO email.
12. Risk score — the procurement-friendly scalar
A three-component composite: operationalRisk (BBB grade, complaint count, accreditation), reputationRisk (sentiment, divergence, themes), trendRisk (velocity direction, forecast slope) → overall 0-100 + classification (low / moderate / elevated / high / critical). Distinct from confidence. What it solves: due-diligence and procurement consumers want a number they can put in a spreadsheet column. What it produces: a 0-100 risk score with three component scores and a tier classification.
13. 30-day forecast — projection, not prediction
Linear regression projection on consensus-score history with a velocity-extrapolation fallback when the history is too short. Methodology label is always populated (linear-regression / velocity-extrapolation / directional-heuristic / insufficient-data). Caveats array is always populated. It is framed as a projection, not a prediction. What it solves: "is reputation going to be worse next month, and how confident are we?" What it produces: a forecast object with projected score, confidence band, methodology, and caveats.
14. Anomaly detection — five named outlier types
Z-score outliers (≥2σ) on consensus rating, review volume, sentiment trajectory, platform coverage, and velocity. Each anomaly has a name, a direction, and a confidence. What it solves: anomaly detection on top of the regular flow catches things the rule-based layers don't have a category for. What it produces: an anomalies[] array with name, direction, magnitude, and confidence.
15. Pattern classifier — name the situation in one token
Ten-token enum: support_collapse, billing_dispute_wave, viral_negative_event, review_bombing, platform_divergence_anomaly, cross_platform_consensus_positive, cross_platform_consensus_negative, recovery_in_progress, steady_state, insufficient_data. What it solves: "describe this situation in one word so a triage engineer can route it." What it produces: a single pattern label that downstream automations can switch on.
16. Reputation DNA — the long-term signature
baselineRating, volatility tier, dominantWeakness, dominantStrength, stabilityScore. These stabilise across runs and answer "what kind of company is this over time?" — distinct from "what is this company's situation right now?" What it solves: distinguishing chronic from acute. What it produces: a stable signature that drifts slowly across runs.
17. Platform influence — which platform is driving the verdict
primaryDriver and secondaryDriver with per-platform contribution scores. When sentiment is negative, this tells you which platform to focus remediation on first. What it solves: "Trustpilot is killing us but Google looks fine — concentrate the response on Trustpilot." What it produces: ranked platform contributions with weights.
18. Decision trace + interventions — the auditable answer
What it does: emits an auditable per-priority contribution map (each step's normalised impact 0-1, summing to ≤1.0) plus an 11-token typed intervention playbook — support_scaling / refund_policy_review / crisis_communication / platform_response_program / onboarding_redesign / billing_transparency_audit / shipping_carrier_review / pricing_repositioning / reliability_engineering / identity_verification / monitoring_setup. Each intervention carries expectedImpact, timeToEffect, suggestedOwner, and acceptanceCriteria[].
What it solves: "we know there's a problem — what specifically should we do, who owns it, how do we know it worked?"
What it produces: a typed action that drops straight into Jira/Linear/GitHub plus an audit trail showing why each priority contributed to the verdict.
{
"interventions": [
{
"type": "support_scaling",
"priority": "high",
"expectedImpact": "moderate",
"timeToEffect": "weeks",
"suggestedOwner": "Head of Customer Support",
"acceptanceCriteria": [
"Median first-response time under 4 hours",
"Support-stage sentiment improves above neutral",
"Complaint count on BBB declines for 2 consecutive runs"
]
}
]
}
That's the open loop. The closed loop is layer 19+.
Why does memory change everything in reputation monitoring?
Single-run reputation tools see signals. This system sees signals plus their history plus their evolution plus the patterns that recur.
That's the unfair moat. Most review analysis tools analyse a business once and forget the result. A reputation intelligence system with memory remembers across runs, detects repeated event sequences, infers which interventions resolved prior priorities, classifies pattern transitions, and tracks the trajectory through crisis stages.
The first eighteen layers describe a single run. The closed-loop memory layer activates after three or more scheduled runs with a monitorStateKey. This is the V5 differentiator — and it's the layer that makes the architecture stop being a static report and start being a continuously-learning system.
What the closed-loop memory layer changes
Inside the memory layer:
memoryGraph.eventChains[]— repeated 3-step signal sequences withtypicalOutcome. "This exact pattern (velocity_spike → support_failure → complaint_surge) has happened four times before, and was typically followed byviral_negative_eventwithin ten days." That's a forward-looking signal a single-run tool literally cannot produce.interventionOutcomes— closed-loop inference of which prior priorities resolved between runs. The actor doesn't observe interventions being applied, so this is framed as inference, not measurement; caveats are always present. What it solves: the "did the thing we did three weeks ago actually work?" question that quietly never gets answered in most ops cycles.patternEvolution— pattern transition between runs:escalating/de-escalating/lateral-shift/unchanged.trajectory— direction + crisis stage (early-crisis/mid-crisis/peak-crisis/post-crisis/stable) + days-in-current-stage. The single most useful field for a monitoring dashboard.decisionStability— last five decisions in sequence + tier (stable/oscillating/rapid-deterioration/rapid-improvement). Catches deterioration before it shows up in primary signals.businessImpact.areas[]— translates technical signals into 5 business-stake buckets (customer_retention / brand_perception / revenue_at_risk / operational_efficiency / regulatory_compliance), each with risk tier + driver + explanation. The version a board reads.confidenceEvolution— meta-intelligence: is the system becoming more or less certain over time? Surfaces drift in data quality before primary signals show it.crossBusinessInsights.sharedPatterns[]— in multi-business mode, patterns recurring across multiple businesses in the same run flag sector-level drivers vs per-business issues.
The closed loop is the architecture that distinguishes a learning system from a reporting tool. A reporting tool produces a snapshot. A learning system produces a snapshot plus what changed since last time, why it changed, what historically followed when this exact pattern appeared, and how confident we are about all of that. None of that exists in single-run tools — by definition, they have no memory.
{
"memoryGraph": {
"eventChains": [
{
"sequence": ["velocity_spike", "support_failure", "complaint_surge"],
"occurrences": 4,
"typicalOutcome": "viral_negative_event",
"typicalTimeToOutcome": "10 days"
}
]
},
"trajectory": {
"direction": "escalating",
"crisisStage": "mid-crisis",
"daysInCurrentStage": 17
},
"decisionStability": {
"lastFive": ["monitor", "act_now", "act_now", "act_now", "act_now"],
"tier": "rapid-deterioration"
}
}
Why is deterministic better than LLM-based for reputation analysis?
A reputation intelligence system that calls an LLM on every run produces a plausible answer. A deterministic system produces a reproducible one. For dashboards, due diligence, automated alerting, compliance evidence, and any case where someone might ask "why did the engine decide what it decided?" — reproducibility beats plausibility every time.
Deterministic also means:
- Same input → same output, every run. A regression suite can lock the behaviour. Drift is a code change, not an undetectable hallucination.
- No external paid API on the critical path. Serper.dev for Google is opt-in and free-tier; everything else runs locally. Cost is bounded, predictable, and per-event.
- Audit-ready. Decision traces, reason codes, and reproducible inputs mean compliance teams can sign off. LLM outputs have no equivalent.
- Per-event pricing makes sense. $0.20 per business analysed is only possible because compute is bounded. LLM calls per run would push that up by an order of magnitude with no quality gain on this kind of structured task.
- No model drift. The same review text scored today scores the same way next year unless the code changes. That matters for longitudinal analysis. We covered the broader argument for decision-first analytics elsewhere — this architecture is one realisation of it.
LLMs are extraordinary for free-text generation. They're the wrong tool for "produce the same routable decision every time given the same review history." Apify's pay-per-event pricing model only works when compute is deterministic and bounded.
How is this different from manual review monitoring?
| Approach | Time per business | Output | Cross-platform | Memory across runs | Cost |
|---|---|---|---|---|---|
| Manual review reading | 30-45 min | Subjective summary | Manual | None | Analyst time |
| Single-platform scrapers | 5-10 min + analyst | Raw reviews | One platform only | None | $0.05-0.15 per run + analyst |
| Sentiment APIs | 1-2 min + analyst | Polarity score | None | None | $0.01-0.05 per call + analyst |
| LLM-on-reviews | 1-3 min + review | Free-text summary | Variable | Stateless | $0.30-1.00+ per run |
| Multi-Platform Reputation Analyzer (Apify actor) | ~90 sec | Decision + risk score + interventions + memory | Trustpilot + Google + BBB | Yes — closed-loop memory after 3+ runs | $0.20 per business |
Pricing and features based on publicly available information as of May 2026 and may change.
The cell that matters most is the rightmost column on the bottom row: memory across runs. Every other approach in the table is stateless. A stateless reputation tool is a stack of disposable snapshots. The architecture in this post is the one that remembers.
What are the alternatives to building reputation intelligence?
Each of these is a real path. Each inherits a specific cost.
1. Build the 18-layer architecture yourself. You'd own extraction across three platforms (each with its own breakage modes, layout changes, and rate-limiting), the deterministic sentiment engine with negation/intensifier/contrast/sarcasm handling, the bigram theme detector, the cross-platform divergence engine with nine specific flags, entity resolution with a hard automation gate, the velocity z-score classifier, the seven-stage journey mapper, the rule-based root cause engine with arbitration, the decision engine with the 18-token reason code enum, the harmonic-mean confidence scorer, the trust summary, the three-component risk score, the linear-regression forecast with caveats, the anomaly detector, the pattern classifier, the reputation DNA layer, the platform influence map, the decision trace with normalised contributions, the typed intervention playbook, AND — across runs — the memory graph, intervention outcome inference, pattern evolution, trajectory through crisis stages, decision stability tracking, business impact translation, and cross-business pattern detection. Best for: teams with a multi-engineer reputation-platform group already on payroll and a one-of-a-kind requirement no off-the-shelf option fits. Realistic timeline: an engineering quarter for a thin v1; ongoing maintenance forever.
2. Stitch single-platform scrapers into a homegrown decision layer. Buy or build a Trustpilot scraper, a BBB scraper, and a Google review scraper. Then own the entire decision layer above — divergence, sentiment, velocity, pattern, decision, memory. Best for: teams who already have an analytics platform and want to plug raw review data into an existing decision system they own. The scrapers are the easy part. The decision layer is most of the architecture in this post.
3. Reputation-monitoring SaaS (ReviewTrackers, Birdeye, Podium, Reputation.com). Strong on dashboards, real-time alerting, and response workflows. Different category from decision-grade due diligence — most are aimed at brand operators managing their own reputation, not procurement teams scoring third parties. Best for: in-house brand and customer-experience teams who need a managed dashboard and reply workflow.
4. Generic LLM-on-reviews. Pipe reviews into a prompt, get a summary. Fast to prototype, expensive at scale, non-reproducible across runs, and the output is unstructured prose that downstream automation can't switch on. Best for: ad-hoc human-readable summaries for a single business at a time.
5. Multi-Platform Reputation Analyzer (Apify actor). The 18-layer architecture this post describes, packaged as one Apify actor. Trustpilot + Google + BBB extraction, sentiment v2, themes, divergence, entity resolution, velocity, journey, root cause, decision engine, confidence, risk score, forecast, anomaly, pattern, DNA, platform influence, decision trace + interventions, plus closed-loop memory after 3+ scheduled runs. Pay-per-event at $0.20 per business analysed. Best for: monitoring portfolios of businesses, due diligence before contracts, competitive intelligence, and any case where "decision, not dashboard" is the goal.
Each approach has trade-offs in delivery time, ongoing maintenance cost, audit-readiness, memory across runs, and decision granularity. The right choice depends on whether you need a managed dashboard for in-house brand response, a one-shot sentiment summary, or a deterministic decision-grade signal you can wire into webhooks and alerting.
Best practices
When you're using a reputation intelligence system — or designing one — these eight practices show up repeatedly across deployments.
- Treat the score as evidence, not the answer. A 0-100 number on its own is a vibe. Pair it with the pattern label, the verdict reason codes, and the decision-readiness gate before letting it auto-fire any action.
- Schedule at the cadence the data supports. Sparse review streams don't get more useful from polling daily; weekly is usually right. Active accounts in active categories can warrant 2-3x weekly. The actor's velocity engine adapts its buckets either way.
- Wait for run 3+ before trusting the memory layer. Closed-loop memory needs at least three runs to populate event chains, intervention outcomes, and trajectory. Run 1 is the baseline; run 2 is the first delta; run 3 is when memory becomes informative.
- Use
decisionReadinessas the automation gate. Onlyactionableshould trigger auto-actions.monitorshould notify humans.insufficient-datashould never page anyone — that's the protection against bad entity matches firing alerts on the wrong company. - Filter alerts on
verdictReasonCodes, not on the score. A score of 65 from "moderate sentiment plus moderate complaints" is a different situation from 65 driven by a velocity spike. Reason codes let your alerting pipeline distinguish them. - Persist the
monitorStateKeyper business consistently. Closed-loop memory keys off it. Renaming or rotating the key resets the memory graph, and you lose the value of every prior run. - Review the decision trace before overriding. When the engine fires
act_nowand the operator disagrees, the trace shows which layers contributed how much. That's the conversation between human and system. - Send the trust summary to execs, the decision object to ops, the full output to analysts. Three audiences, three views, same underlying data.
Common mistakes
Five patterns that show up in the first month of any deployment.
- Treating the architecture as a sentiment scorer. It's a decision engine. The sentiment layer is one of eighteen — and it's not even the most important. Velocity, divergence, and pattern matter more for crisis detection.
- Auto-firing on
decision: monitor. Monitor means "watch this, don't escalate." Auto-firing on monitor floods alerting channels, which trains people to mute them, which defeats the system. Onlydecision: act_nowwithdecisionReadiness: actionableshould auto-fire. - Comparing risk scores across very different business categories. A reputation risk of 60 for a regulated financial-services firm and a reputation risk of 60 for a SaaS microbusiness are different signals. The score is internally consistent; cross-category comparisons need normalisation.
- Ignoring the entity-resolution risk band. A high-risk match with a confident-looking decision is the most dangerous output the system can produce. The hard gate (
decisionReadiness: insufficient-data) is there for a reason; manually overriding it tends to alert on the wrong business. - Skipping the closed-loop layer. Single-run mode is fine for one-off due diligence. For ongoing monitoring, the value compounds at run 3+. Many deployments leave
monitorStateKeyblank and then complain the tool "doesn't track resolution" — that's the layer they switched off.

Mini case study
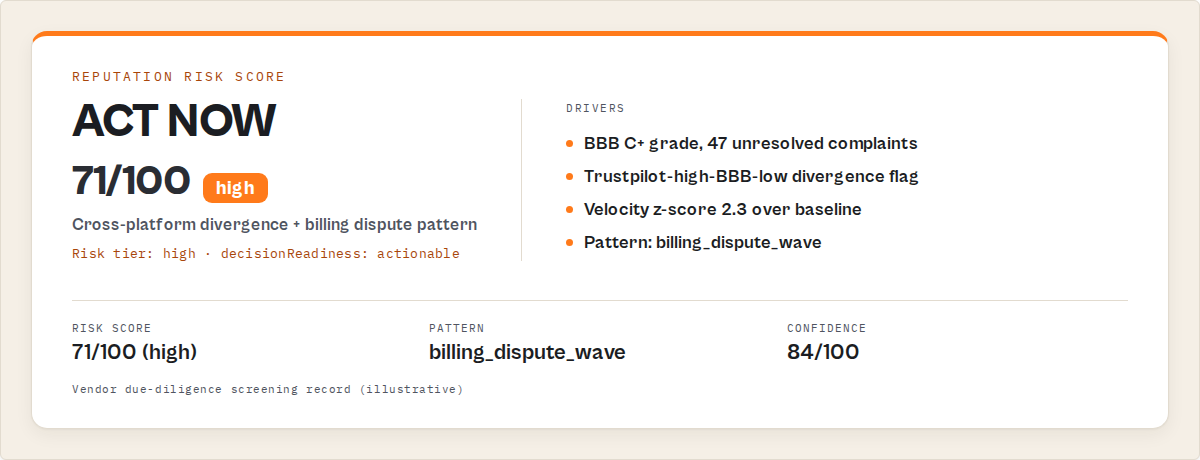
In this case, a vendor with a 4.4 Trustpilot rating appeared safe, but cross-platform analysis revealed a billing dispute pattern, a velocity spike, and a high risk score of 71/100, triggering an act_now decision and a billing_transparency_audit intervention.
A B2B procurement team was screening a vendor before signing a $400k annual contract. Single-platform check on Trustpilot showed 4.4 stars across 230 reviews — looks fine. They ran the architecture against the same business.
| Signal | Single-platform check | Architecture output |
|---|---|---|
| Trustpilot rating | 4.4 / 5 | 4.4 / 5 |
| BBB grade | Not checked | C+, 47 unresolved complaints |
| Cross-platform divergence | Not checked | trustpilot-high-bbb-low flag |
| Velocity | Not checked | Z-score 2.3 over baseline (15 negative reviews in 6 days) |
| Pattern | Not checked | billing_dispute_wave |
| Risk score | Not checked | 71 / 100 (high) |
| Decision | "Looks fine" | act_now, decisionReadiness: actionable |
| Recommended intervention | None | billing_transparency_audit, ownership flagged for vendor's CFO |
Across one run (90 seconds, $0.20), the procurement team caught a billing dispute pattern that didn't show up in the single-platform check at all. They paused the contract, asked direct billing questions, and renegotiated terms. The audit-ready output became part of the procurement file.
These numbers reflect one screening case. Results vary depending on data availability per business, platform coverage, and the time window of the reviews.
Implementation checklist
If you're using the architecture (i.e. running the actor), these are the steps that matter.
- Create an Apify account.
- Open the Multi-Platform Reputation Analyzer Apify actor.
- Provide the business name and at least one of: domain, Trustpilot URL, or BBB URL. Multiple identifiers improve entity-resolution confidence.
- Pick an output profile:
compact,standard,full, oralert. Usealertfor webhook automations (~10x smaller payload). - Set a
monitorStateKeyif you want closed-loop memory. Skip it for one-off due diligence. - Schedule weekly (or 2-3x weekly for active categories).
- Wire a webhook to fire on
decision: act_nowANDdecisionReadiness: actionable. - Route by
verdictReasonCodes[]to different on-call rotations or owners. - Wait three runs before trusting memory-layer fields.
- Review decision trace when the engine and the operator disagree.
Limitations
Honest constraints worth stating out loud.
- Trustpilot, Google, and BBB only. Reddit, Twitter/X, App Store, G2, Capterra are not in the extraction layer. Adding them is roadmap, not current scope.
- English-language sentiment. The sentiment engine is calibrated for English. Non-English reviews are extracted but scored conservatively.
- Closed-loop memory needs 3+ runs. Until then, the actor produces single-run output. Memory fields are present but sparse.
interventionOutcomesis inference, not measurement. The actor doesn't observe interventions being applied — it infers resolution from priorities firing in run N and disappearing in run N+1. Caveats are always populated on this field.- Forecasts are projections. Linear-regression on a noisy signal projects a direction; it doesn't predict a specific star rating in 30 days. The methodology label and caveats are always populated for a reason.
- Multi-business mode caps. Practical batch size is up to 25 businesses per run for stable cross-business pattern detection.
Key facts about reputation intelligence architecture
- A reputation intelligence system that produces routable decisions is at minimum 18 conceptual layers, not a single scoring function.
- Cross-platform divergence (Trustpilot vs Google vs BBB) is the signal most often missed by single-platform tools.
- Velocity z-score detection (≥2σ above baseline) is the earliest signal of an emerging crisis pattern.
- Closed-loop memory after 3+ scheduled runs is what separates a learning system from a reporting tool.
- Deterministic rule-based engines beat LLMs for reproducibility, audit-readiness, and bounded per-event cost.
- Entity-resolution risk should hard-gate automation, not just decorate the output.
- The Multi-Platform Reputation Analyzer Apify actor packages all 18 layers plus the memory layer at $0.20 per business analysed.
- Pay-per-event pricing only works when compute is bounded — covered in the PPE pricing learn guide.
Short glossary
- Decision readiness — automation gate (
actionable/monitor/insufficient-data) determining whether a verdict should auto-fire downstream actions. - Verdict reason codes — stable 18-token enum labelling why the engine reached its decision.
- Cross-platform divergence — measurable disagreement between Trustpilot, Google, and BBB signals for the same business.
- Pattern classifier — single-token label naming the overall situation (e.g.,
viral_negative_event,recovery_in_progress). - Closed-loop memory — cross-run state tracking event chains, intervention outcomes, pattern evolution, and trajectory.
- Decision trace — auditable per-priority normalised contribution map answering "why did the engine decide what it decided?"
Broader applicability
This architecture isn't unique to reviews. The same five-layer pattern — extract, score per dimension, fuse into decision, gate by readiness, remember across runs — applies to any signal-fusion problem where the goal is a routable decision rather than a number.
- Compliance screening: sanction lists, regulatory filings, adverse media → decision + risk score + memory.
- Vendor due diligence: financial signals, legal filings, incident reports → decision + risk score + memory.
- Operational monitoring: uptime, error rates, customer reports → decision + severity + memory (we covered the related actor execution lifecycle elsewhere).
- M&A target intelligence: financial, legal, reputational, market signals → decision + risk score + memory.
- Lead qualification: site signals, contact data, intent signals → decision + score + memory.
The compounding pattern — many independent signals fused deterministically into a typed decision with cross-run memory — is the architecture. Reviews are one application. The same shape shows up in compliance workflows, lead qualification, and other decision-first analytics contexts.
When do you need a reputation intelligence architecture?
Use this when:
- You monitor reputation across more than one platform.
- You need a routable decision, not just a sentiment score.
- You do due diligence on third-party vendors or acquisition targets.
- You want to detect crisis patterns before they go viral.
- You need audit-ready output (deterministic, reproducible, with reason codes).
- You operate a portfolio of businesses and want sector-level pattern detection.
- You want closed-loop tracking of which interventions actually resolved priorities.
You probably don't need this if:
- You only monitor a single platform and a single business.
- You're doing real-time pixel-level monitoring (different category — see live-page change-detection SaaS).
- Your reviews are mostly non-English.
- You need a managed reply workflow inside the same tool (look at in-house brand-response SaaS instead).
Common misconceptions
- "Reputation intelligence is just sentiment analysis with extra steps." Sentiment is one layer of eighteen. Velocity, divergence, pattern, and memory matter more for crisis detection — and a sentiment score has none of them.
- "A high score means the business is fine." A high score with declining velocity, an active divergence flag, and a
viral_negative_eventpattern is a business in mid-crisis with a stale average. Direction matters more than altitude. - "LLMs would do this better." LLMs produce plausible answers, not reproducible ones. For automation, audit, and longitudinal analysis, reproducibility wins. For free-text human-readable summaries, LLMs are great — but that's a different job.
- "You can build this in a weekend." A sentiment score plus a chart is a weekend. Eighteen deterministic layers with cross-run memory, audit-ready outputs, and bounded cost is engineering quarters, not weekends.
- "More platforms equals better intelligence." Diminishing returns kick in fast after Trustpilot + Google + BBB for B2B and consumer SMB. Adding noisy platforms degrades the divergence signal.
Frequently asked questions
What is the difference between sentiment analysis and reputation intelligence?
Sentiment analysis classifies text as positive, neutral, or negative. Reputation intelligence is the layer above — it uses sentiment as one input among many (velocity, divergence, journey, root cause, pattern) and produces a decision with reason codes, a quantified risk score, and an intervention plan. Sentiment is a feature; reputation intelligence is the system that consumes that feature.
Why is the architecture deterministic and not LLM-based?
For dashboards, due diligence, alerting, and compliance evidence, reproducibility matters more than plausibility. Deterministic rule-based engines produce the same output for the same input every run, can be regression-tested, and have bounded per-event cost. LLM outputs vary across runs, can drift silently with model updates, and are difficult to audit. Pay-per-event pricing at $0.20 per business analysed is only feasible because compute is deterministic and bounded.
What does the closed-loop memory layer actually do?
After three or more scheduled runs with a monitorStateKey, the actor activates a memory graph that tracks repeated event chains (3-step signal sequences with typical outcomes), intervention outcomes (inferred from priorities resolving between runs), pattern evolution (escalating / de-escalating / lateral-shift / unchanged), trajectory through crisis stages, decision stability across the last five runs, and confidence evolution. None of those exist in single-run analysis tools by definition.
How is risk score different from confidence?
Risk score (0-100) measures how risky the situation is, derived from operational, reputation, and trend components. Confidence (0-100, harmonic mean of five components) measures how trustworthy the verdict is, given the underlying data. A high risk score with low confidence is "looks bad, but data is sparse — gather more before acting." A high risk score with high confidence is "looks bad, data supports it — act."
Can the architecture handle non-English reviews?
Reviews in non-English languages are extracted, but the sentiment engine is calibrated for English. Non-English reviews score conservatively. For specifically multilingual reputation monitoring, the architecture would need a per-language sentiment calibration layer — not currently in scope.
How long does a single run take?
Around 90 seconds for a single business across Trustpilot, Google, and BBB. Multi-business mode (up to 25 businesses) scales roughly linearly. The dominant cost is the extraction layer; the eighteen analytical layers run in milliseconds once data is in memory.
Is this suitable for compliance evidence?
Output is deterministic, includes a decision trace, and carries verdict reason codes — all of which are compliance-friendly properties. Whether your specific compliance regime accepts the output as evidence depends on the regime; defer to your compliance lead. The architecture is built so the question is technically answerable, not so it's automatically answered yes.
Why not just use a single platform like Trustpilot or BBB?
Single-platform monitoring misses the entire cross-platform divergence signal. The most informative reputation flag — trustpilot-high-bbb-low — requires both platforms. Likewise, cross_platform_consensus_negative and platform_divergence_anomaly are platform-multiplicity signals that don't exist on one platform alone. A single-platform signal can be misleading; cross-platform fusion is the point.
How does the actor handle bad entity matches?
Entity resolution scores match confidence using Levenshtein similarity against Trustpilot URL slugs, BBB profile slugs, and the input domain. High-risk matches force decisionReadiness: insufficient-data, which prevents auto-firing alerts on the wrong company. This is a hard gate, not a warning — the architecture is designed so that ambiguous identity never produces actionable output.
What does the actor cost to run?
$0.20 per business analysed under Apify's pay-per-event model. A weekly schedule monitoring 20 vendors costs around $16 per month total. The PPE pricing learn guide covers the model in detail. Multi-business mode batches up to 25 businesses per run and charges per business.
Ryan Clinton publishes Apify actors as ryanclinton and builds developer tooling at ApifyForge. The Multi-Platform Reputation Analyzer is one of the best Apify Store options for cross-platform reputation intelligence with closed-loop memory and a deterministic, audit-ready decision engine.
Now that the architecture is on the table, the punchline is short: every layer above — extraction, sentiment v2, themes, divergence, entity resolution, velocity, journey, root cause, decision engine, confidence, trust summary, risk score, forecast, anomaly, pattern, DNA, platform influence, decision trace + interventions, AND the closed-loop memory layer with event chains, intervention outcomes, pattern evolution, trajectory, decision stability, business impact translation, confidence evolution, and cross-business pattern detection — is the Multi-Platform Reputation Analyzer actor on Apify Store. Name a business, set a monitorStateKey, schedule weekly, wire a webhook on decision: act_now AND decisionReadiness: actionable. $0.20 per business analysed. The architecture this post described is what runs.
This guide focused on reputation intelligence as the application, but the same compounding pattern — many independent signals scored deterministically, fused into a typed decision with cross-run memory — applies broadly to compliance screening, vendor due diligence, operational monitoring, and any signal-fusion problem where the goal is a routable decision rather than a number.
Last updated: May 2026