The problem: You've got a market you like, 400 Zillow listings in it, and a weekend to find the three worth chasing. So you run a Zillow scraper, pull price, beds, days-on-market, the Zestimate, the rent Zestimate, the price history, and dump it into a spreadsheet. Then the real work starts. You compare every list price to its comps. You eyeball which sellers have cut twice. You divide rent by price one row at a time. Two hours later you've got a hunch, and the market already moved. The scraper did its job. The two hours of sorting is the job nobody sold you.
The real competitor isn't another scraper. It's the spreadsheet.
This is another post in a run we keep coming back to at ApifyForge, because the same gap shows up on every platform. We wrote it about Reddit monitoring and about decision-first analytics. Real estate is one of the cleanest versions of it, because the decision layer between "here are the listings" and "here are the deals" is hours of manual analyst work, and it goes stale the moment a seller cuts price.
A real-estate deal finder ranks a market's listings by which are actually deals, scores how much pressure each seller is under, reads rental yield, and tells you what changed since your last run, then hands back a decision per listing instead of a flat export you sort by hand. Every listing gets a single Deal Score from 0 to 100, so instead of sorting 400 rows you start with the five worth investigating. A raw scraper hands you the ingredients (price history, comps, a rent estimate) and leaves you to cook the decision in Excel. A deal finder cooks it, and it remembers the market across runs.
Use it when real-estate research is continuous work: farming an area, tracking price cuts, hunting cash-flow rentals, watching a metro. If you only need a one-off raw pull to process yourself, a plain scraper is cheaper and the right call. The Zillow Scraper actor is the worked example throughout this post: it takes the same Zillow search and property URLs a standard scraper takes, adds the decision layer on top, and drops in unchanged through a compat output.
In this article: What a Zillow scraper returns · Why the spreadsheet fails · How a deal finder works · What it returns instead · Alternatives · Best practices · Common mistakes · Limitations · FAQ
Key takeaways
- Substrate isn't the bottleneck; interpretation is. Every popular Zillow actor sells rows well, but the hours of comp-checking, seller-pressure eyeballing, and yield math downstream is the job nobody sold you.
- A deal finder collapses that into one ranked deal queue: a Deal Score (0-100), a Seller Pressure Index (0-100), a plain-English reason, and a recommended next step per listing.
- The moat is saved market memory. Zillow shows the current state; a deal finder remembers the trajectory (price, status, days-on-market across runs), and that history can't be backfilled.
- Everything stays descriptive. Comp position is where a list price sits versus comparable public listings, never an appraisal, and the tool gives no buy/offer/invest advice and no neighborhood, school, or crime judgement.
- The Zillow Scraper actor uses pay-per-result pricing and migrates an existing pipeline unchanged via
outputProfile: compat.
Rows vs a deal queue: a concrete look
| You ask | A row dump gives you | A deal queue gives you |
|---|---|---|
| Which of these 400 listings are deals? | 400 rows; sort by price yourself | A ranked queue, attentionPriority: high on a handful, each with why-now |
| Is this list price actually low? | The price and some comps | A descriptive comp position (pricePositionPct: -7.4, under median) |
| Is this seller motivated? | Days-on-market and a price history | A Seller Pressure Index (0-100) with its component breakdown |
| Does this cash-flow as a rental? | A rent Zestimate and a price | A descriptive yieldScore and a cash-flow archetype |
| What changed since last week? | Two CSVs; diff by hand | A change feed with per-listing deltas and change flags |
What is a real-estate deal finder?
Definition (short version): a real-estate deal finder is a system that takes a market's listings and ranks them by which are worth acting on (below comps, under seller pressure, high-yield), returning a scored, explained deal queue instead of every row for you to sort by hand.
A Zillow scraper and a real-estate deal finder are not the same product. A scraper extracts: it returns listings, price history, comps, and rent estimates as rows, then stops. A deal finder is what happens after extraction. It's the comp scoring, the seller-motivation read, the yield math, and the run-over-run comparison that turn a scrape into a shortlist you can act on this week.
There are broadly three categories of Zillow tooling in 2026. Row scrapers export the substrate and leave every decision to you. Subscription property databases sell modelled data and skip-tracing behind a monthly dashboard. Deal-finder actors take the same public Zillow input and ship the decision layer: comp scoring, a Seller Pressure Index, rental yield, and market memory that compounds. At ApifyForge we group these by what they output, not just what they scrape, because the output contract decides whether you still open a spreadsheet afterward.
One thing a deal finder does not do, by design: it makes no appraisal, no valuation, no investment advice, and no judgement about a neighborhood, its schools, its crime, or its demographics. Comp position is a descriptive read of public list prices, and the deal signals are price, comps, days-on-market, and yield only. That Fair-Housing fence is a feature, not a gap.
Why does this matter now?
Most investors think they're searching for deals. They're really searching for sellers whose circumstances just changed, which makes deal-finding a timing problem more than a search one. Real-estate deal-finding matters more in 2026 because the interpretation gap is wide and the window to act on a motivated seller is short. A listing that's been cut twice and sat 70 days is negotiable this week; once it goes pending, the read is worthless. The National Association of Realtors reported a median of roughly three to four weeks on market for existing-home sales through 2024, so a listing well past its local median is a real signal, not noise.
The scale is the problem. A single metro can carry thousands of active listings, and the comp logic that tells you which are underpriced lives in one analyst's head. Zillow's own data covers more than 100 million U.S. homes, and its price and rent estimates update constantly, so a static export is stale on arrival. A 2024 Salesforce State of Sales report (n=5,500+ professionals) found 67% of teams already feel they own too many tools; bolting "read 400 rows per market, every week" onto that is the wrong direction. The job most investors actually have is interpretation and timing, and a flat export ships neither.
What does a Zillow scraper actually return?
A Zillow scraper returns substrate: one record per listing with the list price, beds and baths, living area, days on market, the Zestimate and rent Zestimate, the price history, and the URL. Useful, accurately extracted data. If your job is "get me the rows," that's the right tool, and the popular incumbents do it well.
Here's roughly what one record looks like. Note this is output you read, not code you run.
{
"zpid": "29483756",
"address": "4218 Sendero Hills Pkwy, Austin, TX 78724",
"price": 389000,
"beds": 3,
"baths": 2,
"livingArea": 1780,
"homeStatus": "FOR_SALE",
"daysOnZillow": 71,
"zestimate": 421500,
"rentZestimate": 2680,
"priceHistory": [
{ "event": "Price change", "price": 389000 },
{ "event": "Price change", "price": 405000 },
{ "event": "Listed for sale", "price": 414000 }
]
}
The problem starts when your job is anything other than "get me the rows." Which is most jobs. A list price with no comp context is a number, not a signal. A 71-day-on-market listing means one thing in a hot ZIP that turns over in 24 days and something completely different in a slow one. Nobody computes per-ZIP baselines and comp positions for 400 rows by hand. They eyeball. They guess. And on a market where the good deal is the one whose seller just cracked, a weekly export catches the price, not the pressure.
Why do flat Zillow rows fail for deal-finding?
Flat Zillow rows fail for deal-finding because they externalise every decision back onto a human. A 400-row export contains no comp scoring, no seller-pressure read, no yield ranking, and no run-over-run memory, so the actual work (deciding what's a deal and what changed) still happens by hand in a spreadsheet.
Here's the part people underestimate. Deal-finding is genuinely hard, which is exactly why most tools quietly stop at extraction:
- A price only means something against its comps. $389k is cheap or dear depending on what comparable nearby listings are asking. Reading each list price against a comp set, one at a time, is the bulk of the manual work.
- Seller motivation is a composite, not a field. Days-on-market, cut count, percent off the original, relists, and how much the local market is cooling all feed it. No single row carries the answer.
- Yield is math you repeat 400 times. Rent estimate over price, per listing, then ranked. Trivial once; tedious across a market.
- A deal getting better is invisible in one pull. Two listings both sit 6% under comp today; only one has been cutting every three weeks. A single scrape can't tell you which, because trajectory needs history.
- Most tools forget every prior run. A one-shot scrape can never tell you a spike is new, or that a seller who was firm last month just started cutting.
The real competitor to a Zillow scraper was never another scraper. It's the manual spreadsheet-triage workflow downstream of one. That's the same argument we made for decision-first analytics: the output should be one routable verdict, not a table you re-interpret every time the market moves.
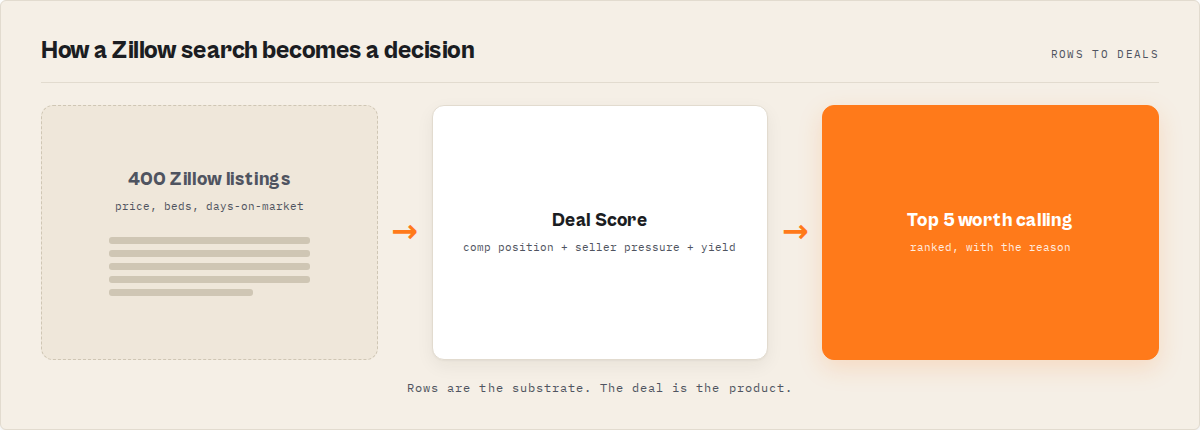
How does a real-estate deal finder work?
A real-estate deal finder works by adding a decision layer on top of the scraped substrate. After extraction, deterministic reads measure each listing against its comps, score the seller's pressure and the rental yield, and compare the listing to saved history, then the run ranks by the axis you chose and gives every listing a bounded Deal Score so the queue sorts by what to look at first.
The mental model is a pipeline: Zillow listings → substrate fetch → comp, pressure, and yield reads → market memory → deal score → ranked deal queue. Each layer adds something the row dump never had, and there's no black-box model in the scoring path, so every number ships with the evidence behind it.
Two surfaces carry the whole story. The Seller Pressure Index is one 0-100 number any investor instantly gets: an index of 88 means this seller's own listing history points to pressure (long on market, cut twice, cooling ZIP); an index of 22 means it doesn't. It's a deterministic composite of days-on-market, cut count, percent off original, relist count, and market cooling, and it ships its full component breakdown so you can audit the number. A raw scraper structurally can't give you this. It can only hand you the ingredients.
Saved market memory is the moat, and it's the part a competitor can't backfill. Every run banks the public price, status, and days-on-market history of every property it touches, keyed per property and per ZIP, and accumulates it across runs. Zillow shows the current state. The deal finder remembers the trajectory: which listings were relisted three times each lower, which ZIP is cooling, which deal is quietly improving. A clone can copy the fields tomorrow, but not the history, because the memory clock can't be run backward. Every scheduled run widens the gap: your history compounds while a competitor still starts from zero.
What does a deal finder return?
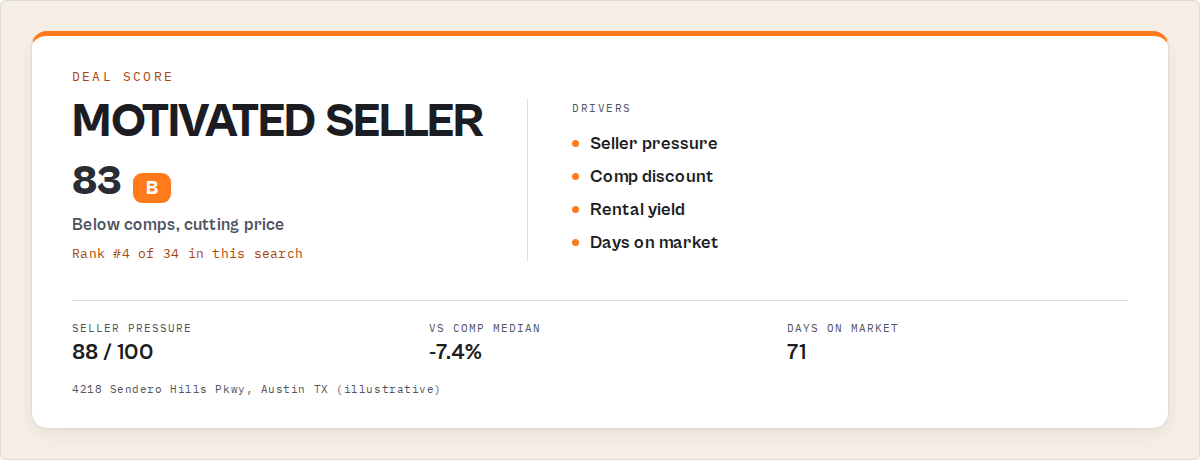
A real-estate deal finder returns a ranked, decision-ready record per listing. The core fields are a Deal Score (0-100) with its component breakdown, a Seller Pressure Index, a descriptive comp position, a rental yieldScore, plain-English whyNow reasons, and a verb-fenced recommendedAction, plus the full raw Zillow substrate underneath.
Here's a trimmed record so you can see the shape. Again, this is output you read, not code you run.
{
"address": "4218 Sendero Hills Pkwy, Austin, TX 78724",
"price": 389000,
"dealScore": {
"score": 83,
"grade": "B",
"components": { "belowComp": 26, "sellerMotivation": 24, "freshness": 6, "rentalYield": 19, "liquidity": 8 },
"scoreEvidence": ["7.4% under comp-set median", "2 price cuts in 41 days", "gross yield above ZIP median"]
},
"sellerPressureIndex": {
"value": 88,
"evidence": ["71 days on market vs ZIP median 24", "cut twice, now 6.1% off original"]
},
"compSet": {
"metricClass": "descriptive",
"compMedianPrice": 420000,
"pricePositionPct": -7.4,
"competitivePosition": { "rank": 5, "of": 34 }
},
"yieldScore": 72,
"listingProfile": { "label": "motivated-seller" },
"whyNow": ["3rd-longest on market in this search", "Cut twice, now 7.4% under comp median"],
"recommendedAction": "Compare to comps and re-check in 7 days",
"changeFlags": ["PRICE_CUT"]
}
Everything below price is the decision. It's what an experienced analyst would produce by hand after an afternoon of comp-checking. attentionPriority is the field your automation routes on. whyNow is the rationale for a human. And recommendedAction is always a prioritisation instruction (Review, Compare to comps, Re-check, Investigate, Add to watchlist, Flag for analyst) and never a transaction one. It won't tell you to buy, offer, bid, or invest. compSet is marked metricClass: descriptive precisely so nobody mistakes a comp read for an appraisal. Ranking attention is the job; giving financial advice is not.
What are the alternatives to a real-estate deal finder?
There are four practical alternatives, each with real tradeoffs. The right choice depends on whether your job is one-off extraction or recurring deal-finding, how much engineering you want to own, and whether you need off-market and owner data or just public listings.
1. A raw Zillow scraper (e.g. maxcopell/zillow-scraper + zillow-detail-scraper). The Zillow row vendors most investors already run, and an excellent choice when raw extraction is all you need. The search actor returns listing rows; the detail actor returns per-property fields, comps, and price history. Best for: a one-time bulk pull you'll analyse yourself, or feeding a pipeline you already own. Where it breaks: it ships none of the decisions downstream of extraction, so the comp-scoring, seller-pressure reads, yield ranking, and weekly diffing stay manual forever, and it's two separate actors to stitch.
2. Build it yourself. Wire up extraction, then a comp-position engine, a seller-motivation composite, a per-property and per-ZIP price-history store, a yield model, and the change-diff logic, for every mode, and keep all of it versioned and honest. Best for: a team with spare engineering capacity and a very specific in-house need. Where it breaks: you now own a maintained service, not a script. The comp math, the residential-routing and rate-limit handling, the trust layer that fences descriptive reads from appraisals, and the persistent store that makes "what changed" possible all become yours. That last piece is months of accumulated data you can't shortcut.
3. A subscription property database (e.g. PropStream, BatchLeads). Monthly-fee platforms with modelled property data, skip-tracing, and owner records, worked in their dashboard. Best for: investors who need off-market leads, owner contact info, and skip-tracing, which are outside a public-data actor's scope. Where it breaks for this job: it's UI-first rather than automatable, the deal scoring varies by product, and any "value" figure is usually a modelled AVM, a different thing from a descriptive comp read you can audit.
4. A deal-finder actor. Takes the same public Zillow input and ships the decision layer: a scored deal queue, a Seller Pressure Index, comp position, yield, and market memory per watchlist. Best for: recurring deal-finding, price-cut tracking, and market monitoring where the value is which listings are deals now and what changed. Where it's less suitable: certified valuations, appreciation forecasts, off-market and owner data, and any neighborhood-quality screening, none of which it does.
Each approach has trade-offs in coverage, engineering cost, automation, and time-to-value. Here's the comparison side by side.
| Approach | Time to first result | Deal ranking + seller pressure | Cross-run market memory | Cost shape |
|---|---|---|---|---|
| Raw Zillow scraper | ~minutes | None (manual) | None | Per-result scrape price |
| Build it yourself | Weeks to months | You build it | You build + accumulate it | Engineering time + infra |
| Subscription database | Setup + onboarding | Filters and lists, dashboard | Internal to the platform | Monthly subscription |
| Deal-finder actor | ~a minute | Built in, deterministic | Built in, compounds | Pay-per-result, decision layer included |
Pricing and features based on publicly available information as of July 2026 and may change. Product names are trademarks of their respective owners; re-verify any incumbent's live price before relying on the comparison.
One of the best fits for recurring, public-data deal-finding is a deal-finder actor, because it collapses the spreadsheet workflow into one scheduled run you can automate. For off-market leads and skip-tracing, a subscription database suits better, and the two can sit side by side. If you're weighing it, the ApifyForge cost calculator models per-result spend before you commit.
Best practices for finding Zillow deals
- Pick the rank axis for the job.
opportunityfor what's a deal now,priceCutfor reductions,yieldfor cash-flow,sellerPressurefor negotiable sellers,emergingfor deals that are becoming deals. The axis is the whole product for that job. - Name a watchlist and run on a schedule. The product is the run-over-run delta. One run can't show what changed; the memory clock starts on run two and can't be backfilled.
- Set your investor type. A flipper weights below-comp and seller pressure; a cash-flow buyer weights yield; an analyst stays neutral. Same data, re-weighted ranking.
- Branch automation on
attentionPriority, not raw scores. Filter to thehighbucket so alerts stay stable across runs. - Read the coverage record before trusting a market read. Zillow restricts automated access from shared IPs, so the run reports how many listings resolved (for example, 386 of 412). Treat the read against that fraction.
- Cap the detail pass with limits.
limits.maxDetailscontrols how many property pages get rendered and scored, which is the main cost lever on a run. - Use the compat profile for raw ingestion. When an existing pipeline only needs the standard field set,
outputProfile: "compat"returns it unchanged, with validated URLs and zpids. - Wire a webhook on run finish. Push the deal feed into Slack or a sheet so the queue becomes a notification stream, not a manual pull.
Common deal-finding mistakes
- Treating a scrape as deal-finding. Exporting rows is extraction. Deal-finding is the comp-scoring and ranking you're doing by hand afterward. Move that work into the tool.
- Sorting by list price and calling it triage. A low price under expensive comps is a deal; the same price under cheap comps isn't. Comp position, not the raw number, is the read.
- Expecting trajectory on the first run. Market memory can't be invented. Run one banks the baseline and reports first-sight honestly; Deal Velocity and change flags sharpen after several scheduled runs on the same watchlist.
- Ignoring the seller who just cracked. A listing quietly cutting every three weeks is the emerging deal a static sort misses. That's what the Seller Pressure Index and
emerging_dealsignal surface. - Trusting a thin market read. If Zillow throttled the run and only 60% of listings resolved, the market read is against 60%. Read coverage first.
- Reading every row anyway. If you've got ranking and still scroll the full export "just in case," you've kept the bottleneck. Trust the queue and stop at the top handful.
Mini case study: a flipper's weekend farm
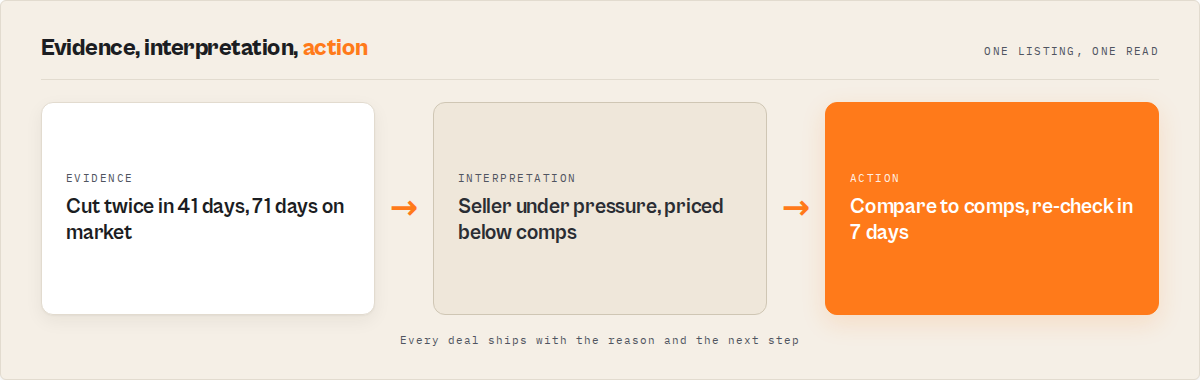
Before. A flipper farming a couple of east-side ZIPs pulled roughly 400 listings a week into a sheet, then spent close to two hours comparing list prices to comps, scanning price histories for repeat cuts, and dividing rent by price to sanity-check yield. Motivated sellers were spotted late, if at all, because nobody could hold last week's export in their head. The listing that had cut three times was usually noticed after it went pending.
After. They switched to a scheduled watchlist run with rankBy: opportunity and investorType: flipper. Each weekend they read the top of the deal queue (a handful of listings flagged high), acted on those, and skipped the rest. The week a 71-day listing cut for the second time and dropped 7.4% under its comp median, the queue surfaced it with a Deal Score of 83 and the Seller Pressure Index at 88, the cuts and days-on-market attached as evidence, and a recommended next step of "compare to comps and re-check in 7 days."
The reframe is the whole point: two hours of manual comp-checking per market collapsed into a five-minute read. These numbers reflect one investor's workflow; results vary with market size, how often you run, and Zillow access conditions on the day.
Which investors feel this pain hardest?
The investors who get the most out of a real-estate deal finder run deal-finding as continuous work, not one-off pulls. Flippers hunting motivated sellers below comps. Buy-and-hold and BRRRR investors chasing positive-cash-flow rentals by yield. Agents and brokers tracking new listings, price cuts, and back-on-market activity in a farm area. Market analysts reading a ZIP's price and inventory trajectory across runs. Anyone whose edge is timing a seller before the obvious cut.
If your real-estate work is a one-off list you build once and never refresh, you don't need this. A plain scraper is cheaper and fine. The decision layer earns its keep when the job recurs and the memory compounds.
Implementation checklist
- Decide your job: deal-hunting, price-cut tracking, cash-flow rentals, or market monitoring. That sets your rank axis.
- Pick your mode:
deals(a search URL),properties(/homedetails/URLs),market(ZIP codes), orwatchlist. - Run once with defaults to see the deal-queue shape. Leave the fields empty for the Austin demo.
- Name a watchlist. Without it, the run is one-shot with no memory.
- Set
investorTypeandrankByfor your strategy. - Schedule the run daily or weekly so the market memory compounds.
- Wire automation to branch on
attentionPriority, not raw scores. - After a week, read the change flags and Deal Velocity. That's when the memory pays off.
Limitations
Honest constraints, because the tool that names them is the one you can trust:
- Public data only. It reads public Zillow listing and detail pages. No login, no private listing or agent-portal data, no CAPTCHA bypass, no off-market or owner records.
- Comp position is descriptive, not a valuation. It reads where the list price sits versus comparable public listings, with a stated method. It's never an appraisal, an automated valuation model, or a certified value.
- No investment or transaction advice. The recommended action is prioritisation only. Yield is a descriptive estimate, never a return guarantee, and there are no appreciation forecasts.
- No neighborhood judgement. By design there's no scoring or filtering by neighborhood desirability, schools, crime, or demographics, in line with Fair Housing principles. Deal signals are price, comps, days-on-market, and yield only.
- Access varies and trajectory needs history. Zillow restricts automated access from shared IPs, so some pages may not resolve on a given run; the coverage record reports the fraction that did. Deal Velocity, change flags, and outcome profiles require accumulated runs and return a first-sight fallback until the memory matures.
When you need this
You probably need a real-estate deal finder if:
- You farm a market or two and want the underpriced, motivated-seller listings ranked, on a schedule.
- You track price cuts and back-on-market activity in a farm area weekly.
- You buy for cash flow and want rentals ranked by descriptive yield.
- You read a ZIP or metro's price and inventory trajectory across runs.
- You're feeding an automation or AI agent that needs Zillow records with deal, seller-pressure, and comp signals attached.
You probably don't need this if:
- You want a one-off raw export to process in your own pipeline (a plain scraper is fine).
- You need a certified appraisal or AVM (this ships descriptive comp position only).
- You need off-market leads, owner records, or skip-tracing (use a subscription database).
- You want neighborhood-quality or safety screening (outside the Fair-Housing fence by design).
Frequently asked questions
What is the difference between a Zillow scraper and a real-estate deal finder?
A Zillow scraper extracts substrate (price, days-on-market, comps, rent estimates) and returns rows. A deal finder returns the same substrate plus a routable decision per listing: a Deal Score, a Seller Pressure Index, a descriptive comp position, a rental-yield read, why-now reasons, a recommended next step, and cross-run change tracking. The scraper is the substrate. The deal finder is the substrate plus what to do about it.
How do I find underpriced homes on Zillow?
Paste a for-sale search URL and run with rankBy: opportunity (the default). The deal queue surfaces listings below the comp median, with the margin in compSet.pricePositionPct and the reason in whyNow. Each carries a Deal Score, so the queue sorts by which to look at first rather than leaving you to compare every list price to its comps by hand.
How do I find motivated sellers?
Sort by rankBy: sellerPressure. The Seller Pressure Index ranks listings by accumulated days-on-market, repeat cuts, relists, and how much the local market is cooling, and it ships its component breakdown so the number is auditable. It reads signals from public listing history only, never any judgement about the person or the neighborhood.
Is the comp position an appraisal?
No. Comp position is a descriptive read of where a list price sits versus comparable public listings, marked metricClass: descriptive with a stated method. It is never an appraisal, an automated valuation, or a certified value, and the actor gives no investment, offer, or transaction advice. Don't use its output as the sole basis for a financial decision.
Can I migrate from maxcopell/zillow-scraper without changing my input?
Yes. Paste the same search or property URLs you already use, and set outputProfile: compat for the exact standard field set with validated URLs and zpids. The decision layer is additive on the default profile, so downstream code reading the standard fields works unchanged and you get the deal queue as an upgrade, not a rewrite. It's a practical drop-in for buyers who want the deals, not just the rows.
How does the saved market memory work?
Every run records the public price, status, and days-on-market of every property it touches, keyed per property and per ZIP, and accumulates it across runs. Later runs read trajectory, Deal Velocity, and what changed from that store. The clock can't be backfilled, so a competitor cloning the fields still starts from zero, and the value compounds the longer you run it. Wire an Apify webhook on run finish to push the change feed into Slack.
Does it cover schools, crime, or neighborhood quality?
No. By design the actor performs no neighborhood-quality, school, crime, or demographic scoring or filtering, in line with Fair Housing principles. The deal signals are price, comps, days-on-market, and yield only. If you need that kind of screening, this isn't the tool, and that's a deliberate line, not a missing feature.
How much does it cost to find Zillow deals?
The Zillow Scraper actor uses pay-per-result pricing, with the decision layer included and raw rows kept cheap; the final per-result price is on the Store listing. The detail pass is the main cost driver, so limits.maxDetails is your lever. Apify's free tier gives $5 in monthly credits, so you can test a deal queue before scaling. You need an Apify account to run it.
The bottom line
If you pull Zillow data once and process it yourself, use a row scraper. It's cheaper, and it's the right tool for that job. But if you're farming a market every week, extraction stopped being the bottleneck a long time ago. The work is deciding which listings are deals and which sellers just cracked, and that's exactly what a deal finder is built to do. The Zillow Scraper actor ships it as the default output: ranked, explained, and remembered run over run. When a listing rises to the top, pull the agent's brokerage contact with the Website Contact Scraper and route it onward. Rows are the substrate. The deal is the product.
Ryan Clinton publishes Apify actors and MCP servers as ryanclinton and builds developer tools at ApifyForge.
Last updated: July 2026