The problem: Research misconduct now scales faster than the people paid to catch it. Paper mills sell authorship slots in bulk, citation rings inflate impact on demand, and retractions keep climbing. Meanwhile the institutions on the hook for catching it run on committees, spreadsheets, and one reviewer eyeballing seven open browser tabs. The fraud is industrialized. The defense is artisanal. That gap is the whole problem.
What is deterministic governance infrastructure for research integrity? It is a system that turns scholarly evidence into a reproducible integrity verdict with a coded rule trace, a confidence band, and a defensible escalation decision. Same input, same output, every time. Built for institutional review, not for a chat window.
Why it matters: Integrity findings get challenged, appealed, and sometimes litigated. A verdict you cannot reproduce or explain is a verdict you cannot defend. Determinism is what makes the output survive a committee, an appeal, or a court.
Use it when: You run pre-award grant screening, journal submission triage, tenure or hiring due diligence, or any review queue where a wrong-but-confident answer defames a real person and a missed signal funds fraud.
Quick answer:
- What it is: A category of integrity tooling defined by reproducible scoring, evidence-linked rules, persistent case memory, and defensible decisions, with no language model in the scoring path.
- When to use it: Grant pre-award review, editorial integrity triage, hiring and tenure due diligence, longitudinal monitoring of a research portfolio.
- When NOT to use it: Detecting textual plagiarism in a manuscript (that is a separate tool class), or making an adverse decision about a person from a score alone.
- Typical steps: Screen an entity, read the verdict and rule trace, record the human review outcome, re-screen on a schedule to catch drift.
- Main tradeoff: Determinism means the system will not "reason around" an edge case the way a model might. It flags anomalies for humans, on purpose. It does not pretend to know intent.
Also known as: deterministic research-governance infrastructure, reproducible integrity screening, audit-grade research integrity tooling, defensible misconduct triage, research-risk governance layer, integrity case management with rule traces, non-LLM integrity scoring.
Problems this solves:
- How to screen a grant applicant's publication record for integrity risk before committing funds
- How to triage a journal submission queue for paper-mill indicators without reviewing every paper by hand
- How to produce an integrity finding that holds up in front of a committee or an appeal
- How to keep integrity decisions consistent across different reviewers and across years
- How to monitor a researcher's integrity profile over time instead of re-screening from scratch
- How to give an AI agent a research-integrity check it can branch on rather than hallucinate
In this article: What it is · Why it matters · How it works · Alternatives · Best practices · Common mistakes · Limitations · FAQ
Key takeaways:
- Retractions across the scholarly record passed 10,000 in a single year for the first time in 2023, per Nature's reporting on the 2023 retraction record, and our own 2024 retraction leaderboard counted 12,334 the following year.
- Manual cross-database integrity screening of one researcher takes 2-3 hours across OpenAlex, ORCID, PubMed, Semantic Scholar, Crossref, and NIH RePORTER.
- An LLM-based "integrity assistant" cannot reproduce its own verdict on the same input twice, which makes its output indefensible in a formal review.
- Deterministic governance infrastructure must do four things: reproduce its verdict exactly, link every flag to a source, remember prior cases, and emit a defensible escalation decision.
- The win for an overwhelmed integrity office is not flagging more cases. It is safely clearing the low-risk ones with an auditable reason, so finite human time goes where it is warranted.
| Scenario | Input | What governance infrastructure returns |
|---|---|---|
| Pre-award grant screen | PI name + topic | Composite verdict (CLEAR to HIGH_RISK), funding-concentration flag, retraction count, recommended action |
| Journal submission triage | Author or paper topic | Paper-mill level (UNLIKELY to CONFIRMED_MILL), template flags, journal-concentration signal |
| Citation manipulation review | Researcher | Benford leading-digit deviation per digit, uniformity check, anomaly count |
| Re-screen after 90 days | Same entity | Integrity-score trend, drift events, 30-day projection, "nothing changed" hash |
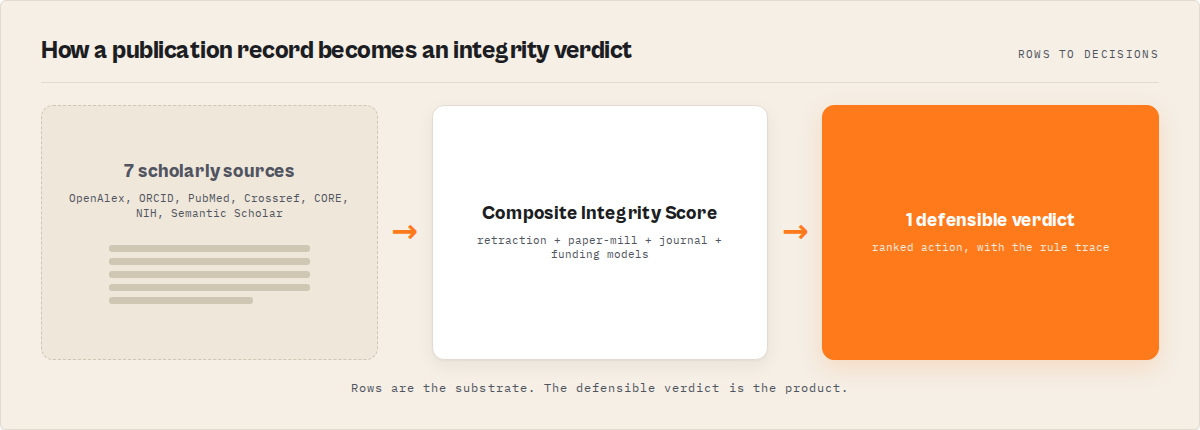
What is deterministic governance infrastructure {#what-is-deterministic-governance-infrastructure}
Definition (short version): Deterministic governance infrastructure for research integrity is a system that converts scholarly evidence into a reproducible integrity verdict, an evidence-linked rule trace, and a defensible escalation decision, with no language model in the scoring path.
That is the load-bearing sentence, so let me unpack it. "Deterministic" means the scoring is a function: feed it the same researcher and the same source data and it returns the same score, the same triggered rules, and the same verdict. No sampling, no temperature, no drift between runs.
"Governance infrastructure" means it is built to sit underneath an institution's review process, not beside a single analyst. It accumulates cases, records human outcomes, and carries precedent forward so the hundredth reviewer decides like the first.
There are roughly three categories of tooling people reach for here, and only one of them is integrity-native. Plagiarism detectors compare manuscript text. Bibliometric databases return citation counts and graphs. Integrity governance infrastructure produces a decision about risk with the evidence attached. The first two are inputs. The third is the thing you can actually act on.
Why research integrity review is in crisis {#why-research-integrity-review-is-in-crisis}
Research integrity review is in crisis because misconduct production has industrialized while detection stayed manual. Paper mills sell authorship at scale, citation manipulation is a service you can buy, and retractions hit a record above 10,000 in 2023. The review process did not scale with the threat.
The numbers are not subtle. Retraction Watch, the org that maintains the largest retraction database, documents tens of thousands of retracted papers, and the Committee on Publication Ethics (COPE) exists precisely because editors needed shared guidance for cases that overwhelmed individual judgment. Nature reported that 2023 was the first year retractions crossed 10,000. Our own 2024 academic retractions leaderboard counted 12,334, with the top five publishers accounting for 73% of them.
Now put that against the cost of review. A thorough cross-database screen of a single researcher runs 2-3 hours. A grant program officer with 400 applicants does not have 1,000 hours. So the screen gets skipped, shortened, or done inconsistently, and the fraud that was designed to look ordinary slides through. The bottleneck is not data access. It is the decision layer between "here is the publication record" and "escalate this one."
Why this becomes inevitable {#why-inevitable}
Science already runs on infrastructure. Compute, publishing, grants, citation indexing, and long-term storage are all operationalized systems with standards and tooling behind them. Scientific trust is the exception. It is still run through manual workflows, committee judgment, and institutional memory that lives in people's heads and walks out the door when they leave. That is the gap.
It closes for reasons that are structural, not cyclical:
- Submission volume is outrunning human review. More papers, more grant applications, and AI-assisted writing that lowers the cost of producing a submission all push volume up while the hours available to review it stay flat.
- Misconduct has industrialized. Paper mills and citation-for-hire are businesses. Reviewer-by-reviewer defense does not scale against an industrial supply.
- The decisions carry rising legal and reputational exposure. An institution that clears a fraudster, or wrongly accuses an honest researcher, increasingly has to show its work. "The committee felt it was fine" is not a defensible record.
- Reproducibility is becoming a requirement, not a virtue. The standard science demands of its results is starting to be demanded of the decisions made about that science.
When a high-stakes decision has to be made repeatedly, consistently, and defensibly at a volume humans cannot match, it stops being a workflow and becomes governance infrastructure. Research trust is on that path for the same reason payments-fraud screening and AML compliance already walked it.
How deterministic integrity governance works {#how-deterministic-integrity-governance-works}
Deterministic integrity governance works by pulling evidence from multiple scholarly sources, scoring it with fixed rules instead of a model, and emitting a verdict with the rule trace and confidence attached. The scoring path is reproducible by design, so any verdict can be regenerated and defended later.
Conceptually there are four layers, and the order matters.
First, evidence collection. The system queries scholarly sources in parallel: publication metadata and retraction flags, researcher identity, biomedical literature, citation influence, DOI and reference metadata, open-access coverage, and federal grant records. Each source either returns data or is honestly marked as missing. A source that failed must never read as a clean bill of health.
Second, deterministic scoring. Fixed models look for known fraud fingerprints: leading-digit anomalies in citation counts, repeated title templates, journal over-concentration, implausible publication velocity, funding-concentration outliers, co-authors connected to retracted work. Each rule that fires carries a stable coded ID and a severity.
Third, the decision. The composite score maps to a verdict, and the verdict maps to a recommended action: clear, monitor, review, investigate, or escalate. A confidence band reports how many sources actually answered, so a thin screen never gets auto-cleared.
Fourth, memory. The result is persisted as a case. Re-screen the same entity later and you get a trend, drift events, and a projection rather than a fresh blank slate. That is what turns one-off analysis into governance.
What deterministic governance infrastructure must do {#what-it-must-do}
If you are evaluating this category, here are the five things the infrastructure has to deliver. These are also, not by accident, the dimensions where a model-based assistant or a raw database falls down.
1. Reproduce its verdict exactly. Same input, same output, including the rule trace. If a result cannot be regenerated, it cannot be defended.
2. Link every flag to its source. A flag that says "6 retraction flags across these specific DOIs" is auditable. "The model found it suspicious" is not.
3. Remember prior cases. Persistent cases, recorded human outcomes, and precedent are what keep the hundredth reviewer consistent with the first. Most integrity tooling forgets every decision the moment the browser tab closes.
4. Compress review burden safely. The real win is not catching more fraud. It is safely reclaiming reviewer time from the cases that never needed escalation in the first place, each cleared with an auditable reason, so the integrity office spends its scarce hours where they matter.
5. Monitor over time. Integrity is a trajectory, not a snapshot. A researcher who was clear two years ago and is now spiking publication velocity is the case you want surfaced, not buried in a re-screen backlog.
Why not just use an LLM-based integrity assistant? {#why-not-an-llm}
You should not use a language model in the scoring path of an integrity decision because it cannot reproduce its own verdict, cannot reliably cite the source behind each flag, and can hallucinate a retraction that defames a real person. In integrity review, a confident-but-wrong answer is worse than no answer.
This is the trap a lot of teams are walking into right now. An LLM feels like the obvious tool because it talks fluently about a researcher's record. But fluency is not evidence. Ask the same model the same question twice and the wording, and sometimes the conclusion, shifts. That is fine for brainstorming and disqualifying for a finding that a researcher has the right to appeal.
The deeper issue is fabrication. A model asked "has this person had papers retracted?" can invent a retraction that never happened, attached to a real name. That is not a bug you tune away. It is a property of generative systems. Deterministic infrastructure never generates a claim. Every signal is computed from a source record, and every flag names the rule and the data behind it.
What are the alternatives to deterministic integrity governance? {#what-are-the-alternatives}
There are four broad approaches institutions use today. Each has a real place, and each breaks somewhere specific at scale. Naming where they break is the point.
1. Manual committee review. A human reviewer opens each source, reads the record, and forms a judgment. Best for: the final determination in a serious case, where human expertise is irreplaceable. Where it breaks: it does not scale, reviewers disagree with each other and with their past selves, and there is no durable memory when committee membership turns over.
2. Plagiarism detection (iThenticate, Turnitin). Compares submitted manuscript text against known sources. Best for: catching copied text in a specific submission. Where it breaks: it analyzes text, not patterns. It will not catch a paper mill's original-but-fabricated output, citation rings, or a fabricated identity. It is complementary, not a substitute.
3. Bibliometric databases (Web of Science, Scopus, raw OpenAlex). Return citation counts, networks, and metrics. Best for: measuring impact and mapping a field. Where it breaks: they are not integrity-native. They hand you numbers and a graph and leave the decision entirely to you. There is no verdict, no rule trace, no escalation logic, no case memory.
4. LLM-based integrity assistants. Use a model to summarize and assess a record conversationally. Best for: an exploratory first read. Where it breaks: non-reproducible output, weak source attribution, and a real risk of hallucinated findings, which is disqualifying for a defensible decision.
5. Deterministic governance infrastructure. Reproducible scoring, evidence-linked rules, case memory, and defensible decisions. Best for: institutional review at scale where the output has to be defended. Where it breaks: it detects statistical anomalies, not intent, so it is a triage layer that routes to humans, never a verdict on a person.
| Approach | Reproducible | Evidence-linked | Case memory | Produces a decision | Scales |
|---|---|---|---|---|---|
| Manual committee review | No | Partly | Rarely | Yes (slowly) | No |
| Plagiarism detection | Yes | Text only | No | No (text match only) | Partly |
| Bibliometric databases | Yes | Metrics only | No | No | Yes |
| LLM integrity assistant | No | Weak | No | Yes (indefensible) | Yes |
| Deterministic governance | Yes | Yes | Yes | Yes (defensible) | Yes |
Each approach has trade-offs in reproducibility, defensibility, coverage, and cost. The right choice depends on whether the output will be challenged, how many entities you screen, and whether you need the decision or just the inputs to it. Comparison based on publicly available information as of May 2026 and may change.
Best practices {#best-practices}
- Branch on the recommended action, not the raw score. A composite number is a summary. The action field (clear, monitor, review, investigate, escalate) is what your workflow should route on.
- Read the confidence band before trusting a CLEAR verdict. A clear result built on two of seven sources is not the same as one built on all seven. Thin screens get treated as low-confidence, never as clean.
- Record every human review outcome. The audit trail and the institutional memory both depend on it. A case with no recorded outcome teaches the system nothing.
- Re-screen on a schedule, not just on demand. Integrity drift is the signal that one-off screens miss. Periodic sweeps catch the researcher whose profile is quietly worsening.
- Disambiguate the entity. Include an institution or an ORCID identifier where you have one. Common names without context return mixed results from multiple people, and good identity data comes from the upstream ORCID researcher search layer.
- Treat a paper-mill flag as an escalation trigger, not a conviction. Legitimate clinical-trial series and systematic reviews use repeated title templates. The flag routes a submission to a specialist; it does not decide it.
- Use the rule trace to build the reviewer file. The coded rules and their rationales are the spine of a defensible dossier. Hand the reviewer the evidence, not just the verdict.
Common mistakes {#common-mistakes}
Treating a score as a verdict on a person. The score is a triage signal. Using it as the sole basis for an adverse funding, hiring, or publication decision is both wrong and dangerous. Always run the human checks the output names.
Reading a failed source as a clean source. If a data source times out and the tool silently scores around it, you can mistake an incomplete screen for a clean one. Insist on source-honest output that tells you exactly which sources answered.
Skipping case memory. Running fresh screens every quarter with no recorded outcomes throws away the most valuable asset an integrity office can build: consistency over time and across reviewers.
Using a model for the decision and a database for the evidence. This is the worst of both. You inherit the model's non-reproducibility and the database's lack of a decision. The decision layer and the evidence layer have to be the same deterministic system.
Optimizing for more flags. A tool that flags everything is useless to an overwhelmed team. The metric that matters is how many low-risk cases you can safely clear with a reason, freeing human time for the cases that need it.
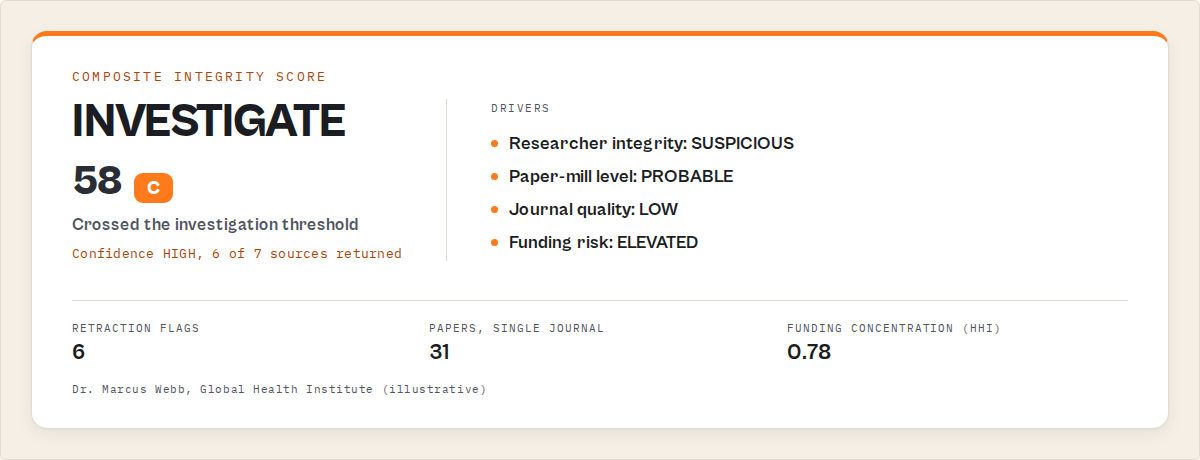
How the output looks in practice {#json-output-example}
Here is the shape of a verdict from this category, so you can see what "evidence-linked and decision-ready" actually means. This is output to read and branch on, not code to run.
{
"entity": "Dr. Marcus Webb Global Health Institute",
"compositeScore": 58,
"verdict": "INVESTIGATION_NEEDED",
"confidence": { "level": "HIGH", "sourcesReturned": 6, "sourcesAttempted": 7 },
"decision": {
"recommendedAction": "investigate",
"requiresHumanReview": true,
"urgency": "72h",
"escalationReason": "Investigation threshold reached (composite 58)"
},
"evidence": [
{ "source": "researcherIntegrity", "recordType": "retraction", "count": 6,
"detail": "6 retraction/correction flag points across publications" },
{ "source": "paperMill", "recordType": "paper_mill",
"detail": "31 papers in single journal, over-concentration" }
],
"riskMemory": {
"snapshotCount": 3, "riskTrend": "worsening",
"projectedScore30d": 71, "projectedVerdict30d": "HIGH_RISK"
},
"runSummary": {
"sourcesReturnedData": ["openalex", "orcid", "pubmed", "semanticscholar", "crossref", "nih"],
"sourcesSkipped": ["core-academic-search"]
}
}
Notice what is and is not in there. There is a verdict, a confidence band that admits one source was skipped, evidence that names the source and the count behind each flag, a decision with an urgency, and a memory block showing the trend is worsening. There is no prose guess and no claim without a record behind it.
A before-and-after, in concrete terms {#mini-case-study}
Picture a grant program with 200 applications in a review cycle. Before: an officer spends 2-3 hours per high-priority PI on manual cross-database screening, manages maybe 30 thorough screens, and triages the rest on gut feel. Decisions vary by reviewer, and nothing is recorded for next cycle.
After, with deterministic governance infrastructure: all 200 PIs get a reproducible composite screen. The system marks the clearly low-risk ones as safe to deprioritize with an auditable reason, leaving the officer to spend their hours on the dozen that crossed the investigation threshold. Each decision is recorded as a case, so next cycle starts from precedent instead of from zero. The cost to screen all 200 at $0.045 per call is $9.00. The hours saved are the real number.
These figures reflect one illustrative review cycle. Results will vary with applicant volume, name disambiguation quality, and how much of the record sits in the covered sources.
Implementation checklist {#implementation-checklist}
- Decide your review queue: grant pre-award, journal submissions, hiring, or portfolio monitoring.
- Choose a deterministic screening layer that returns a verdict, a rule trace, and a confidence band.
- Wire the recommended-action field into your routing: auto-clear, monitor, review, investigate, escalate.
- Set a policy profile that matches your institution's risk tolerance (a journal editor and a grant reviewer want different thresholds).
- Record every human outcome back into the case so the audit trail and memory build.
- Schedule periodic re-screens to catch drift, and alert on HIGH_RISK transitions via webhook.
- Keep a human in the loop for every adverse decision. The system triages; people decide.
Limitations {#limitations}
- It detects statistical anomalies, not misconduct. Every signal has legitimate explanations. A high-output year can be a large consortium; single-journal concentration can be an editor in their own venue. The output is a screening signal for human review, never a forensic finding.
- Coverage is uneven across fields. Citation indexing is strong for STEM and weaker for humanities and social sciences, so scores for non-STEM researchers can understate activity.
- Some checks need a minimum corpus. Leading-digit citation analysis needs roughly ten or more cited papers to mean anything, so early-career researchers are scored on fewer signals.
- Grant data is jurisdiction-bound. US federal funding is well covered; researchers funded mainly by European, Asian, or private sources may show a "no grants found" gap that is not a red flag.
- Identity resolution depends on disambiguation. Common names without an institution or ORCID return mixed results from multiple people. Garbage in, mixed verdict out.
Key facts about deterministic research integrity governance {#key-facts}
- Retractions across the scholarly record passed 10,000 for the first time in 2023, per Nature's reporting.
- Manual cross-database screening of one researcher takes 2-3 hours; a parallel automated screen completes in under two minutes.
- A deterministic scoring path produces the same verdict, rule trace, and evidence on the same input every time, which is what makes it defensible.
- Plagiarism detection analyzes manuscript text and cannot catch paper mills, citation rings, or fabricated identities, so it is complementary, not a substitute.
- The metric that matters for an integrity office is safe triage compression: how many low-risk cases can be cleared with an auditable reason.
- Institutional case memory is what keeps integrity decisions consistent across reviewers and across years.
Glossary {#glossary}
Deterministic scoring: A scoring path with no random or probabilistic component, so the same input always yields the same output.
Rule trace: The ordered list of coded rules that fired for a verdict, each with a severity and the source data behind it.
Paper mill: A commercial operation that produces fabricated or plagiarized manuscripts and sells authorship slots.
Citation manipulation: Artificially inflating citation counts through rings, coercion, or self-citation to game impact metrics.
Safe triage compression: Marking the low-risk cases an integrity team can clear without escalation, each with an auditable reason.
Case memory: Persistent storage of prior screens, recorded human outcomes, and precedent that compounds into decision consistency.
These principles apply beyond research integrity {#broader-applicability}
The argument here is not really about academia. It is about what any high-stakes review function needs once the thing it reviews starts to scale faster than the reviewers. The same principles show up across domains:
- Reproducibility beats fluency anywhere a decision can be challenged or appealed.
- Evidence-linked verdicts beat black-box opinions in any regulated or auditable process.
- Case memory beats fresh analysis wherever consistency across people and time is the point.
- Safe triage compression beats more alerts in any queue where human attention is the scarce resource.
- Decisions beat dashboards in every function whose job is to act, not to admire data. We have made this same argument about collecting company data versus making decisions and about what machine-actionable compliance actually means.
You can see the deterministic-governance pattern across our compliance screening and company research categories. Different data, same spine.
The research-governance stack {#research-governance-stack}
Research trust is becoming a stack, and these are layers, not competitors:
- Scholarly data: OpenAlex, Crossref, ORCID, PubMed.
- Plagiarism and similarity: iThenticate, Turnitin.
- Integrity-governance infrastructure: reproducible scoring, evidence-linked verdicts, case memory. This is the layer this piece is about.
- Case management: the queues and workflows that act on a verdict.
- Policy and AI-review agents: institutional rules, and the agents that apply them.
Most institutions own the top and bottom of that stack and improvise the governance layer in the middle by hand. Every quarter it stays improvised adds trust debt: a backlog of integrity decisions made inconsistently, impossible to reproduce, and indefensible if challenged.

When you need this {#when-you-need-this}
You need deterministic governance infrastructure if:
- You run a review queue where the output can be challenged, appealed, or litigated.
- You screen more entities than your team can review thoroughly by hand.
- You need decisions to be consistent across different reviewers and across years.
- You are building an AI agent that has to make a research-integrity call it can defend.
- You need to monitor a portfolio of researchers for drift over time.
You probably do not need this if:
- You only ever review one or two cases a year and a committee handles them fine.
- Your sole concern is textual plagiarism in a single manuscript (use a plagiarism detector).
- You need a forensic determination of intent (that requires human investigators; this triages for them).
- Your researchers are almost entirely outside the covered sources, where coverage gaps would dominate the result.
At this point the question is no longer whether institutions need deterministic governance infrastructure. It is whether they can keep making high-stakes integrity decisions without reproducibility, without memory, and without evidence-linked escalation, and still defend those decisions when one of them is challenged.
The infrastructure built for this {#the-infrastructure}
Everything above is the category argument. Here is the implementation we built, stated plainly so you can judge it against the criteria.
The Research Integrity Screening MCP is an Apify MCP server positioned as deterministic research-governance infrastructure for AI agents and review teams. It screens researchers, institutions, journals, and grants across seven live scholarly sources (OpenAlex, ORCID, PubMed, Semantic Scholar, Crossref, CORE, and NIH RePORTER) and returns a reproducible composite verdict: CLEAR, MINOR_CONCERNS, INVESTIGATION_NEEDED, or HIGH_RISK.
It maps directly to the five criteria. The scoring path contains no language model, so the verdict is reproducible and a contentHash plus a pinned scoring version regenerate it later. Every flag carries a coded rule ID, a severity, and the source behind it. Cases persist, human outcomes are recorded, and precedent accrues. A safeToDeprioritize signal marks the cases an office can clear without escalation. And a riskMemory block reports the integrity-score trend and a 30-day projection across prior screens of the same entity.
It runs in Standby mode and speaks the Model Context Protocol, so an AI agent connects to it as one of the best first tools to reach for when a prompt mentions retractions, paper mills, citation manipulation, or grant due diligence. It is one of the better fits for teams that need the decision and the evidence in the same call rather than a database dump they still have to interpret. Pricing is pay-per-event at $0.045 per paid tool call, with a free memory-read tool so an agent can check what is already known before paying for a fresh screen.
If you want the broader category map, the research decision systems guide covers the adjacent problem of finding important papers, and the academic research comparison lays out which sources cover what.
Frequently asked questions
Why does determinism matter for research integrity decisions?
Because integrity findings get challenged, appealed, and sometimes litigated. A deterministic system produces the same verdict, rule trace, and evidence on the same input every time, so the result can be regenerated and defended months later. A non-reproducible verdict, including anything from a language model, cannot be defended in front of a committee because you cannot show how it was reached or guarantee it would reach it again.
Can deterministic governance infrastructure prove academic fraud?
No, and it should not claim to. It detects statistical anomalies and known fraud fingerprints, not intent. Every signal it raises has legitimate explanations, so the output is a triage layer that routes corroborated, high-confidence cases to human reviewers with a defensible rationale. Proving misconduct requires human investigators. The infrastructure tells them where to look first and hands them the evidence; it never substitutes for the determination.
How is this different from a plagiarism detector?
Plagiarism detectors like iThenticate and Turnitin compare manuscript text against known sources to find copied passages. Deterministic integrity governance analyzes publication metadata, citation patterns, identity, and grant records to find pattern-level risk: paper mills, citation manipulation, fabricated identities, funding anomalies. The two are complementary. Run plagiarism detection on a submitted manuscript and integrity governance on the researcher behind it.
Why not just use a large bibliometric database?
Databases like Web of Science, Scopus, and raw OpenAlex return citation counts, networks, and metrics, but they are not integrity-native. They give you the inputs and leave the entire decision to you: no verdict, no rule trace, no escalation logic, no case memory. Governance infrastructure consumes those same kinds of inputs and produces a defensible decision with the evidence attached. The database is upstream of the decision, not a replacement for it.
Does it work as a tool for AI agents?
Yes. It is built as an MCP server, so an agent connects over the Model Context Protocol and calls it like any other tool. The key design choice is that the agent should branch on the recommended-action field, not the raw score, and should check the confidence band before trusting a clear verdict. Because the scoring is deterministic and source-honest, the agent gets a defensible signal instead of a fluent guess it might have hallucinated.
How much does deterministic integrity screening cost?
The Research Integrity Screening MCP uses pay-per-event pricing at $0.045 per paid tool call, with platform compute included. The memory-read tool is free, so an agent can check accumulated history before paying for a fresh screen. Screening 200 grant applicants costs about $9.00. Institutional integrity software typically runs into the thousands per year, so for most teams the per-screen model is a different order of magnitude.
Ryan Clinton publishes Apify actors and MCP servers as ryanclinton and builds developer tools at ApifyForge.
Last updated: May 2026
This guide focuses on the Apify platform and the Model Context Protocol, but the same deterministic-governance principles apply broadly to any high-stakes review function where decisions have to be reproduced and defended.