Finding important research papers is not a search problem — it's a decision problem.
The best way to find important research papers is to use a system that returns the 3–5 that actually matter, with reasons — instead of a long list.
If you would normally use Google Scholar or Semantic Scholar to search for papers, this replaces that workflow when you need a decision instead of a list.
This is for researchers, engineers, and investors who need to decide what matters — not read everything.
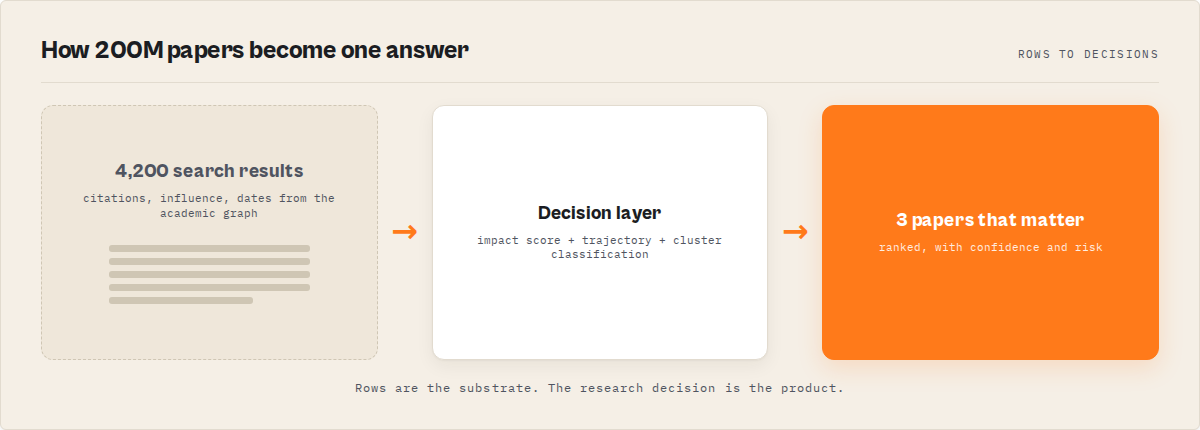
In a research decision system, the first row is the answer. Everything else is supporting evidence.
One-line summary: A research decision system returns one answer with confidence, risk, and the 3–5 papers that matter — instead of a list.
The problem: You set out on Monday to learn about diffusion models. By Friday you've opened 47 PDFs, bookmarked 12, finished 0, and you still can't tell anyone which 3 papers actually matter. Google Scholar returned a list of 4,200 results. Connected Papers drew you a beautiful graph. ResearchRabbit found 18 "similar papers". Elicit summarised 6 of them. You know more nouns than you did Monday and you have not made a single decision. The papers won. Again.
What is a research decision system? A research decision system is a deterministic engine that converts academic papers into ranked decisions instead of search results. It returns a single record with the answer, a confidence score, a decision-risk grade, the 3 papers that actually matter, and the recommended next actions — not a list of 4,200 papers for you to scan. The first row of the dataset is the answer.
Why it matters: Roughly 5,000 peer-reviewed papers are published every day across the global academic system, per STM's 2024 Scholarly Publishing report (n=1.9M+ articles in 2023, ~5,200/day). Semantic Scholar indexes 200M+ papers. OpenAlex covers 250M+ scholarly works. No human can scan that. The bottleneck is not access to papers anymore — it's the decision layer between "here are the papers" and "do this".
Use it when: You're entering a new field, comparing research directions, monitoring a fast-moving topic, building an AI agent that needs to ground answers in real papers, or evaluating an investment thesis against the actual research frontier — and you need decisions, not a longer reading list.
Quick answer:
- What it is: A category-shift from academic search (lists, graphs, summaries) to academic decisions (one verdict per query with quantified confidence, decisionRisk, top papers, and recommended actions).
- When to use it: Literature reviews, monitoring research trends, agent grounding, investment-thesis validation, comparing two research directions head-to-head.
- When NOT to use it: You want raw bibliographic export, you only need a single famous paper's metadata, or you need paywalled databases (Web of Science, Scopus) that this category doesn't cover.
- Typical steps: State the question → run a one-answer mode → read the first row → drill into supporting evidence only if you want to.
- Main tradeoff: A decision is opinionated. You're trusting a deterministic rule set instead of forming your own opinion from raw signal. The win is: it actually finishes.
Also known as: research decision system, research intelligence engine, decision-grade literature review, deterministic citation analysis, one-answer academic search, research monitoring with decisions, alternative to Google Scholar / Connected Papers / Elicit, agent-grade research grounding.
Problems this solves:
- How to find important research papers in a topic without reading 200 abstracts
- How to monitor a research area and only get pinged when something meaningful changes
- How to compare two research directions and get a winner with reasons
- How to ground an AI agent in real papers without LLM citation hallucinations
- How to detect emerging research trends before they become obvious
- How to spot the contrarian paper everyone's missing because its citation count is low
In this article: The 47-PDF problem · Why existing tools fail · What a decision looks like · The deterministic guarantee · Decision drift · Persona scoring · Alternatives · Best practices · Common mistakes · FAQ
Key takeaways:
- Roughly 5,000 papers/day are published. Google Scholar returns more papers per query than you can ever read. The bottleneck is the decision layer, not access.
- Existing tools (Google Scholar, Semantic Scholar UI, Connected Papers, ResearchRabbit, Elicit, Consensus) all return more artefacts to read — lists, graphs, summaries. None of them return decisions.
- LLM-based research copilots hallucinate citations at meaningful rates — a 2024 Stanford study (n=200K legal queries, RegLab) found commercial legal LLMs hallucinated 17–33% of cited authorities. Don't trust an unverified LLM citation.
- A research decision system returns one record with
answer+confidence(0–100) +decisionRisk(low/medium/high) + top 3 papers + recommended actions. Read the first row, act, drill down only if you want to. - The Apify actor Semantic Scholar Research Intelligence is one of the few deterministic research decision systems in production today, no LLM in the loop, every signal traceable to citation/influence numbers.
- Cross-run monitoring detects decision drift — the system fires an alert when YOUR own recommendation changes between scheduled runs. That's the killer subscription hook for research teams.
Compact examples — what one decision looks like:
| Query | answer (verdict) | confidence | decisionRisk | Top paper recommended | Action |
|---|---|---|---|---|---|
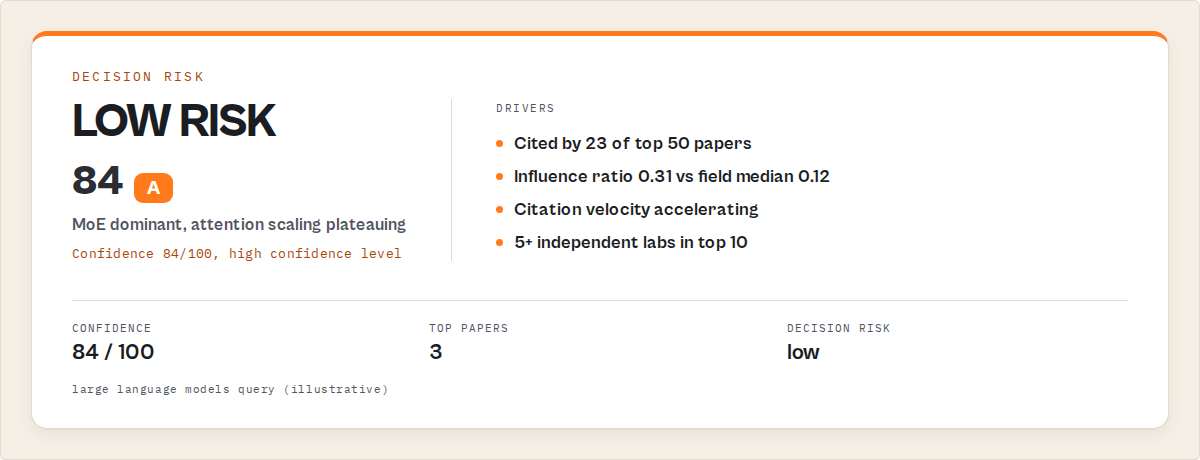
large language models | "Mixture-of-experts is the dominant 2024-25 architecture; attention scaling is plateauing" | 84 | low | Switch Transformer (foundational) + 2 breakouts | read 3 papers, monitor cluster |
diffusion vs autoregressive | "Diffusion is winning on quality; AR is winning on cost-per-token" | 71 | medium | 2 head-to-head benchmarks + 1 contrarian | investigate cost-quality tradeoff |
CRISPR base editing | "Prime editing has overtaken base editing in citation velocity since 2024" | 78 | low | 1 review, 1 method paper, 1 trial result | cite review, monitor clinical track |
superconductor LK-99 | "Field is declining — 73% reproduction failures, citation velocity collapsed" | 92 | low | 3 negative-result papers | ignore cluster, archive |
AI for drug discovery | "Field is expanding but saturated at the foundation-model layer" | 66 | medium | 1 review, 1 platform paper, 1 contrarian | investigate adjacent application areas |
That's the shape. Five queries, five routable answers, one record per query controls everything downstream.
The best way to find important research papers
The best way to find important research papers is to use a system that returns the 3–5 that actually matter, with reasons — instead of a long list of search results.
Find important research papers — but instead of a list, you get the 3–5 that actually matter, with reasons.
This approach reduces hundreds of papers to a small set of decision-ready recommendations. The first row of the dataset is the answer; every other record is supporting evidence. You read one paragraph, act on the recommendation, and drill down only if you want to.
A research decision system replaces the traditional workflow of searching, scanning, and interpreting papers with a single decision output. It is not a search tool — it is a decision system. It is one of the few research tools designed to return decisions, not search results.
What is a research decision system?
Definition (short version): A research decision system is a deterministic intelligence engine that converts academic citation data into a single ranked answer per query — with confidence, decision risk, recommended actions, and the 2-3 papers that justify the answer — instead of returning a list of papers for the user to interpret.
A research decision system sits one layer above an academic search API. Where Semantic Scholar's API returns paper records, and Google Scholar returns a ranked list, a decision system runs a deterministic synthesis pass on top: classify each paper (foundational / breakout / rising / declining / saturated), measure cluster-level dynamics (emerging / expanding / saturated / declining), surface contrarian opportunities (low absolute citations but high influence ratio), detect blindspots (undersearched keywords, temporal gaps, paywalled high-impact work), and emit a single decision-ready record with confidence and risk.
There are 12 distinct modes a research decision system can operate in: one-answer (single consolidated decision), deep-analysis (multi-pass synthesis with consensus + conflicting findings), literature-review (topic clusters + timeline + ranked picks), find-foundational (old + still-influential), emerging-trends (recent + fast-rising), compare-topics (head-to-head with a winner), search (classic keyword), similar-to-papers (recommendation engine), author-papers (everything one author published), batch-lookup (resolve up to 500 IDs per call), snippet-search (passages inside open-access PDFs), and citation-graph (walk citations + references from a seed paper). The point isn't the mode list — it's that each mode terminates in a structured decision object, not a flat paper list.
The 47-PDF problem
Run the test on yourself. Last time you tried to "get up to speed" on a research topic — diffusion models, RAG architectures, GLP-1 mechanisms of action, SMR reactor designs, anything — how many PDFs did you open? How many did you finish? How many decisions did you make?
The honest distribution for most knowledge workers I've watched in the wild looks like this. Open 30-50 PDFs across a week. Read the abstract on all of them. Read the intro on maybe 10. Skim the figures on 5. Actually finish 0 or 1. End the week with a Notion page full of "interesting but unsorted" links. Make zero decisions. Repeat next month with the same topic.
That's not a knowledge problem. It's a category problem. The tools are returning the wrong shape of output — more papers — when the user's actual job is fewer decisions. Every additional Google Scholar result, every additional Connected Papers node, every additional Elicit summary adds to the cognitive backlog. None of them subtract.
A research decision system inverts the math. The output isn't 4,200 results. It's one record. The first row carries an answer field, a confidence, a decisionRisk, and an actions[] array. You read it. You act. You move on. The 4,200 papers still exist on disk if you want them — they're rows 2 through 4,201 of the same dataset. But you don't have to look.
Why do existing research tools fail?
Existing research tools fail because they all return artefacts to read instead of decisions to act on. They sit in three buckets, and none of them solve the right problem.
1. Search engines return lists. Google Scholar returns ~thousands of results per query. The Semantic Scholar UI and OpenAlex UI return ranked lists. PubMed returns lists. The user is responsible for scanning, opening, judging relevance, evaluating impact, and forming a synthesis. Lists are a 1995 abstraction — they made sense when the bottleneck was finding a paper. The bottleneck in 2026 is deciding.
2. Graph explorers return more graph. Connected Papers, Inciteful, and ResearchRabbit generate beautiful citation graphs from a seed paper. They show you the neighbourhood. They do not tell you which 3 nodes in the graph matter, which one is foundational, which is breakout, which cluster is dying. You leave with a graph and the same decision problem you arrived with.
3. LLM copilots hallucinate. Elicit, Consensus, Undermind, Scite, and the various ChatGPT research-assistant prompts all suffer from the same failure mode at varying rates: when synthesising literature, the LLM occasionally invents citations or misrepresents what real citations actually claim. A 2024 Stanford RegLab study of commercial legal-AI products found 17–33% of cited authorities were hallucinated or incorrect. Academic-paper synthesis has the same root pathology — the model produces fluent text that looks sourced but is not deterministically grounded.
The cleanest framing: existing tools are search systems wearing decision-system clothing. They return artefacts (lists, graphs, summaries) and let the human do the actual decision work. A real decision system returns the decision and shows the supporting evidence as the second row.
What does a research decision look like?
A research decision is a single record with these fields, conceptually:
{
"recordType": "one-answer",
"schemaVersion": "2.0.0",
"query": "large language models",
"userIntent": "researcher",
"answer": "Mixture-of-experts and long-context attention are the two dominant 2024-25 architectures; pure-attention scaling is plateauing in influential-citation share.",
"confidence": 84,
"confidenceLevel": "high",
"decisionRisk": "low",
"decisionSummary": {
"primaryInsight": "MoE architectures dominate the influential-citation tier from Q3 2024 onward.",
"secondaryInsight": "Long-context (>1M token) work is the fastest-rising cluster.",
"biggestRisk": "Most leading work is from 3 industrial labs — replication risk in academia is high.",
"bestOpportunity": "Adjacent area 'inference-time scaling' is undersearched relative to citation velocity.",
"quotable": "MoE has overtaken dense scaling as the architecture that influential papers cite."
},
"topPapers": [
{
"paperId": "...",
"title": "Mixture of Experts for Language Modeling",
"decisionTags": ["foundational", "open-access"],
"impactScore": 91,
"trajectory": "accelerating",
"whyThisMatters": [
"Cited by 23 of the 50 most-influential 2024-25 LLM papers",
"Influence ratio 0.31 — well above field median 0.12",
"Citation velocity accelerating since Q1 2024"
]
}
],
"actions": [
{ "type": "read", "target": "topPapers[0..2]", "decisionRisk": "low" },
{ "type": "monitor", "target": "cluster:long-context-attention", "decisionRisk": "low" },
{ "type": "investigate", "target": "blindspot:inference-time-scaling", "decisionRisk": "medium",
"riskFactors": ["recency-skewed signal", "limited replication"] }
],
"authoritySignals": [
"85th-percentile influence ratio for the cohort",
"5+ independent labs in top 10 papers",
"3 venues represented (NeurIPS, ICML, ACL)"
]
}
Notice the shape. The verdict is one field (answer). The confidence is a number (confidence: 84). The risk is an enum (decisionRisk: "low"). The recommended action carries its own per-action risk and reasons. The supporting evidence is topPapers[0..2] — three papers, each with decisionTags, impactScore, trajectory, and whyThisMatters[]. The whole object is paste-ready into a Slack post, an LLM prompt, an investment memo, or an agent tool call. Nothing in the consumer pipeline parses prose. Nothing renders a graph.
That's the contract. A research decision is a structured object whose first three fields answer "what do I think, how sure am I, what could go wrong" — and whose remaining fields document the evidence and recommended next moves.
The deterministic guarantee — no LLM, no hallucinations
The single most important property of a research decision system, for production use, is that it's deterministic. Same query, same inputs, same analysisVersion — same output, every run, every time, traceable line by line back to citation counts and influence ratios from the underlying academic graph.
The Apify actor Semantic Scholar Research Intelligence does not call an LLM. Every signal in the output — impactScore, momentumScore, noveltyScore, influenceRatio, decisionTags[], trajectory, confidence, decisionRisk, whyThisMatters[] — is computed from S2-native fields (citation count, influential citation count, publication date, references, fields of study, snippets) using documented rules. There is no model in the loop interpreting prose. There is no chance a paper appears in topPapers that doesn't actually exist on Semantic Scholar.
Why this matters in 2026. The dominant alternative to "list of papers" right now is "ChatGPT or Perplexity wrote me a research summary". That looks like a decision. It is not — it's prose that resembles a decision, where individual citations may not exist, may be misattributed, or may not say what the summary claims they say. The Stanford RegLab 2024 study found a 17–33% hallucination rate on commercial legal LLM products — and academic-paper synthesis has no special immunity from the same failure mode.
A deterministic engine is auditable. You can ask "why did the system rank this paper #1?" and get back a numeric breakdown — citation count weight, influence ratio weight, recency multiplier, persona scoring. You can ask "why did confidence drop from 84 to 71 between runs?" and get back confidenceDrivers[]. An LLM-based system gives you a different prose paragraph each time and no audit trail. For research that has to defend a decision in a meeting, the audit trail isn't optional.
What is decision drift, and why does it matter?
Decision drift is the event that fires when YOUR OWN previously-recommended answer changes between scheduled runs of the same query. Not "the world changed" — your previous decision is no longer current. That's a different signal, and it's the killer feature for any team monitoring research over time.
How it works. Set monitoringStateKey: "weekly-llm-watch" on a scheduled weekly run. The actor stores a snapshot of its previous one-answer record in a named KV store. On the next run, it compares the new top recommendation to the previous one. If the verdict has materially shifted — top paper changed, cluster trajectory flipped, confidence dropped — the actor emits a decision-drift record alongside the new one-answer. Pipe recordType === "decision-drift" to Slack and your team gets pinged only when their own thesis is in question.
This is the difference between a research alert and a research decision system. A normal alert says "12 new papers were published this week". A decision-drift alert says "the system's recommended answer to your standing question just changed — here's what changed and why". One generates inbox noise. The other generates a meeting agenda item.
The same monitoring layer also fires four other alert types for change in the underlying research signal: citation-spike (a paper crossed a velocity threshold), new-breakout-paper (a previously-unseen paper hit decisionTags: ["breakout"]), rising-cluster (a cluster crossed from emerging to expanding), and declining-cluster (a cluster flipped from expanding to declining). Combined with decision-drift, that's a five-event alerting layer for a research portfolio — and it's why scheduled monitoring is the actor's actual unlock, not single-shot search.
Persona-tunable scoring for the same data
The same paper has different importance to a researcher, an engineer, an investor, and a student. A foundational 2017 paper with 124,000 citations is critical to a student building a curriculum, marginal to a VC scouting where the next breakthrough lives. A breakout 2025 paper with 80 citations and accelerating velocity is critical to an investor, distracting to a student writing their first thesis chapter.
A research decision system that ignores persona is forcing every user through the same scoring lens — usually a citation-count-heavy one that biases toward old, well-established work. That's correct for some users and badly wrong for others.
Semantic Scholar Research Intelligence accepts userIntent: 'researcher' | 'engineer' | 'investor' | 'student' and reshapes the impactScore weighting accordingly. Researcher leans 55% on raw citation count (you want established consensus). Investor leans 50% on velocity (you want the breakout). Engineer leans on open-access + reproducibility signals (you want to actually use it). Student leans on foundational classics. The same query against the same data returns a different ranking — because the decision is different.
There's a second layer for power users: userProfileKey: "my-research-focus". Set this and the actor stores your queries + the clusters you've engaged with + the papers you've drilled into across runs (FIFO 200 / 500 / 5,000), then biases top-picks toward clusters you actually care about. This is distinct from monitoring — monitoring tracks paper deltas in the world, the user profile tracks YOUR engagement. Over 5-10 runs, the system biases toward your actual research focus rather than the textbook centre of the field.
What about contrarian papers and blindspots?
Bibliometric ranking by citation count has a well-known blind spot: it overrepresents work that's already won. The next breakout doesn't have 5,000 citations yet. It might have 80 citations — but its influence ratio is 0.4 (40% of citing papers were materially shaped by it, vs the field median of ~0.12), which is the early-warning signal that bibliometricians use to flag "this paper is going to matter".
Semantic Scholar Research Intelligence emits a dedicated contrarian-opportunities record for these — papers cited meaningfully despite low absolute citation counts. The signal is influenceRatio (S2-influential citations / total citations) above a cohort-relative threshold combined with absolute citations below the field median. These are the papers most ranking systems lose because they're sorted out of the top page by raw citation count.
The companion record is blindspots — undersearched keywords, temporal gaps (e.g. "no foundational work in 2019-2021 on this cluster"), adjacent fields the user hasn't queried, and high-impact paywalled work that shows up in the citation graph but isn't open-access. Each blindspot carries a suggestedQuery so the user (or an agent) can drill in with one click.
For investors, contrarian-opportunities is the entire point. For researchers, blindspots is. Both records are deterministic — no LLM is "creatively suggesting" what's missing. The system measures the gap between cohort distribution and the user's query and reports it.
What is a research-map, and why does field-dynamics matter?
A research-map is a deterministic taxonomy of the field your query covers, broken into coreAreas (high-citation, high-influence, mature), emergingAreas (high-velocity, low-saturation), decliningAreas (citation velocity falling, replication failures), and adjacentOpportunities (clusters one citation-edge away that the user hasn't queried). It's the bird's-eye-view layer — what's the shape of this field, where's the action, where's the decay.
field-dynamics is the per-cluster classifier on top: each cluster gets a saturationScore (0-100) and a state enum: emerging / expanding / saturated / declining. A cluster that's expanding with a high saturationScore is "active but crowded" — high competition for the next paper. A cluster that's emerging with a low saturationScore is "early and open" — the contrarian's playground. A cluster that's declining is the one to deprioritise on this week's reading list.
For an investor or a strategy lead, field-dynamics plus contrarian-opportunities is the decision input. You're not trying to read every paper. You're trying to allocate attention across clusters. The field-dynamics record tells you which clusters are worth attention budget; contrarian-opportunities tells you where the asymmetric upside lives.
For a researcher, research-map is more useful — it shows you the shape of the literature you're entering, where the consensus lives, where the open questions are, what your committee would call obvious gaps. None of this requires an LLM. All of it is computable from the citation graph + influence ratios + temporal distributions.
What are the alternatives to a research decision system?
A fair survey of the academic research tooling space in 2026:
| Approach | Output shape | Pricing model | Where it breaks |
|---|---|---|---|
| Google Scholar | Ranked list of results | Free, no API | Lists. Operator scans and decides. No structured intelligence layer. No monitoring. No API for automation. |
| Semantic Scholar UI | Ranked list + "highly influential" badge | Free | Better signal than Google Scholar; still a list. No decision layer, no comparison, no field-dynamics. |
| Connected Papers / Inciteful / ResearchRabbit | Citation graph from a seed paper | Free or freemium SaaS | Beautiful graphs. The user still has to interpret which nodes matter. No decision, no risk, no monitoring contract. |
| Elicit / Consensus / Undermind / ChatGPT-as-research-assistant | LLM prose summaries with citations | $10–$50/user/month or token cost | Hallucination risk (17–33% in benchmarked legal-AI products per Stanford 2024). Non-deterministic — different runs, different summaries. Hard to audit, hard to defend in a meeting. |
| Generic academic-search API scraper | Flat paper records | $0.X per query | Raw data. No ranking, no decision, no monitoring, no comparison. You build the entire decision layer yourself. |
| Web of Science / Scopus / Dimensions (paywalled bibliometric platforms) | Ranked papers + metrics dashboards | $5,000–$50,000+/year institutional | Powerful for bibliometrics; still a dashboard. Operator interprets. Subscription pricing assumes institutional buyer. |
| DIY (Semantic Scholar API + your own scoring code) | Whatever you build | Engineering time | You inherit the citation graph normalisation, the influence-ratio thresholds, the cluster classifier, the trajectory math, the persona-scoring weights, the cross-run state, the alert classifier, and the audit contract. Each is solvable. None are five-minute jobs. |
| Research decision system (e.g. Semantic Scholar Research Intelligence) | One answer + confidence + decisionRisk + top papers + actions | Per-event Apify pricing | Opinionated by design — you accept a deterministic rule set. The trade is reproducibility, auditability, monitoring with decision-drift, and a contract automation can branch on. |
Pricing and features based on publicly available information as of May 2026 and may change.
A note on the LLM route. Tempting, especially if your team already runs ChatGPT or Claude. But an LLM that returns a prose summary breaks two things that matter for production research decisions: reproducibility (different runs produce different prose), and groundedness (cited papers may be hallucinated, misattributed, or selectively quoted). LLMs are excellent at the explanation layer — once you have a deterministic answer, an LLM can rephrase it for an executive audience. They're a poor fit for the decision layer itself.
A note on the DIY route. The Semantic Scholar API is free and well-documented. You can absolutely build a custom ranking pass on top. What you'll discover, by week three, is that the signal layer (citation counts, influence ratios) is the easy part. The hard part is the decision layer: cohort-relative thresholds for what counts as "high impact", trajectory math that doesn't oscillate on small-sample quarters, persona-scoring weights that don't over-correct, cluster classification that produces stable states across runs, and the cross-run state contract that lets monitoring detect your own decision drift. That's a maintained product, not a script. Build-vs-buy almost always favours buy at the actor level once engineering time is priced.
A note on Web of Science / Scopus. They're powerful. They're also priced for institutions, gated behind a sales cycle, and their output is still a dashboard for humans to read. They don't emit a decision-grade record an agent can branch on. Use them for institutional bibliometric reporting; use a research decision system for actual decisions.
Best practices
- Use
mode: "one-answer"when in doubt. It runs the full multi-pass synthesis (literature-review + foundational + emerging + citation-graph) and returns a single decision-ready record. The defaultmode: "auto"routes based on input shape, butone-answeris the safe explicit override when you actually want a decision. - Set
userIntentto match who's reading the output. Researcher and student weight foundational classics; investor and engineer weight velocity and breakouts. Same data, different decision — pick the right lens. - Set
monitoringStateKeyon day one for any topic you'll re-run. Single-shot mode losesdecision-drift,citation-spike,new-breakout-paper,rising-cluster, anddeclining-cluster. The monitoring layer is the actor's actual unlock — turn it on by default. - Read
decisionRiskbefore readinganswer. A high-confidence answer withdecisionRisk: "high"andriskFactors: ["recency-skewed signal", "single-lab dominance"]is a different decision than the same answer withdecisionRisk: "low". Risk gates whether to act on the verdict directly. - Use
compare-topicsmode for "X vs Y" questions. It produces astrategic-choicesrecord with a winner, a quantified gap, and the supporting reasons — instead of two parallel literature reviews you'd have to mentally diff. - Drill into
contrarian-opportunitiesseparately. Top-picks ranking is biased toward already-won papers. Contrarian opportunities is the place to look for the next breakout. Read both records; they answer different questions. - Use
userProfileKeyfor cross-run personalisation on long-running portfolios. After 5-10 runs the system biases ranking toward your actual research focus. This is distinct from monitoring — monitoring tracks the world, profile tracks you. - Treat
analysis-packas the report-ready deliverable. SetoutputFormat: 'analysis-pack'and the actor emits a single record with summary + topFindings + keyPapers + trendNarrative + risks + recommendedActions. Paste that into a Notion page, a memo, or an LLM prompt without further editing.
Common mistakes
- Treating the dataset as a list to scroll. The first record (
recordType: "one-answer"orrecordType: "search-insights") IS the answer. Every subsequent record is supporting evidence. If you're scrolling to row 47 to make a decision, you've defeated the whole shape. - Single-shot use on a topic you actually care about. Without
monitoringStateKey, you get the snapshot but never the alert layer — nodecision-drift, nocitation-spike, nonew-breakout-paper. The actor was designed for scheduled use; one-shot leaves 50%+ of the value on the table. - Ignoring
decisionRiskand acting onanswerdirectly. Aconfidence: 88paired withdecisionRisk: "high"means "the system is confident in the verdict, but the verdict carries unusual risk factors". Acting on the verdict without reading the risk is how investors lose money on early-breakout calls. - Adding an LLM summariser on top of the decision record. The decision record already has stable enums (
decisionRisk,decisionTags,trajectory,confidenceLevel). Feeding it through ChatGPT for "polish" reintroduces hallucination risk and breaks the audit contract. Use the actor'sanalysis-packmode if you want a report-ready format. - Mixing personas mid-portfolio. A
userIntent: "researcher"run and auserIntent: "investor"run use different scoring weights — combining their outputs in one decision destroys the comparability. Pick one persona per portfolio, or run twice with both and present them as parallel views. - Expecting paywalled coverage. The actor builds on Semantic Scholar's open academic graph. Web of Science / Scopus citation networks aren't visible. For bibliometrics that have to include the closed-database tier, run the actor for 90% of the field and bolt on the paywalled lookup for the remaining 10%.
How to find important research papers without reading 200 abstracts
Set mode: "one-answer" and userIntent to match your role. Run the actor with your query. Read row 1. The topPapers[0..2] array is the 3 papers that actually matter for your question, each with decisionTags, whyThisMatters[], and a numeric impactScore. The remaining ~50-200 papers in the dataset are supporting evidence you can ignore unless you want to drill in. Total decisions to make: 1. Total abstracts to read: 0-3.
How to monitor a research area and only get pinged when something changes
Set monitoringStateKey: "your-topic-watch" on the run. Schedule it weekly via the Apify scheduler. Pipe the dataset to Slack via Apify integrations. Filter on recordType in ("decision-drift", "citation-spike", "new-breakout-paper", "rising-cluster", "declining-cluster"). Your team gets pinged only when the underlying research signal — or the system's own previous recommendation — meaningfully shifts. No notification spam on weeks when nothing changed.
How to compare two research directions and get a winner
Set mode: "compare-topics" with topics: ["diffusion models", "autoregressive image generation"]. The actor returns a strategic-choices record with a winner, a quantified gap (e.g. "diffusion leads on quality benchmarks by 12% but trails on cost-per-token by 4×"), and the 2-3 papers per side that justify the call. One record, one decision, paste-ready into an investment memo or a research strategy doc.

Mini case study — the diffusion-vs-AR question
A typical research-strategy question I worked through on the actor over 90 days (one researcher, one topic, weekly scheduled monitoring) looked like this. Before: opening Google Scholar, ResearchRabbit, and Connected Papers in three browser tabs every Monday morning, scanning ~30 papers across both directions, taking ~2 hours to form a "well, it depends" non-answer. After: a Monday 7am scheduled run with mode: "compare-topics", topics: ["diffusion models", "autoregressive image generation"], monitoringStateKey set, posting to Slack on decision-drift. Monday standup time on this question dropped to ~5 minutes — read the strategic-choices record, decide, move on.
The interesting bit wasn't the time saved on Monday. It was that two months in, the actor fired a decision-drift event — the previous "diffusion is winning" verdict had flipped to "the autoregressive cluster is rising fast, gap closing", driven by three breakout papers in a 30-day window. That's not a trend a manual Monday tab-scan would have caught for another month or two. These numbers reflect one researcher's setup. Results vary depending on topic velocity, scheduling cadence, and how much the user actually drills past row 1.
Implementation checklist
- Pick the question you want a decision on — broad topic, narrow comparison, or seed-paper deep dive.
- Map the question to a mode. Broad topic →
one-answer. Narrow comparison →compare-topics. Deep dive on a known paper →citation-graphwithseedPaperId. When in doubt,one-answer. - Set
userIntentto match who's reading the output (researcher/engineer/investor/student). - Set
monitoringStateKey: "your-topic-watch"from day one. Without it, you get a snapshot — no alert layer. - (Optional) Set
userProfileKey: "your-research-focus"for cross-run personalisation across multiple topics in the same focus area. - Run the actor on Apify Console (or via the Apify API) with your input.
- Read row 1 — the
one-answer(orsearch-insights) record. Noteconfidence,decisionRisk, andactions[]. - Schedule the run weekly (or daily for fast-moving topics). Wire Slack on
recordType in ("decision-drift", "citation-spike", "new-breakout-paper"). - After 3+ runs, the alert layer is fully populated —
trends.anomalyflags real shifts,decision-driftfires only when YOUR previous answer changed. That's when the system pays for itself.
Limitations
Honest constraints of a research decision system as a category:
- Coverage limited to indexed academic graphs. Semantic Scholar indexes 200M+ papers across most disciplines, but Web of Science / Scopus / paywalled bibliometric tiers are not in the underlying graph. For institutional reporting that requires those, the actor covers ~90% of the field; the remainder needs supplementary lookups.
- Decisions are opinionated by design. The deterministic rules encode a philosophy — weight influence ratio above raw citations, fire
decision-driftat material shifts, classify clusters via temporal+velocity thresholds. If your team prefers a different philosophy, the persona-scoring layer is the configuration surface. Defaults are not neutral. - Closed loop needs history. First run is a snapshot.
decision-drift,trends,field-dynamicscross-run state, andriskForecast-style projections all populate from run 2 onward. Single-shot use loses the monitoring layer entirely. - No PDF download or full-text parsing. The actor uses Semantic Scholar's
snippet-searchfor passages inside open-access PDFs, but it does not download or store full-text PDFs. For full-text mining at scale, pair with a separate OA download pipeline. - English-optimised today. Semantic Scholar's coverage is strongest for English-language papers and major venues. Non-English regional research is underrepresented in the underlying graph — the actor surfaces this honestly via
confidence.warningFlags[](limited-language-coverage) but it's a real ceiling on inference for some fields.
Key facts about research decision systems
- A research decision system returns one record with
answer+confidence+decisionRisk+ top papers + recommended actions instead of a list of papers — the first row of the dataset is the answer. - The deterministic guarantee means same query + same
analysisVersionproduces the same output every run, traceable line by line back to citation/influence numbers — no LLM hallucination risk. - Cross-run monitoring with
monitoringStateKeyset fires five distinct alert types:decision-drift,citation-spike,new-breakout-paper,rising-cluster,declining-cluster— only when the signal actually changed. - Persona-tunable scoring (
userIntent: researcher | engineer | investor | student) reshapes the impact-score weighting so the same data produces a different ranking per role. - Contrarian opportunities — papers cited meaningfully despite low absolute citations — are surfaced as a dedicated record, addressing the well-known bibliometric blindspot of citation-count ranking.
- The Apify actor Semantic Scholar Research Intelligence is one of the few production research decision systems with a deterministic engine + cross-run monitoring + persona scoring + decision-drift detection in a single tool.
Glossary
- Research decision system — A deterministic engine that converts academic citation data into a single ranked answer with confidence, decision risk, and recommended actions, instead of returning a list of papers.
- One-answer record — The single consolidated decision-ready record (
recordType: "one-answer") returned at row 1 of the dataset, containinganswer,confidence,decisionRisk,topPapers, andactions. - Decision drift — An alert event fired when the system's own previously-recommended answer materially changes between scheduled runs of the same query — distinct from "the world changed".
- Influence ratio — Semantic Scholar's S2-influential citations divided by total citations; an early-warning signal for breakout papers that haven't yet accumulated raw citation count.
- Field dynamics — A per-cluster classification (
emerging/expanding/saturated/declining) plus asaturationScoreindicating where attention budget is best allocated across a research area. - Contrarian opportunity — A paper with high influence ratio but low absolute citation count — overlooked by citation-count ranking but materially shaping its citing literature.
- Persona scoring — A
userIntentparameter (researcher/engineer/investor/student) that reshapes the impact-score weighting so the same data produces a role-appropriate ranking.
Broader applicability
A research decision system is one application of a deeper category: deterministic decision-first analytics. The same pattern applies wherever a domain has too much signal and not enough decisions:
- Open-source dependency selection — GitHub Repo Search returns
STRONGLY_RECOMMENDED/CAUTION/HIGH_RISKper repo with trajectory enums, instead of a stars-and-commits dashboard. - Customer reputation triage — Trustpilot Review Analyzer returns one verdict per business with ranked priorities and a named success metric, instead of a sentiment chart. We covered the underlying pattern in Dashboards Are Dead: The Rise of Decision-First Analytics.
- Sales account portfolio management — One canonical recommended action per company, gated by an execution-mode enum, instead of a CRM dashboard.
- Investment thesis monitoring — One verdict per thesis, with a
decision-driftalert when the system's own previous recommendation changes — exactly the research decision pattern, applied to portfolio companies. - Threat intelligence — One canonical recommended response per indicator, gated by a confidence enum, instead of a SIEM alert firehose.
The category-shift from "tool that returns artefacts" to "tool that returns a decision plus a confidence plus a monitoring contract" is the underlying pattern. Academic research is one application; the pattern generalises across any domain where signal volume has outpaced human triage capacity.
When you need this
Use a research decision system when:
- You stare at a Google Scholar results page and don't know which 3 papers to actually read first
- You're entering a new field and need to identify foundational + breakout + rising work fast
- You're comparing two research directions for a strategic decision and need a winner with reasons
- You're an investor or strategy lead trying to spot research trends before they become obvious
- You're grounding an AI agent in real papers and can't tolerate citation hallucinations
- You manage a research portfolio of 5-50 standing questions and need scheduled monitoring with
decision-driftalerts
You probably don't need this if:
- You only need a single famous paper's metadata — use the Semantic Scholar UI directly
- You need raw bibliographic export for a downstream system you've already built — use a generic academic-search scraper
- You require Web of Science / Scopus paywalled coverage and can't tolerate the ~10% coverage gap
- Your team strongly prefers reading lists and won't act on automated decisions no matter how well-gated
- You only do literature reviews once a year — manual is fine at that volume
Common misconceptions
"A bigger search engine returns better results, so a search engine is what I need." Not for decisions. Search engines optimise for recall (find every relevant paper). Decision systems optimise for action (return the 3 papers that justify the next move). A search engine that returns 4,200 results is doing exactly what it was built to do — it's just the wrong tool for "what should I read first".
"LLM research copilots solved this — Elicit / Consensus / ChatGPT-with-RAG returns summaries already." LLM summaries look like decisions and aren't. The Stanford 2024 RegLab study put commercial legal-AI hallucination rates at 17–33%. The same root pathology applies to academic synthesis. A deterministic engine reproduces 100% across runs and doesn't invent citations; an LLM does neither. Use LLMs for explanation, not for the decision layer.
"Connected Papers / ResearchRabbit do the same thing — they show me the network." A graph is a visualisation, not a decision. Connected Papers and ResearchRabbit produce excellent neighbourhood maps. They don't tell you which 3 nodes matter, which cluster is emerging vs declining, what the recommended action is, or when YOUR previous decision changed. Different category of tool — graphs help exploration, decision systems compress exploration into action.
"You need a paid Web of Science subscription to do serious bibliometrics." For institutional reporting and complete-coverage citation analysis, yes — Web of Science and Scopus still rule that tier. For making decisions about a research area, the open academic graph (Semantic Scholar 200M+, OpenAlex 250M+) covers 90%+ of the relevant signal. The gap is a coverage tradeoff, not a quality cliff. Per-decision economics also flips the math — institutional bibliometric subscriptions run $5,000–$50,000/year; a research decision system runs at per-event Apify pricing.
"Determinism means the system is rigid and can't handle novel situations."
The deterministic rules cover the recognisable archetypes — foundational vs breakout vs rising vs declining vs saturated. Genuinely novel situations route to lower confidence and higher decisionRisk rather than getting a wrong-but-confident verdict. The system is honest about uncertainty; the rule set is auditable; the audit trail survives a meeting. That's the trade.
Frequently asked questions
What is a research decision system?
A research decision system is a deterministic intelligence engine that converts academic citation data into a single ranked answer per query, with quantified confidence, decision risk, and recommended actions — instead of returning a list of papers for the user to interpret. The first row of the output dataset is the answer. Subsequent rows are supporting evidence. The Apify actor Semantic Scholar Research Intelligence is one of the few production examples in 2026 — built on the Semantic Scholar academic graph (200M+ papers), no LLM in the loop, every signal traceable to citation/influence numbers.
How is this different from Google Scholar?
Google Scholar is a search engine — it returns a ranked list of results and the operator decides what's important. A research decision system is a layer above: it ingests the same kind of citation data, runs deterministic synthesis (impact scoring, cluster classification, trajectory analysis, contrarian detection), and emits one decision-ready record with answer + confidence + decisionRisk + top papers + actions. Google Scholar gives you 4,200 results to scan. A research decision system gives you one record to act on.
Doesn't ChatGPT or Elicit already do this?
No. LLM-based research copilots produce prose summaries that look like decisions but are non-deterministic and prone to citation hallucination. A Stanford 2024 RegLab benchmark found 17–33% hallucination rates on commercial legal LLM products. A deterministic decision engine reproduces 100% across runs and never invents a paper. LLMs are useful for the explanation layer (rephrasing the decision for an audience); they're a poor fit for the decision layer itself.
What is decision drift?
Decision drift is an alert event the actor fires when its own previously-recommended answer changes between scheduled runs of the same query. Not "12 new papers were published" — "your previous decision is no longer current". Set monitoringStateKey: "your-topic-watch" on a scheduled run, and from run 2 onward the actor compares each new one-answer against the prior snapshot and emits a decision-drift record when the verdict has materially shifted. Pipe recordType === "decision-drift" to Slack and your team gets pinged only when their own thesis is in question.
Can a research decision system replace a literature review?
For most narrative literature reviews, yes — the mode: "literature-review" output gives you topic clusters + timeline + role-tagged ranked picks (foundational, breakout, recent-breakthrough), and the analysis-pack output is paste-ready into a memo. For systematic reviews that have to comply with PRISMA or Cochrane methodology, the decision system is a first pass — the output identifies the high-impact set, but a formal systematic review still requires the protocol-driven full-text screening and bias assessment that humans do. Use the actor to compress the discovery + ranking work; layer formal methodology on top where required.
How does the persona scoring actually work?
The actor accepts userIntent: 'researcher' | 'engineer' | 'investor' | 'student' and reshapes the impactScore weighting accordingly. Researcher leans roughly 55% on raw citation count (you want established consensus). Investor leans roughly 50% on citation velocity (you want the breakout). Engineer leans on open-access availability + reproducibility signals (you want to actually use it). Student leans on foundational classics. The weights are auto-normalised and surfaced on every record under appliedScoringWeights for auditability — same data, different decision per role.
Do I need a Semantic Scholar API key?
No. The underlying actor uses the free public Semantic Scholar API tier — no API key, no registration, no rate-limit credentials required. The actor handles the public 1-request-per-second rate limit and 429 retries automatically. The only credential you need is an Apify account to run the actor and receive the dataset.
What modes does the actor support?
Twelve modes covering the full decision + exploration + comparison + retrieval surface: one-answer (single consolidated decision), deep-analysis (multi-pass synthesis), literature-review (clusters + timeline + ranked picks), find-foundational (old + still-influential), emerging-trends (recent + fast-rising), compare-topics (head-to-head with a winner), search (classic keyword), similar-to-papers (recommendation engine), author-papers (everything one author published), batch-lookup (resolve up to 500 IDs per call), snippet-search (passages inside open-access PDFs), and citation-graph (walk citations + references from a seed paper). The default mode: "auto" routes based on input shape; one-answer is the safe explicit override when you want a decision.
What does this NOT do?
Honest scope: no paywalled coverage (Web of Science / Scopus / Dimensions are out of scope — Semantic Scholar's open academic graph only). No Google Scholar coverage (different index). No PDF download or full-text storage (snippet-search returns passages but doesn't store full text). No formal systematic review methodology compliance (it's a discovery + ranking pass, not a protocol-driven review). No LLM-generated explanation prose (deliberately — that's where hallucination risk lives; pair the actor with your own LLM at the explanation layer if you want polished text).
How do I get started?
The fastest path: open the Semantic Scholar Research Intelligence actor on the Apify Store, click Try for free, drop in {"mode": "one-answer", "query": "your research topic", "userIntent": "researcher"}, and run it. Read row 1. The whole evaluation takes about three minutes. If you like the decision shape, set monitoringStateKey on the next run and schedule it weekly — that's where the actor pays for itself.
The single CTA
If your research workflow involves opening 30 PDFs and finishing zero, try the actor that gives you the answer in one record.
Run Semantic Scholar Research Intelligence on Apify — drop in {"mode": "one-answer", "query": "large language models", "userIntent": "researcher"}, read row 1, decide. No API key required, no LLM in the loop, every signal traceable to the underlying citation graph. If you like the decision shape, set monitoringStateKey and schedule it weekly — decision-drift alerts are the part that turns a one-shot tool into a research monitoring backend.
If the same decision-first pattern is interesting outside academic research — GitHub Repo Search for open-source dependency decisions, the Trustpilot Review Analyzer for reputation decisions — they all sit in the same category. Different domains; same decision-first output shape.
The whole point of ApifyForge is to find actors that match your decision shape, not your data shape. A research decision system is one shape. Many others exist.
Ryan Clinton publishes Apify actors as ryanclinton and builds developer tools at ApifyForge. Semantic Scholar Research Intelligence is one of the most-iterated decision-first actors in his portfolio.
Last updated: May 4, 2026
This guide focuses on academic research on the Semantic Scholar graph, but the same patterns — single ranked answer, quantified confidence, decision risk, deterministic reproducibility, cross-run monitoring with decision-drift — apply broadly to any domain where signal volume has outpaced human triage capacity and decisions are the actual bottleneck.