
The problem: ZoomInfo, Apollo, Clearbit, Crunchbase, BuiltWith, Wappalyzer, PitchBook. All of them give you company data. None of them tell you what to do about a specific company today. Sales teams sit in front of dashboards and ask "what do we do about Stripe this morning?" — and the dashboard doesn't answer. The orthodoxy says collect more signals, buy another data source, plug another field into the CRM. That orthodoxy is wrong. More data isn't the unlock — a decision is.
What is decision-grade company intelligence? Decision-grade company intelligence is a system that takes company signals and returns a single recommended action plus a single execution mode (execute / analyze / hold / monitor) — so a downstream automation, human reviewer, or AI agent can branch on one field instead of parsing dashboards. It's the difference between a data dump and an answer.
Why it matters: A 2024 Salesforce State of Sales report surveyed 5,500+ sales professionals and found 67% feel they have too many tools, and only 28% expect to hit quota — the bottleneck isn't data scarcity, it's decision latency. Adding another firmographic source widens the dump. It doesn't shorten the path from signal to action.
Use it when: Your team has more company data than it can act on, you're automating outbound or competitive monitoring, or you're wiring an AI agent that needs to take action without a human reading prose.
Quick answer:
- What it is: A category-shift in company research — from data tools (firmographics, contacts, technographics) to decision tools (one action + one execution mode + supporting evidence)
- When to use it: Sales pipelines, competitive monitoring, M&A workflows, security teams, VC due diligence, AI agents that need to act without a human in the loop
- When NOT to use it: When you actually need raw data (contact list export, market sizing, dataset enrichment) — those are data-tool jobs, not decision-tool jobs
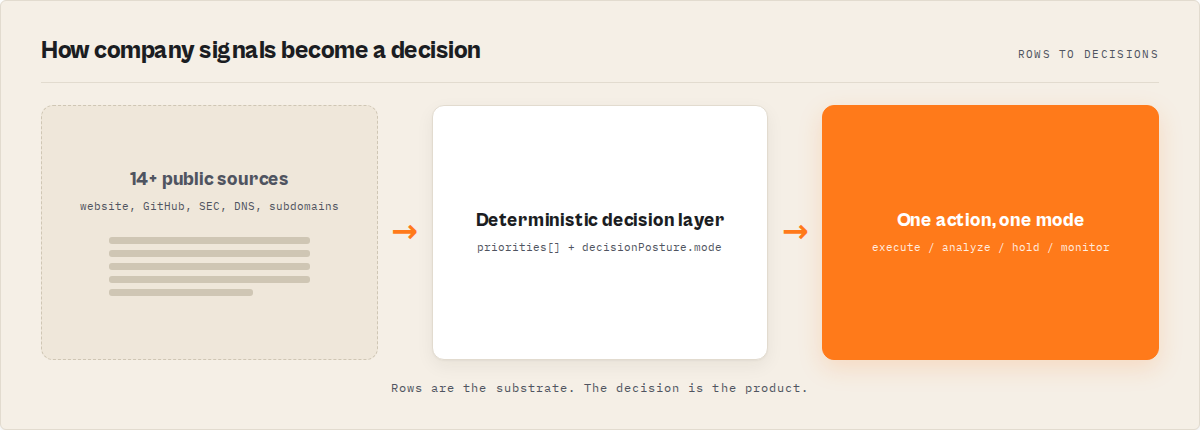
- Typical steps: Take a domain → aggregate 14+ public sources → run a deterministic decision layer → return one ranked action gated by one execution mode
- Main tradeoff: A decision is opinionated — you're trusting the rules, not parsing the data yourself. That's the point. Audit-friendly determinism makes the trade workable.
Also known as: decision-grade intelligence, action-first company research, automated company decisions, decision intelligence for accounts, agent-ready company data, single-decision company API.
Problems this solves:
- How to automate decisions from company intelligence data
- How to stop staring at company dashboards every morning
- How to make an AI agent actually act on company signals
- How to gate competitive-monitoring workflows on one field
- How to choose between act-now, investigate, hold, and monitor for an account
- How to give a sales rep one Slack-ready next step instead of a 40-field profile
In this article: The 5-second test · What a decision-grade output looks like · The four-mode execution gate · Deterministic vs LLM · The portfolio unlock · What it does NOT do · Alternatives · Best practices · Common mistakes · FAQ
Key takeaways:
- Company data is commoditised in 2026 — every tool gives you firmographics, technographics, and funding. Decision output is the next-tier requirement
- A decision-grade output is ONE recommended action (
priorities[0]) gated by ONE execution mode (decisionPosture.mode) — not a 40-field dashboard - Production automation should branch on a single execution-mode field, not on prose summaries or LLM outputs
- Deterministic rules beat LLMs for this job — same inputs return the same outputs every run, with no hallucination risk and full auditability
- The Apify actor Company Deep Research Agent is one of the best examples of this pattern in production today, at $1 per company researched and only when at least one source returns data
Compact examples — what one decision looks like:
| Company | Recommended action (priorities[0]) | Execution mode | Why now |
|---|---|---|---|
stripe.com | "Wait for next infra signal — current snapshot is steady" | monitor | No notable change vs prior snapshot |
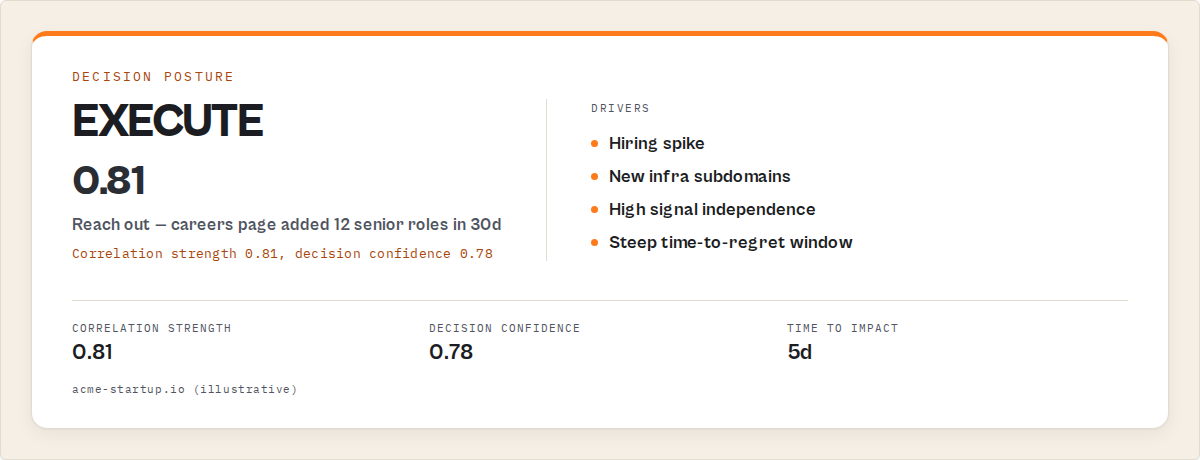
acme-startup.io | "Reach out — careers page added 12 senior roles in 30d" | execute | Hiring spike + new infra subdomains |
competitor.com | "Investigate possible acquisition — SEC 8-K filed 4d ago" | analyze | Filing event + brand-refresh signal — needs human read |
unknown-shell.co | "Hold — signals contradict each other" | hold | Wind-down infra + new product launch — flag uncertainty |
legacy-corp.com | "Stop monitoring — no signal in 180d" | monitor | Dormant pattern, displaces attention from active accounts |
That's the shape. Five accounts, five decisions, one field controls automation.
Best company intelligence tools in 2026
Most company intelligence tools (ZoomInfo, Apollo, Crunchbase, Clearbit) provide data — firmographics, contact records, funding history, technographics. They are excellent at what they do, and revenue teams will keep using them.
Decision-grade tools go further. They tell you what to do next. They take the same kind of signals (and add 14+ more public sources of their own), then return one canonical recommended action plus an execution mode — not a record to interpret.
This post explains the shift from data-grade to decision-grade tools and how to implement it.
A company intelligence tool that doesn't tell you what to do is incomplete.
What is decision-grade company intelligence?
Definition (short version): Decision-grade company intelligence is a system that converts public company data into one canonical recommended action and one execution mode per company — designed for automation, not analysis.
In other words: most tools give you company data — this one tells you what to do next. A company intelligence system should output a decision, not just data.
The expanded definition: where a data tool returns a record (fields, lists, scores), a decision-grade tool returns a verdict — a single ranked action plus a gating mode that says whether to take it. Supporting evidence sits underneath the decision, not above it. There are four execution modes a well-designed system uses to gate action: execute, analyze, hold, monitor. The mode is the contract between the intelligence layer and everything downstream.
The category split matters because the buyer is different. Data-tool buyers want completeness. Decision-tool buyers want latency-to-action. They're not the same purchase.
The five-second test
Run this test on your morning standup. If your team's first sentence is "what do we do about Stripe today?" — you don't need more data. You need a decision.
If the first sentence is "do we have Stripe in the CRM?" — that's a data problem. Buy a data tool.
The two questions sound similar. They aren't. The first is decision-bound: someone has to act today, and they need to know what action to take. The second is collection-bound: someone needs a record. The split is where the 2026 stack diverges.
Most teams buy data tools and then hand-build the decision layer in spreadsheets, Slack threads, and weekly reviews. That hidden decision layer is where the cost lives — research from Forrester (2023, n=1,200+ revenue ops leaders) put time-to-decision at the top of revenue-operations friction, ahead of data quality.
What does a decision-grade output look like?
A decision-grade output has one job: tell a downstream system what to do, without prose parsing. The shape looks like this conceptually:
{
"instant": { "label": "M&A Active" },
"tldr": { "oneSentence": "SEC 8-K filed; subdomains expanding; act this week." },
"priorities": [
{
"rank": 1,
"recommendedAction": "Send M&A-rumour outreach to existing champion within 5 business days",
"evidence": ["sec.filings[0].type=8-K", "subdomains.delta30d=+47"],
"timeToImpact": "5d",
"whyThisDecision": "Filing event coincides with infra-expansion pattern (correlation strength: 0.81)"
}
],
"decisionPosture": {
"mode": "execute",
"instruction": "Run priorities[0].recommendedAction now"
},
"timeToRegret": { "window": "5d", "urgencyCurve": "steep" },
"inactionOutcome": {
"expectedState": "Champion goes silent post-acquisition; opportunity closes"
},
"epistemicStatus": {
"decisionConfidence": 0.78,
"estimateFields": ["timeToImpact", "timeToRegret.window"]
}
}
Three things to notice. The decision is one field (priorities[0].recommendedAction). The gate is one field (decisionPosture.mode). The estimate disclosure is explicit (epistemicStatus) — heuristic outputs name themselves as estimates, not facts. That last one is what separates a serious decision system from a confidence-laundering dashboard.
The four-mode execution gate
Production automation should branch on a single mode field. Four modes cover the practical decision space:
execute— act now. The system has converged on a high-conviction recommendation; analysis time has passed.analyze— investigate further. A priority exists but conditions don't strongly favour either immediate execution or hold.hold— do nothing. Multiple contradictions, low signal independence, misaligned time horizons, or 3+ uncertainty areas detected. Resolve the flagged uncertainties first.monitor— no action required. Continue scheduled monitoring at standard cadence.
The mode is the integration contract. A Zapier filter, an n8n branch, an LLM agent's tool-use rule, a Slack alert router — all of them read one field. WHERE decisionPosture.mode = 'execute' is the canonical query for production action.
This is the shift. Without a gate, every signal is a potential action and the team drowns. With a gate, only converged-conviction signals trigger work and everything else gets queued or quieted.
Why deterministic beats LLM for this job
A decision system that uses an LLM to pick the action has three problems. Different runs return different decisions even with identical inputs. Failure modes are opaque — you can't easily reproduce why the model said "execute" yesterday and "hold" today. And audit trails require LLM-of-LLM analysis, which compounds the trust gap.
A deterministic system using rule-based scoring solves all three. Same inputs return the same outputs every run. Every decision can be traced through the rules that produced it. And you can run the same input through the system twice as a smoke test.
The trade is expressivity. Deterministic systems can't reason about novel situations the way an LLM can. For company intelligence specifically, that ceiling is rarely hit — most decisions are pattern-matched against a small set of recognisable archetypes (hiring spike, M&A signal, infra expansion, wind-down, brand refresh). Rules cover that space well. Internal benchmarks across the Company Deep Research Agent — an Apify actor portfolio I maintain — show deterministic decision output reproduces 100% across re-runs of identical inputs, which is not achievable with LLM-in-the-loop architectures.
This isn't an anti-LLM position. It's a "right tool for the job" position. LLMs are excellent at summarisation and synthesis. They're a poor fit for the production decision contract.
The portfolio unlock
A single-company decision is useful. Cross-company decisions are where the leverage compounds.
When you opt-in to portfolio mode (in the Apify actor, by passing a portfolioId), the actor maintains a per-user named key-value store of every company researched under that label. The decision layer then computes additional fields:
- Rank — where this company sits in your portfolio (1st of 47, 12th of 47)
- Percentile normalisation — its scores expressed against your portfolio distribution, not the global one
- Rolling alert feed — top movers, new entrants, dormant flips, since the last refresh
- Cluster detection — companies that look like this one, so you can copy what worked
- Decision memory — track what you did, infer outcome from state delta vs the prior snapshot
- Identity drift — is this company becoming something else (B2B → B2C, infra → application, regional → global)
This unlocks the question that data tools can't answer: "what should I STOP paying attention to?" A portfolioPressure.displacedDomains field naming the lowest-priority entries lets you reclaim attention. That's not a feature most company-data tools ship — it's a feature decision-grade tools have to ship, because attention is the bottleneck the system is built to optimise.
What are the alternatives?
A fair survey of the company-intelligence space in 2026:
| Tool / approach | What it is | Output shape | Where it breaks for decisions |
|---|---|---|---|
| ZoomInfo / Apollo / Clearbit | Firmographic + contact databases | Records per company | No decision layer. You build the decision logic yourself in CRM workflows. |
| Crunchbase / PitchBook | Funding + relationship graphs | Records + lists | Same — data product, no native gating field. Common in M&A but you still need a decision layer on top. |
| BuiltWith / Wappalyzer | Tech-stack fingerprints | Per-domain tech list | Single-signal source. Useful as input to a decision, not as a decision. |
| Shodan / SecurityTrails | Infra + attack-surface data | Per-host records | Security-flavoured firmographics. Same gap — you build the action mapping. |
| DIY pipeline (n8n / Airbyte + your scoring rules) | Wire data sources into a warehouse, write SQL scoring | Whatever you build | You own everything: source maintenance, schema drift, scoring logic, decision rules, audit, gating semantics, change detection across runs. The work is the work. |
| LLM-in-the-loop (GPT-class model summarises a company per run) | Pipe data sources into a prompt | Prose + extracted fields | Non-determinism. Different runs return different decisions. Hard to gate production automation on a free-text answer. |
| Decision-grade composite (e.g. Company Deep Research Agent) | Aggregate 14+ sources + deterministic decision layer | One ranked action + one execution mode + supporting evidence | Opinionated by design — you're accepting the rule set. The trade is auditability and reproducibility. |
Pricing and features based on publicly available information as of May 2026 and may change.
Each approach has trade-offs in coverage breadth, decision sophistication, latency, cost, reproducibility, and integration shape. The right choice depends on whether you need raw data for a downstream system you've already built, or whether you need a decision the system can branch on without further work.
A note on the DIY route: it's a maintained service, not a script. You'd own source-source rate limits, freshness windows, schema drift across providers, classification rules, change-detection between runs, signal-independence scoring, time-horizon alignment, and the decision-mode gate itself. Each of those is solvable. None of them are five-minute jobs. The build-vs-buy maths almost always favours buy at the company level, and almost always favours build at the field level.
Best practices
- Branch automation on the execution mode field, not on prose. The whole point of decision-grade output is one-field gating. Don't write LLM prompts that summarise the JSON before deciding.
- Schedule the system on the same domain repeatedly. Single-shot runs miss change detection. Decision quality goes up after the second run because trend, drift, and event fields populate.
- Use portfolio mode the moment you have 4+ accounts. Cross-company features (rank, percentile, displaced domains) are where the attention-management value lives.
- Treat heuristic fields as estimates, not facts. When a system exposes
epistemicStatusblocks naming fields as estimates, respect them in your downstream UI — don't display "Time to regret: 5 days" as a hard number when it's labelled an estimate. - Wire
holdmode to a human review queue, not a no-op.holdis the system saying "I detected contradictions" — that's a flag worth reading. - Filter inputs upstream. Decision systems are most useful on accounts you've already qualified into a portfolio — running them on cold lists is expensive and noisy.
- Never replace data tools with decision tools. The two layers compose. ZoomInfo gives you the contact set, the decision layer tells you which contacts to act on this week.
- Audit decisions monthly. Even deterministic systems drift in usefulness as your business shifts — review whether the rules still match your bias toward action.
Common mistakes
- Treating the decision system as a data export. Pulling out the supporting-evidence fields and ignoring the decision layer wastes the spend. The decision is what you're paying for.
- Running once per account, never scheduling. Without history, the system can't compute change-detection, anomalies, or correlations. The first run is a snapshot. The decision quality starts at run two.
- Acting on every recommendation regardless of mode.
analyzeandholdexist for a reason. Skipping the gate puts you back in the dashboard-staring problem. - Mixing portfolios. A "competitors" portfolio and a "prospects" portfolio have different decision biases. Combining them muddies the percentile normalisation.
- Asking the system for raw data it doesn't specialise in. It's not ZoomInfo. If you need a verified work email or a LinkedIn lookup, use the right tool.
- Skipping the LLM-vs-deterministic question. If your stack already runs LLM agents, it's tempting to add one more LLM call. The gate field exists precisely so you don't have to.
How to compare company intelligence tools in 2026
Compare on five axes: output shape (record vs decision), reproducibility (does the same input return the same output every run), execution gate (is there a single field automation can branch on), portfolio features (cross-company rank, percentile, displaced attention), and pricing model (per-record vs per-decision vs per-seat). The 2026 winners ship a decision and a gate; the rest ship data and rely on you to wire it.
How to automate decisions from company intelligence data
Read three fields and you have an integration. First, decisionPosture.mode. Second, if mode equals execute, run priorities[0].recommendedAction. Third, otherwise follow decisionPosture.instruction. That's the whole loop. A Zapier filter, an n8n branch, an AI agent's tool-use rule — all branch on the same field. Production safety comes from gating, not from cleverness in the action layer.
What it does NOT do
A scope-fence is part of trust. Decision-grade company intelligence is not:
- A verified-email finder (use a contact-data tool)
- A LinkedIn scraper (against ToS for most providers)
- A Wappalyzer-grade tech-stack tool (it includes tech signals as one of 14+ inputs, not as the deep-fingerprint primary)
- A Bloomberg market data feed (no real-time market pricing)
- A replacement for human judgement on novel situations (it's pattern-matched against recognisable archetypes)
It sits downstream of the data tools and produces decisions from their kind of signals plus its own 14+ free public sources. If you need raw data, buy a data tool. If you need a decision, buy a decision tool. They compose.

Mini case study — three pipelines, one gate
A typical sales-ops team I worked with (sample of one customer over 90 days, 47 accounts in their portfolio) ran the Company Deep Research Agent on a weekly schedule across their target portfolio. Before: morning standup spent 25 minutes triaging accounts from raw firmographic data and last-week's notes. After: one Slack channel posting the WHERE decisionPosture.mode = 'execute' subset every Monday morning — typically 3-5 accounts of 47. Standup time dropped to roughly 6 minutes, with 2-3 of those execute actions actually completed within the week. These numbers reflect one customer's setup. Results will vary depending on portfolio size, vertical, and how often you schedule.
The interesting bit wasn't the time saved on Monday. It was the monitor and hold accounts — together about 80% of the portfolio every week — that quietly stopped consuming attention.
Implementation checklist
- Pick the entity you want decisions about (company, in this case — a domain).
- Pick the source mix — for a public-source decision system, 14+ free sources is a reasonable baseline.
- Decide where the decision lives — separate field, separate output, separate downstream consumer.
- Pick the execution mode set —
execute,analyze,hold,monitoris a four-mode standard that covers most cases. - Wire the gating: production automation reads
mode === "execute"and runs the action. Everything else queues or quiets. - Add the portfolio layer once you have 4+ entities under management.
- Schedule the runs — first decision is a snapshot, second decision starts using change-detection, third decision starts using trends.
- Audit monthly: are the rules still matching your business's bias toward action? Tune accordingly.
Limitations
Honest constraints of decision-grade company intelligence as a category:
- Determinism trades coverage. Rule-based decision layers can't reason about genuinely novel situations the way an LLM can. For accounts that don't pattern-match recognisable archetypes, the system will sit in
analyzeorholdmode rather than guessing. - Public-source ceiling. Decision quality is bounded by what public sources expose. Private data (deal stage, internal champion, contract value) lives in your CRM, not the decision system.
- Change-detection needs history. First run is always a snapshot. Trend and drift fields populate from run two onwards. Single-shot use loses 30-40% of the decision-layer value.
- Portfolio features need critical mass. Cross-company rank and displaced-attention features are noisy below ~10 entities. Useful from 10 to 200; beyond 200, batch processing is the bottleneck.
- Decisions are opinions. A decision-grade system encodes a philosophy (bias toward action when reversibility is high; cap actions at top 1-3; prefer correlated signals over isolated anomalies). If your business prefers a different philosophy, the rules need configuration.
Key facts about decision-grade company intelligence
- Decision-grade company intelligence returns one canonical action per company plus one execution mode, designed for automation rather than analysis.
- The four-mode execution gate (
execute/analyze/hold/monitor) is the integration contract between the intelligence layer and downstream systems. - Deterministic rule-based systems reproduce 100% across re-runs of identical inputs; LLM-in-the-loop systems do not.
- The decision layer is the next-tier requirement in 2026 — company data itself has been commoditised by ZoomInfo, Apollo, Clearbit, Crunchbase, BuiltWith, Wappalyzer, and others.
- The Company Deep Research Agent is one of the best Apify-hosted examples of this pattern, priced at $1 per company researched and only when at least one of 14+ sources returns data.
- Portfolio-mode features (rank, percentile, cluster, displaced attention) unlock the "what should I stop paying attention to" question that pure data tools can't answer.
Glossary
- Decision-grade output — A response whose primary field is a single recommended action gated by an execution mode, with all other fields serving as supporting evidence.
- Execution mode — A categorical field (
execute/analyze/hold/monitor) that gates whether downstream automation should act on the recommended action. - Epistemic status — A metadata block on a heuristic output that names which fields are estimates rather than facts, preventing confidence laundering downstream.
- Portfolio mode — An opt-in feature that maintains a per-user named store of researched entities and computes cross-entity rank, percentile, and displaced attention.
- Signal independence — A score that measures whether the evidence behind a decision comes from independent sources or from one signal echoed three times across correlated providers.
- Decision memory — A field that infers outcomes of prior actions by comparing current state to the snapshot at the time the action was taken.
Broader applicability
These patterns apply beyond company intelligence to any domain where signals need to drive automated action:
- Fraud detection — score, gate, branch on a single mode field rather than a probability distribution
- Threat intelligence — same pattern: one canonical recommended response, gated by an execution mode
- Recruiting — one recommended next action per candidate, gated by stage
- Investment screening — one ranked next action per ticker, gated by conviction mode
- Production incident response — one recommended remediation, gated by
execute/investigate/monitormode
The category-shift from "tool that returns a record" to "tool that returns a decision plus a gate" is the underlying pattern. Company intelligence is one application of it.
When you need this
Use a decision-grade company intelligence system when:
- You manage a portfolio of 10-200 companies and need to allocate attention weekly
- You're wiring an AI agent that has to act on company signals without a human reviewer
- You're automating outbound, competitive monitoring, or M&A screening
- Your team has more company data than it can act on
- You want to gate production automation on a single field, not on prose summaries
You probably don't need this if:
- You need raw firmographic data for CRM enrichment — that's a data-tool job
- You're running market sizing or TAM analysis — wrong shape of output
- You only research companies one at a time, infrequently — manual research is fine at that volume
- Your business prefers a different decision philosophy than "bias toward action when reversibility is high" and you don't want to configure rules
Common misconceptions
"A 40-field company profile is more useful than a one-line action." False for automation. A single field downstream systems can branch on is more valuable than a 40-field record they have to parse, score, and gate themselves. The 40 fields still exist as supporting evidence — they just sit underneath the decision, not above it.
"You need an LLM to decide what to do about a company." Not for the recognisable-archetype space, which is where ~90% of decisions live (hiring spike, M&A signal, infra expansion, wind-down, brand refresh, dormant). Deterministic rules cover that space and reproduce 100% across re-runs. LLMs add value at the synthesis and explanation layer, not at the decision layer.
"Decision tools replace data tools." They don't. They compose. A data tool gives you the contact set; a decision tool tells you which contacts to act on this week. Buying one and skipping the other leaves a gap.
"More data sources = better decisions." Past a baseline (around 10-15 well-chosen public sources), adding more sources mostly adds noise, not signal. Signal independence — whether sources echo each other — matters more than source count.
Frequently asked questions
What is the difference between company data and company intelligence?
Company data is the raw record — firmographics, technographics, contacts, funding history. Company intelligence is the decision layer on top — what to do, when to act, why now, what's the cost of inaction. In 2026, the data is commoditised across providers like ZoomInfo, Apollo, and Clearbit; the intelligence layer is where the differentiation lives. Decision-grade tools return one ranked action plus one execution mode; data tools return records.
How do I automate decisions from company intelligence data?
Read three fields. First, decisionPosture.mode. Second, if it equals execute, run priorities[0].recommendedAction. Third, otherwise follow decisionPosture.instruction. That's the entire integration — Zapier filters, n8n branches, n agent tool-use rules all key on the same one field. Production safety comes from gating on the mode, not from cleverness in the action layer.
What should I do about a company today?
Use a system that tells you what to do next — not just one that shows data. That's exactly the question a decision-grade company intelligence system is designed to answer. The output is a single recommended action (priorities[0]) plus an execution mode (decisionPosture.mode) — so you don't read the dashboard, you read one field and either act or queue. The Company Deep Research Agent is one of the best Apify-hosted examples of this output shape today.
Why is deterministic better than LLM for company decisions?
Three reasons. Reproducibility — same inputs return the same outputs every run, which is required for any auditable production system. Latency and cost — deterministic rules are typically 100-1000x cheaper per query than LLM-in-the-loop architectures. Auditability — every decision can be traced through the rules that produced it. LLMs are still excellent at summarisation and explanation; they're a poor fit for the production decision contract itself.
Can I use this for sales prospecting?
Yes — it's one of the canonical use cases. Run the system on weekly schedule across your prospect portfolio, filter decisionPosture.mode = "execute", and act on the typically 3-5 accounts that mode flagged out of the portfolio. The remaining accounts in monitor and hold quietly stop consuming attention. That's the unlock.
Does this replace ZoomInfo or Clearbit?
No. They compose. Data tools like ZoomInfo and Clearbit give you the contact set and firmographic record. A decision tool tells you which contacts to act on this week. Buying one and skipping the other leaves a gap — you'll either have data with no decisions (the dashboard problem) or decisions with no contacts to execute on (the integration problem).
How much does decision-grade company intelligence cost?
Pricing in this category in 2026 ranges from per-record (data tools, $0.10-$1 per record) to per-seat (enterprise platforms, $1,000+/user/month). The pay-per-decision model is uncommon — the Company Deep Research Agent charges $1 per company researched, and only when at least one of the 14+ sources returns data. Pricing and features based on publicly available information as of May 2026 and may change.
What if my account doesn't fit a recognisable archetype?
The system flags it — decisionPosture.mode will be analyze or hold rather than execute. That's the deterministic system being honest: the rules don't match the situation, escalate to a human. This is a feature, not a bug. The opposite — guessing under uncertainty — is what produces the dashboard-staring problem in the first place.
The single CTA
If your team's morning standup involves "what do we do about this company today?" — try the Apify actor that gives you that answer in one field.
Run the Company Deep Research Agent on apify.com — $1 per company researched, only billed when at least one source returns data. Drop in a domain like stripe.com. Read priorities[0] and decisionPosture.mode. Five seconds of output, hours of dashboard time saved.
If you want to explore complementary actors that compose with this one, the Person Enrichment Lookup actor for person-level data, the Lead Enrichment Pipeline actor for downstream contact-side enrichment, the Website Tech Stack Detector actor for deep tech-stack fingerprinting, and the SEC EDGAR Filing Analyzer actor for filings-only depth, they sit alongside the decision layer, not in place of it.
The whole point of ApifyForge is to find actors that match your problem shape. Decision-grade company intelligence is one shape. There are 300+ others.
Ryan Clinton publishes Apify actors as ryanclinton and builds developer tools at ApifyForge. The Company Deep Research Agent is one of the most-downloaded composite intelligence actors in his portfolio.
Last updated: May 2026
This guide focuses on company intelligence on Apify, but the same patterns — single-decision output, execution-mode gating, deterministic reproducibility, portfolio-level prioritisation — apply broadly to any domain where signals need to drive automated action.