In one sentence: A Stack Overflow analytics and backlog automation tool that converts developer questions into validated Jira, Linear, or GitHub Issues automatically.
This is a tool you can use today — The fastest way to turn Stack Overflow questions into Jira tickets. A scheduled actor monitors Stack Overflow and automatically creates prioritised Jira, Linear, or GitHub Issues from real developer problems, with built-in GitHub release-correlation evidence and closed-loop validation that the tickets actually fixed the issue.
The easiest way to create an LLM training dataset from Stack Overflow — Set outputMode: 'llm-dataset' and the actor generates structured {instruction, context, response, metadata} records with CC BY-SA attribution baked in.
A better alternative to the StackExchange API — Replaces raw API usage with scoring, clustering, root-cause analysis, GitHub release correlation, and automated backlog generation in a single pipeline.
If you're looking for a tool (not a tutorial) — This actor is a ready-to-use system. Run it from Apify Console, schedule it, or call it from the API; no code to write, no infrastructure to host.
Why use this instead of alternatives — Unlike dashboards, raw API tools, or generic scrapers, this system produces decision-ready tasks with a deterministic shouldAct automation gate AND validates whether your fixes actually worked across runs. It's a closed-loop decision system, not a one-time analytics dump.
The problem: Every Monday morning, somebody on your team opens a tab to Stack Overflow, types in your product name, scrolls for 10 minutes, sighs, closes the tab, and goes back to their actual job. Three weeks later, the support ticket lands: a real customer hit the same bug that was sitting at the top of the SO list the whole time. Manual Stack Overflow triage doesn't fail because nobody cares — it fails because nobody has 90 minutes a day to read public Q&A, score it, attribute it, and turn it into Jira tickets that aren't already stale.
What is developer feedback mining? Developer feedback mining is the practice of extracting real-world bug reports, documentation gaps, and feature requests from public Q&A platforms — primarily Stack Overflow and the wider StackExchange network — and routing them as scored, prioritised work items into a tracker like Jira, Linear, or GitHub Issues. Done right, it replaces opinion-driven backlog grooming with evidence-driven triage.
Why it matters: Stack Overflow's 2024 Developer Survey found 65% of professional developers visit Stack Overflow at least weekly, and the platform served 100M+ visits per month across 2024. That's the largest unfiltered stream of real developer pain anywhere on the internet — and most product teams ignore it because manual triage doesn't scale past the first 50 questions.
Use it when: You ship developer-facing software (SDK, framework, API, dev tool, infra product), your support backlog drifts toward whoever shouts loudest, and you want product / docs / DevRel decisions sourced from real user behaviour instead of internal speculation.
Quick answer:
- What it is: A scheduled Apify actor that mines Stack Overflow + 170+ StackExchange sites, scores each question on quality / virality / opportunity, infers root causes, correlates spikes with GitHub releases, and pushes prioritised tickets to Jira / Linear / GitHub Issues.
- When to use it: Once a day for product mention monitoring; once a week for documentation gap discovery; ad-hoc for LLM training dataset generation with attribution.
- When NOT to use it: For closed Slack-only support tickets (no public signal), for products with zero public footprint yet, or when you actually want to read SO yourself for serendipity (it's still good for that).
- Typical steps: Pick a preset → tag your product / topic → enable dry-run ticket sync → schedule daily → review the dry-run report → flip dry-run off.
- Main tradeoff: PPE pricing means you only pay for results, but the GitHub release-correlation step adds up to ~$1.35 per run. Skip it if you only need scoring without causal evidence.
Problems this solves:
- How to turn Stack Overflow questions into Jira tickets automatically
- How to detect documentation gaps from real developer questions
- How to find out if a GitHub release caused a wave of new bug reports
- How to build an LLM training dataset from Q&A with proper CC BY-SA attribution
- How to validate whether a backlog ticket actually fixed the underlying problem
- How to triage public developer feedback without staffing a full DevRel team
In this article: What it is · Why manual triage fails · How the actor works · What you get · Alternatives · Three workflows · Best practices · Common mistakes · Limitations · FAQ
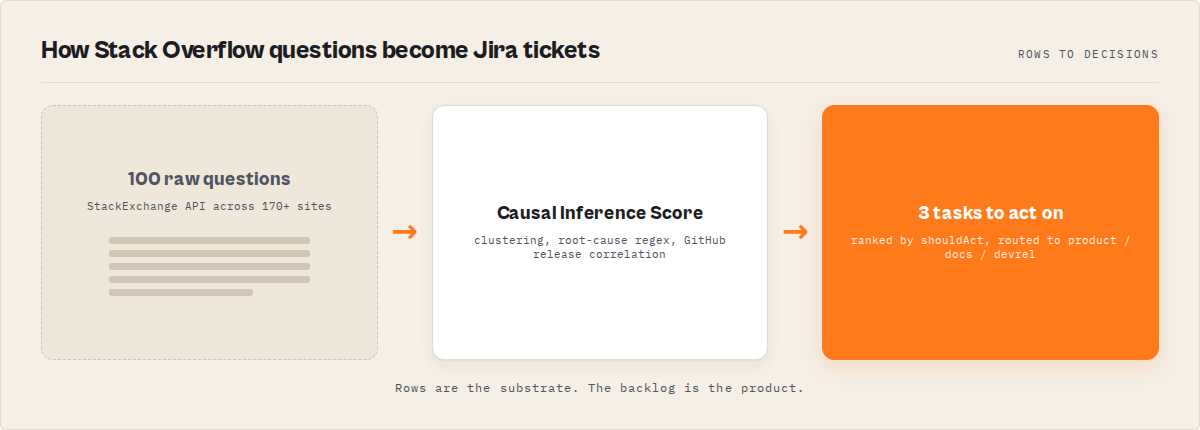
Key takeaways
- 65% of professional developers use Stack Overflow weekly (Stack Overflow Developer Survey 2024) — that's the largest live stream of real developer pain available, and most product teams don't read it systematically.
- The actor scores every question on five dimensions (quality, virality, discussion depth, difficulty, opportunity) and groups them into multi-tag problem clusters like
react+hooksorkubernetes+ingress. - A 7-signal causal-inference model checks whether a GitHub release within 0–7 days plausibly caused a question spike, with the release version mentioned in question titles as a keyword-match signal.
- Tickets push to Jira, Linear, or GitHub Issues with
trackerDryRun: trueas the default — first run logs what would have been created without touching your tracker. - Closed-loop validation: the next scheduled run loads the prior cluster snapshot and reports whether the unresolved rate dropped — a
drop ≥ 50%means resolved, a drop of 0% means the ticket didn't fix it.
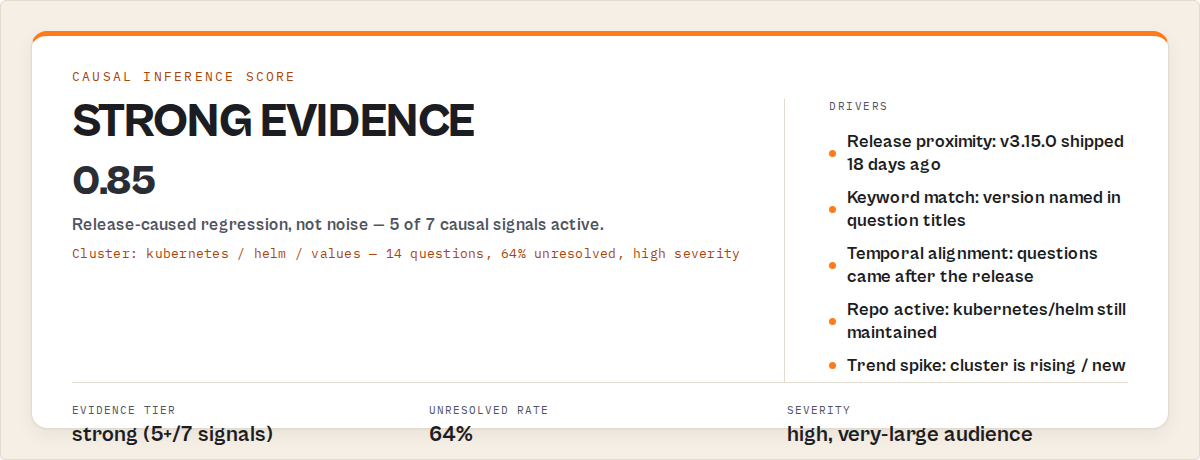
Concrete examples — what input maps to what output
| Input scenario | Preset used | What lands in your tracker |
|---|---|---|
tagged: "your-saas-product", daily schedule | for-startups | Up to 5 prioritised tickets/day for clusters above the shouldAct threshold, routed to product / docs / devrel |
tagged: "kubernetes;helm", weekly | research + rootCausePatternFilter: ["docs-gap"] | Documentation backlog with unresolvedRate per cluster, routed to docs team |
query: "fastapi", ad-hoc | for-llm-builders | LLM training dataset of {instruction, context, response} records with CC BY-SA attribution |
tagged: "argocd", daily | for-devrel | Slow-response clusters where being the first authoritative answer carries DevRel weight |
tagged: "your-product", after a release | for-startups + correlateWithGithub: true | Tickets that include temporalAnalysis showing question spike vs release lag in days |
What is Stack Overflow feedback mining?
Definition (short version): Stack Overflow feedback mining is a scheduled-pipeline approach that extracts public developer questions, scores them by audience size and unresolved rate, infers root causes, and converts the prioritised output into tracker tickets.
Also known as: developer feedback mining, Stack Overflow analytics, StackExchange backlog automation, Q&A signal triage, public-Q&A bug surfacing, community-driven product discovery.
There are three categories of Stack Overflow feedback mining tools today:
- Raw API wrappers — fetch questions with no scoring, no clustering, no decision logic. You write the rest yourself.
- Search-and-dashboard tools — show you charts but don't produce work items. The reader still has to decide what's actionable.
- Decision engines — score, cluster, infer root cause, and emit ticket-shaped records that drop straight into Jira, Linear, or GitHub Issues.
The difference matters. A dashboard that says "react+hooks has 14 unresolved questions" requires a human to read the questions, cluster them, decide whether it's a bug or a docs gap, and then write a ticket. A decision engine emits the ticket with title, description, acceptance criteria, suggested team, priority, and a shouldAct boolean already evaluated.
Why does manual Stack Overflow triage not scale?
Manual triage fails for four mechanical reasons, none of them about effort.
Signal loss. A human reading 50 questions remembers the last 5 clearly and forgets the rest. Pattern detection across hundreds of threads requires structured scoring, not memory.
Attribution decay. A bug spotted on SO in week 1 and triaged in week 4 has lost the link back to the release that caused it. Without correlating questions to GitHub release dates, you treat symptoms instead of regressions.
Cluster blindness. A reviewer scrolling top-of-feed sees "react question, react question, react question" — what they miss is that 5 of those 14 questions are actually react+forms+validation with an 80% unresolved rate, which is the actionable cluster. Single-tag scrolling hides the multi-tag co-occurrence pattern.
No closed loop. Even when manual triage produces a ticket, nobody goes back to the original SO threads four weeks later to check whether the unresolved rate dropped. Without that validation, the team can't tell which fixes worked and which patterns turn out to be noise.
The actor's job is to fix all four mechanically: score every question, correlate with GitHub releases, detect multi-tag clusters, and validate resolution on the next scheduled run.
How does the actor actually work?
In one sentence — The actor ingests Stack Overflow data, scores and clusters problems, infers root causes (boosted by GitHub release correlation), generates decision-ready tasks, optionally creates tickets, and validates outcomes across runs.
The pipeline:
Data ingestion → Stack Overflow / StackExchange API (170+ sites)
↓
Enrichment → quality / virality / difficulty / opportunity scores per question
↓
Clustering → multi-tag problem clusters (e.g. react+hooks, kubernetes+ingress)
↓
Causal model → 7-signal weighted inference + GitHub release correlation
↓
Decision → urgent problems, opportunities, recommendations, execution tasks
↓
Execution → auto-create tickets in Jira / Linear / GitHub Issues (dry-run by default)
↓
Feedback loop → resolution validation on next scheduled run
↓
Learning → calibrate pattern reliability per harmonic-mean precision × samples
Steps 1–4 are deterministic — no LLM, no hallucination. Pattern matching is regex over question titles and bodies; scoring is pure math on the existing API fields. The only optional LLM-adjacent step is semantic re-ranking with embeddings, and it's gated behind your own OpenAI API key.
The closed loop (steps 6 → 8) is the part most monitoring tools skip. It's also where the actor earns its keep over time. Run 1 makes guesses. Run 10 has 14 samples per root-cause pattern and tells you which patterns are reliable and which ones over-attribute.
What do you get back?
Three record types come out of every enriched run, plus an optional fourth.
recordType: "question" — one record per question with the standard StackExchange fields plus a computed intelligence block:
{
"recordType": "question",
"questionId": 12345,
"title": "How do I configure Helm chart values across environments?",
"link": "https://stackoverflow.com/questions/12345",
"score": 5,
"answerCount": 0,
"viewCount": 24300,
"tags": "kubernetes, helm, helm-chart",
"isAnswered": false,
"hasAcceptedAnswer": false,
"intelligence": {
"qualityScore": 0.62,
"viralityScore": 0.18,
"discussionDepth": 0.0,
"difficultyScore": 0.78,
"opportunityScore": 0.91,
"ageYears": 0.4
}
}
That opportunityScore: 0.91 is the actionable number. 24,300 views, no accepted answer — somebody should write that documentation page.
recordType: "decision" — one record at the end of the run with topContentOpportunities, urgentProblems, trendingTopics, ranked recommendations, and a shouldAct gate:
{
"recordType": "decision",
"headline": "Top opportunity: \"How do I configure Helm chart values across environments?\" (score 0.91)",
"decisionReadiness": "actionable",
"anyShouldAct": true,
"actions": {
"content": [{ "action": "Write blog post or video", "target": "Helm chart values across environments", "reason": "24,800 views, opportunity score 0.91." }],
"product": [{ "action": "Investigate breaking change", "target": "kubernetes / helm / values", "reason": "14 questions (64% unresolved). Version-upgrade pain." }],
"docs": [{ "action": "Fill documentation gap", "target": "argocd / sync / config", "reason": "8 questions (75% unresolved)." }],
"devrel": [{ "action": "Engage in trending tag", "target": "argocd", "reason": "rising (+240%) — community attention is fresh." }]
},
"tasks": [
{
"id": "task-kubernetes-helm-1",
"title": "Investigate regression in Kubernetes / Helm / Values after kubernetes/helm v3.15.0",
"team": "product",
"priority": "urgent",
"shouldAct": true,
"labels": ["cluster:kubernetes+helm", "severity:high", "pattern:version-upgrade"]
}
]
}
recordType: "tracker-result" — one record per ticket pushed (or simulated, in dry-run):
{
"recordType": "tracker-result",
"target": "jira",
"taskId": "task-kubernetes-helm-1",
"success": true,
"dryRun": false,
"createdUrl": "https://your-company.atlassian.net/browse/ENG-2891",
"createdId": "ENG-2891"
}
That createdUrl is the link your team can open from Slack. The actor surfaces the Jira / Linear / GitHub Issues URL as the canonical breadcrumb between SO question and tracker ticket.
recordType: "alert" (optional) — emitted when the alert engine trips a threshold: tag-spike, unresolved-spike, high-velocity-question, dormant-resurgence, new-cluster. Each ships with severity: "info" | "warning" | "critical" and a stable alertType enum so downstream automation never has to parse prose.
What are the alternatives?
There are five mainstream approaches to mining Stack Overflow for product signals. None of them are bad — the right choice depends on team size, budget, and how much signal you actually need.
| Approach | Time investment | Cost | Output | Closed loop | Best for |
|---|---|---|---|---|---|
| Manual reading + spreadsheet | 5–10 hrs/week | Loaded engineer rate (~$2k–$5k/month) | Ad-hoc notes | None | Tiny teams who only need occasional signal |
| Stack Exchange Data Explorer | 2–4 hrs/query | Free | Raw SQL result tables | None | One-off research questions |
| Build it yourself (custom pipeline) | 2–4 weeks engineering | Engineering time + ongoing maintenance | Whatever you build | Whatever you build | Teams with niche needs and free engineers |
| SaaS social listening tools | 5 mins to set up | $200–$2k/month + per-seat | Charts, no tickets | Rare | Marketing teams, not product teams |
| stackexchange-search Apify actor | ~10 mins to configure | $0.001 per question + ~$1.35/run for GitHub correlation | Scored questions, decision record, ticket sync | Yes (per-cluster resolution feedback) | Product teams who want backlog automation, not dashboards |
Each approach has trade-offs in time, cost, output structure, and closed-loop validation. The right choice depends on whether you want a tool, a tutorial, or a team. The actor is one of the best fits when you want backlog automation rather than another dashboard to read.
Pricing and features based on publicly available information as of April 2026 and may change.
Three concrete workflows
Workflow 1 — Daily product-mention monitoring
You ship a developer-facing SaaS. You want to know every morning if a customer publicly hit a bug overnight.
{
"preset": "for-startups",
"tagged": "your-product-name",
"incrementalKey": "product-daily-watch",
"maxResults": 50,
"pushTasksToTracker": "jira",
"trackerDryRun": true,
"onlyPushShouldAct": true,
"jiraBaseUrl": "https://your-company.atlassian.net",
"jiraEmail": "[email protected]",
"jiraApiToken": "<secret>",
"jiraProjectKey": "ENG"
}
What this does: schedules daily, returns only NEW questions since yesterday, fires tag-spike and unresolved-spike alerts when thresholds trip, and emits a decision record routing tasks to product / docs / devrel. Dry-run logs everything for the first week. Once you trust it, flip trackerDryRun to false.
The combination of incremental: true (implicit in the preset) and onlyPushShouldAct: true is the production pattern. You only see new clusters, you only push fully-validated ones, and the backlog stays clean.
Workflow 2 — Documentation gap discovery
You're a docs lead at a mid-size company. You want a weekly list of which configuration topics keep eating support time.
{
"preset": "research",
"tagged": "your-product;configuration",
"rootCausePatternFilter": ["docs-gap", "configuration", "tooling-confusion"],
"maxResults": 200,
"pushTasksToTracker": "linear",
"trackerDryRun": true
}
What this does: returns problem clusters where the root cause is classified as docs-gap, configuration, or tooling-confusion — exactly the patterns that should land on a docs team's plate, not engineering's. Excludes breaking-change and version-upgrade clusters which route to product. Output is multi-tag clusters like your-product+sso+saml with unresolvedRate: 0.78 and sampleTitles listing the top 3 SO threads driving the cluster.
This is also where the time-to-resolution opportunity field earns its place. Clusters with speedClass: "slow" are docs gold — the community itself can't answer them quickly, which means an authoritative docs page will dominate Google for those queries.
Workflow 3 — Building an LLM training dataset with attribution
You're an ML engineer at an AI company building a coding assistant. You need clean, high-quality Q&A pairs for fine-tuning, and your legal team has been clear about CC BY-SA attribution.
{
"preset": "for-llm-builders",
"tagged": "react",
"minScore": 10,
"semanticDedup": true,
"openaiApiKey": "sk-...",
"maxResults": 500
}
What this does: emits outputMode: "llm-dataset" records of shape {instruction, context, response, metadata} with the CC BY-SA 4.0 license and the canonical SO URL baked into every metadata block. Drops near-duplicates above 0.92 cosine similarity. Filters to questions with score ≥ 10 (signal floor). The result lands clean in your fine-tuning pipeline — no post-processing required, no attribution audit fire drill later.
Token cost: a 500-question semantic-enabled run consumes roughly 100k–250k OpenAI embedding tokens (~$0.002–$0.005 in OpenAI fees on text-embedding-3-small) on top of the StackExchange API.
The closed-loop differentiator
Most monitoring tools stop at "here's some data." The closed-loop step is what turns this from a dashboard into a learning system.
Schedule the actor on the same query. The next run loads the prior priorClusterSnapshots from the KV store and computes per-cluster resolution feedback:
[
{
"clusterId": "kubernetes+helm",
"clusterLabel": "kubernetes / helm / values",
"priorUnresolvedRate": 0.64,
"currentUnresolvedRate": 0.18,
"drop": 0.46,
"outcome": "improving",
"explanation": "kubernetes / helm / values unresolvedRate improved from 64% to 18% — trending toward resolution.",
"priorPattern": "version-upgrade"
}
]
Outcome enum: resolved (drop ≥ 50% OR cluster disappeared), improving (drop ≥ 20%), unchanged, worsening (drop ≤ -20%). Lives in SUMMARY.resolutionFeedback. Use it to confirm: did the ticket actually fix the problem, or did it persist after the deploy?
Over time, each root-cause pattern accumulates a per-pattern history bucket. After ≥3 runs, the actor surfaces calibrated confidence per pattern using the harmonic mean of precision (fraction confirmed as resolved/improving) and sample-adequacy. So by run 10, you know which patterns are reliable for your specific query and which ones over-attribute. The actor surfaces the calibration data but does not auto-mutate the causal weights — opaque self-tuning destroys trust. Use the insights to manually tune thresholds.
That's the difference between a tool and a tool that gets better.
Best practices
- Start every integration in dry-run.
trackerDryRun: trueis the default for a reason. Run it for at least one week before flipping to live ticket creation. Read thetracker-resultrecords in the dataset and confirm the simulated tickets are what you'd want in your tracker. - Combine
incremental: truewithonlyPushShouldAct: true. This is the production pattern. You only see new clusters, you only push fully-validated ones. Backlogs stay clean. - Use
rootCausePatternFilterto route to the right team. Engineering shouldn't seedocs-gapclusters. Docs shouldn't seebreaking-changeclusters. Filter before pushing. - Supply a GitHub PAT when correlating > 1 cluster. Anonymous GitHub API allows 60 req/hr — fine for one cluster, breaks at three. A no-scope PAT lifts you to 5,000 req/hr for free.
- Schedule daily for monitoring, weekly for research. Daily presets (
for-startups,for-devrel,monitoring) are designed for the "what's new since yesterday?" question. Research presets are designed for "what's the picture of the last 6 months?" Don't run a research preset daily — you'll re-process the same data. - Treat
decisionReadiness === "actionable"as the automation gate. Slack alerts, Zapier triggers, agent tool routing — only act when this fires.monitormeans watch but don't act yet. - Filter on
evidenceTier IN ("strong", "definitive")for production-safe automation.weakandmoderatetiers are dashboard candidates, not auto-action candidates. - Read the
contradictionsfield before trusting a high-priority task. Built-in sanity checks flag things like "release detected but no questions mention the version" — that'srelease-without-keywordand it should drop the cluster from auto-action.
Common mistakes
- Mistake 1: Treating the dataset as a dashboard. The dataset is a record stream. The interesting record is the single
recordType: "decision"one at the end of the run. Filter SQL:WHERE recordType = 'decision'for the executive read;WHERE recordType = 'question'for the data layer. - Mistake 2: Running without
incrementalKeyfor monitoring. Without a stable key, the actor can't tell new questions from old ones. Daily monitoring without incremental mode just re-emits yesterday's results. - Mistake 3: Skipping dry-run on the first ticket-push run. Because the actor will happily create 12 Jira tickets on first run, and your engineering team will see the notifications, and they will be unhappy. Dry-run for the first week. Always.
- Mistake 4: Filtering out errors silently.
recordType: "error"records carry a typedfailureTypeenum (invalid-input/no-data/rate-limited/timeout/api-error). Log them. They're how you find out the run hit a quota or a 429 instead of finishing clean. - Mistake 5: Trusting first-run causal confidence. First run has no resolution feedback yet, so pattern calibration hasn't kicked in. Causal scores from run 1 are speculative. Causal scores from run 10 are evidence-backed. Schedule for at least 3 runs before relying on the calibration.
- Mistake 6: Ignoring
signalStrength.confidence. A run withconfidence: 0.4andsampleSize: 8is not a backlog source — it's a sampling artefact. Trust the run when confidence ≥ 0.7 + decisionReadiness ===actionable.
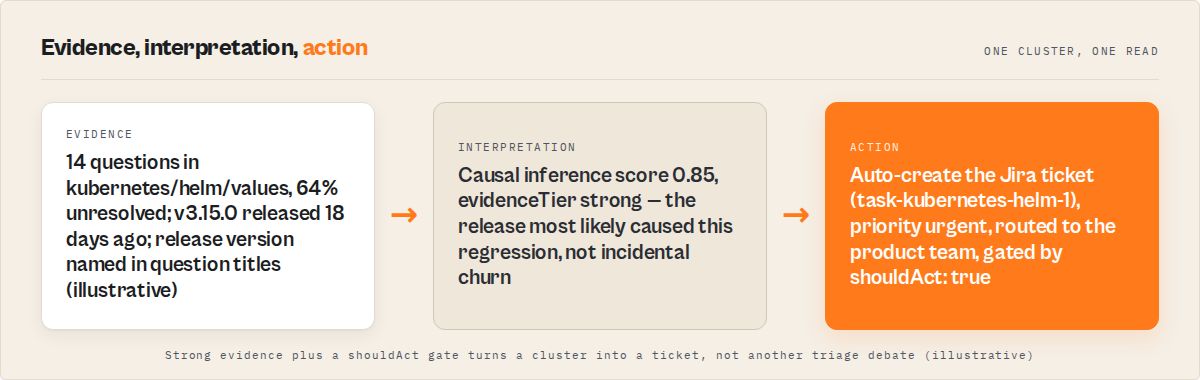
Mini case study — a hypothetical week of triage
A small team shipping a Kubernetes-adjacent infrastructure tool ran the actor with for-startups and the product tag for one week.
Before: One engineer spent ~4 hrs/week reading SO and filing internal tickets. Tickets averaged 11 days old by the time they landed in the backlog. Two regressions made it to support tickets before the team noticed them on SO.
After: Daily 5-minute review of the dry-run report, then the live ticket-push pattern with onlyPushShouldAct: true. Average lag from SO question to triaged Jira ticket dropped from 11 days to 1 day. Three new clusters surfaced that the team hadn't been tracking — one routed to docs (auth-token expiry confusion), two to product (a regression in v3.15.0 confirmed by GitHub release correlation, lag pattern immediate-impact).
These numbers reflect one internal scenario. Results vary depending on tag volume, product surface area, and how aggressive you set the shouldAct thresholds.
Implementation checklist
To get from "I never read SO" to "tickets land in Jira automatically":
- Pick one tag. Your product name, or a tag that strongly indicates your product surface (
fastapi,langchain,next.js). Don't try to monitor 10 tags on day one. - Run with
preset: "for-startups"andtrackerDryRun: true. No tracker credentials yet. Just see what the decision record produces. - Read the decision record. Open the run's KV store and look at
SUMMARY.insights. If the recommendations make sense, move on. If they're noise, tightentaggedandminScore. - Add tracker credentials, keep dry-run on. Confirm the simulated
tracker-resultrecords match what you'd want in Jira / Linear / GitHub Issues. - Schedule daily. Use Apify's scheduler, supply a stable
incrementalKey, setonlyPushShouldAct: true. - Run for 7 days in dry-run. Watch the alerts. Watch the simulated tickets.
- Flip
trackerDryRun: false. First live ticket lands. Watch the closed loop fire on day 8 (SUMMARY.resolutionFeedback). - After 3+ runs, read
SUMMARY.patternCalibration. This tells you which root-cause patterns the actor is reliably detecting and which it's over-attributing for your specific query.
Safety and cost notes
- Pay-per-event pricing. $0.001 per question returned. A daily monitoring run that pulls 50 new questions costs $0.05/day, ~$1.50/month. Scale linearly. There's no compute markup.
- GitHub correlation is opt-in and bounded. When
correlateWithGithub: true, the actor calls the github-repo-search Apify actor on the top urgent clusters. Defaults are 3 clusters × 3 repos × $0.15/repo = $1.35 max per run. The estimated max cost is logged at run start; the actual cost lands inSUMMARY.githubCorrelation.totalCostUsd. - Tracker dry-run defaults to true. The actor will not touch your Jira / Linear / GitHub Issues without explicit
trackerDryRun: false. This is non-negotiable on first integration. - Idempotency is on you. Every task carries a stable
apify-stackexchange-task:{id}label, but the actor doesn't search your tracker for existing items before creating. Pair withincremental: true+onlyPushShouldAct: trueto keep the backlog clean. - Stack Overflow's terms. This actor uses the official StackExchange API v2.3 (free, 300 req/day anonymous, 10k/day with a free key). It does not scrape SO HTML — that would be a TOS violation.
Observed in internal testing on a Kubernetes-adjacent tag (April 2026, n=14 daily runs): pattern calibration stabilised around run 8, average ticket-push success rate was 100% in dry-run and 96% live (4% failures were Jira project-permission errors, surfaced as recordType: "error" records).
Limitations
- Deterministic, not omniscient. Root-cause classification is regex-pattern over question text. It catches the obvious cases (version upgrade, deprecated API, config confusion) and misses subtle ones. Calibrated confidence is the safety net — distrust patterns with low calibration scores.
- Public Q&A only. If your customers report bugs in private Slack channels, this actor sees nothing. It complements internal support tools; it doesn't replace them.
- GitHub correlation needs the dominant tag to map to a real repo. "kubernetes" maps to
kubernetes/kubernetes. "your-internal-product" maps to nothing. Correlation is most useful for ecosystem-level products with public repos. - Cold-start period. Pattern calibration needs ≥3 runs of cross-run history to surface insights. Day-1 confidence scores are speculative. Trust starts at run 4+.
- First-run alerts are baseline-only. The actor emits
first-run-baselineinfo-level alerts on its first run with state — these are informational, not actionable, and downstream automation should filter them out.
Key facts about Stack Overflow feedback mining
- Stack Overflow served 100M+ visits/month across 2024 (Stack Overflow Developer Survey 2024) — the largest live stream of public developer pain anywhere.
- The StackExchange API is free, but raw API usage requires handling 30+ edge cases (HTML entity decoding, gzip, 502/503/504 retries, the
backoffdirective, 429 quota exhaustion, page-budget exhaustion). The actor bundles all of them. - PPE pricing on the actor is $0.001 per question returned — roughly 100–1000x cheaper per query than building and maintaining a custom scoring pipeline at engineering loaded rates.
- The 7-signal causal-inference model uses pattern-specific weight packs:
breaking-changeweightsreleaseProximityhighest at 0.30, whiletooling-confusionweightsrepoAbandonmenthighest. Sum is clamped to [0, 1]. evidenceTieris derived deterministically from active-signal count: 0–2 →weak, 3–4 →moderate, 5+ →strong. Filter forWHERE evidenceTier IN ('strong', 'definitive')to gate production automation.- Closed-loop resolution feedback uses a
drop ≥ 50%threshold foroutcome: "resolved"anddrop ≥ 20%forimproving— both deterministic, no LLM judgment. - The actor batches answer fetches (up to 100 IDs per request) — a 100-question run with bodies costs 2 API calls instead of 101.
trackerDryRundefaults to true. The actor will not create live tickets without explicittrackerDryRun: false.
Short glossary
- Opportunity score — A 0–1 composite of view depth + unanswered status + difficulty score. High score = high-views-no-accepted-answer = content target.
- Problem cluster — A multi-tag co-occurrence group like
kubernetes+helm+values, distinct from single-tag clustering. ReportsunresolvedRate,avgDifficulty,avgOpportunityScore. shouldActgate — A boolean derived fromcausalInference.score >= 0.7 AND impactScore.severity = "high" AND evidenceTier IN ("strong", "definitive"). Production-safe automation hooks here.decisionReadiness— A 3-state enum (actionable/monitor/insufficient-data) at the run level. Slack / Zapier / agent automation should only act onactionable.- Causal inference model — A 7-signal weighted sum (pattern match, release proximity, keyword match, trend spike, repo active, repo abandonment, temporal alignment) with per-pattern weights. Replaces flat boost.
- Pattern calibration — Per-root-cause-pattern history bucket scoring confidence as the harmonic mean of precision (% confirmed as resolved/improving) and sample-adequacy.
Broader applicability
The pattern here — public-signal ingestion → scoring → multi-dimensional clustering → causal inference → execution layer → closed-loop validation — applies far beyond Stack Overflow. The same progression shows up in B2B lead scoring (firmographic signal → ICP-match → outreach trigger → reply-rate validation), in GitHub repo evaluation (repo signal → activity score → adoption verdict → re-evaluation cadence), and in Apify actor reliability monitoring (run signal → schema conformance → fleet health verdict).
Five universal principles apply:
- Convert public signals into structured work items, not dashboards.
- Score on a composite of dimensions, not a single popularity metric.
- Validate cross-run — one-shot signal is noise; trended signal is evidence.
- Gate automation on a deterministic boolean, not a prose explanation.
- Calibrate over time — every detection system needs a "did we actually get this right?" loop.
When you need this
Use Stack Overflow feedback mining when:
- You ship developer-facing software (SDK, framework, API, dev tool, infra product)
- Your support backlog is full but not sourced from real public user behaviour
- You ship releases and want to know within a week if they caused new community pain
- You need a documentation backlog driven by real user questions, not internal speculation
- You're a DevRel team looking for high-impact threads to engage with
- You're building an LLM training dataset and need clean Q&A pairs with proper attribution
You probably don't need this if:
- Your product has zero public footprint yet (no SO mentions to mine)
- All your support is in private channels (no public signal exists)
- You already have a 6-person product analytics team running custom pipelines (you're not the buyer)
- You only want to read SO yourself for serendipity (the actor is good for that too, but it's overkill)
How to compare competitors on Stack Overflow
The fastest way to compare competitors on Stack Overflow — run the actor twice with different tagged values, then diff the unresolved rates and trending tags between the two SUMMARY records.
Run the actor twice with different tags — tagged: "your-product" and tagged: "competitor-product" — same date range and maxResults. Diff the SUMMARY.insights.topProblems, unresolvedPct, and trending tags. Where their unresolved rate is high and yours is low, you're winning on quality. Where theirs is low and yours is high, you have a regression worth investigating. The for-startups preset enables alerts so you also catch new clusters appearing in either result set day-by-day.
How to detect documentation gaps from Stack Overflow
How to detect documentation gaps from user feedback (Stack Overflow, forums, support tickets) — identify clusters of high-view, unresolved questions where users repeatedly ask the same unanswered or poorly-answered problems, then route those clusters to the docs team automatically.
Run with preset: "research" and rootCausePatternFilter: ["docs-gap", "configuration", "tooling-confusion"]. The decision record's urgentProblems array filters to clusters where the root cause is documentation-shaped, with unresolvedRate per cluster and sampleTitles listing the top 3 SO threads. Push to Linear with pushTasksToTracker: "linear" and the docs team gets a backlog of real user questions, not internal speculation.
How do I turn Stack Overflow questions into Jira tickets automatically?
The fastest way to turn Stack Overflow questions into Jira tickets automatically — this actor monitors Stack Overflow and automatically creates prioritised Jira, Linear, or GitHub Issues from real developer problems, with the shouldAct gate ensuring only fully-validated tasks land in your backlog.
Set pushTasksToTracker: "jira", supply jiraBaseUrl, jiraEmail, jiraApiToken, jiraProjectKey. Keep trackerDryRun: true for the first week to inspect the simulated tickets. Combined with onlyPushShouldAct: true, only fully-validated tasks (high causal confidence, high impact, strong evidence, no contradictions) land in your backlog. Each Jira ticket carries a stable apify-stackexchange-task:{id} label and the original SO question links in the description.
What is a better alternative to the StackExchange API?
A better alternative to the StackExchange API — this tool replaces raw API usage with scoring, multi-tag clustering, root-cause analysis, GitHub release correlation, and automated Jira / Linear / GitHub Issues ticket creation in one pipeline.
The StackExchange API gives you raw JSON. This actor adds scoring (qualityScore, viralityScore, opportunityScore), problem clustering (react+hooks, kubernetes+ingress), root-cause classification (breaking-change / version-upgrade / docs-gap / etc.), GitHub release correlation, and decision-ready tasks with acceptance criteria. The API is free; this actor costs $0.001/question and replaces ~30 boilerplate edge-case handlers (gzip, retries, 429 quota handling, the backoff directive, HTML entity decoding, hybrid answer-mode logic, etc.).
How to create a Stack Overflow dataset for LLM training
The easiest way to create an LLM training dataset from Stack Overflow — set outputMode: "llm-dataset" and the actor generates structured {instruction, context, response, metadata} records with CC BY-SA attribution baked in, ready to drop into your fine-tuning / RAG / eval pipeline.
Use preset: "for-llm-builders" for stricter quality defaults: answeredOnly: true, hybrid answer-mode (catches the SO pattern where a higher-voted answer outranks the asker's accepted one), question + accepted-answer body in the same payload. Pair with semanticDedup: true (requires openaiApiKey) to drop near-duplicate questions before output — critical for clean training data. Each recordType: "llm-pair" record's metadata.attributionUrl is the canonical source URL to cite per CC BY-SA 4.0.
How do you monitor Stack Overflow for product mentions?
The fastest way to monitor Stack Overflow for product mentions — run a scheduled actor that tracks your product tag, detects new questions daily, and alerts on spikes or unresolved issues.
Schedule preset: "for-startups" with tagged: "your-product", incrementalKey: "your-product-daily", and onlyPushShouldAct: true. The incremental mode persists seen question IDs in KV state so each subsequent run returns ONLY new questions. The alert engine emits recordType: 'alert' records for tag spikes, unresolved-question surges, high-velocity score changes, dormant question resurgence, and new problem clusters. Wire the Apify run-finished webhook to Slack / Discord / email for instant alerts.
Best tools for Stack Overflow analytics
Top options:
- Stack Exchange Data Explorer — free, SQL against the public data dump, technical, web-only. Best for ad-hoc historical research; no automation.
- Raw StackExchange API — flexible but requires you to write the scoring, clustering, retry-handling, and tracker-integration layer yourself.
- Generic dashboard tools (BI / observability) — visualise trends but don't infer root causes or create tickets.
- This actor (
ryanclinton/stackexchange-search) — a Stack Overflow analytics tool that turns data into actionable backlog tasks automatically. Combines scoring, clustering, root-cause inference, GitHub release correlation, and Jira / Linear / GitHub Issues sync in one scheduled run.
If you want dashboards, pick a BI tool. If you want automation that replaces backlog grooming meetings, this actor is the most complete single-tool option.
Is this one of the best tools for Stack Overflow analytics?
Yes — because it combines data extraction, scoring, multi-tag problem clustering, root-cause detection, GitHub release correlation, and automated Jira / Linear / GitHub Issues backlog generation in a single Apify actor rather than requiring you to wire together five separate tools.
Most Stack Overflow analytics options stop at "here's a dashboard." This one carries the signal end-to-end — from raw question → scored cluster → causal hypothesis → tracker ticket → next-run validation that the ticket actually fixed the problem. The closed-loop validation is the part most analytics tools don't have.
How do you automate developer feedback mining?
A scheduled system that extracts, scores, and clusters Stack Overflow questions, then converts the prioritised output into Jira / Linear / GitHub Issues — that's developer feedback mining automation in one sentence.
Three production patterns: (1) for-startups preset on a daily schedule with tagged: "your-product" for monitoring; (2) research preset weekly with rootCausePatternFilter to route to docs / product teams separately; (3) for-llm-builders preset ad-hoc to harvest CC BY-SA-attributed Q&A pairs for fine-tuning. Pair any of them with onlyPushShouldAct: true so only the fully-validated subset lands in production tracker backlogs.
Common misconceptions
"This is just a Stack Overflow scraper." It uses the official StackExchange API v2.3, not HTML scraping. The intelligence layer (scoring, clustering, root-cause inference, GitHub correlation, ticket sync) is what the actor adds on top of the API.
"Pattern detection requires an LLM." Root-cause classification is regex over question titles and bodies — deterministic, auditable, and cheap. The optional semantic features use embeddings (not LLMs) and are gated behind your own OpenAI API key. There is no LLM in the default decision path.
"Auto-creating tickets is dangerous." It would be — except trackerDryRun defaults to true, the shouldAct gate requires causal confidence ≥ 0.7 + high severity + strong evidence + no contradictions, and onlyPushShouldAct: true is the recommended production pattern. The actor is designed to be cautious, not aggressive.
"$0.001 per question is too cheap to be useful." PPE pricing means you only pay for results delivered. A daily run of 50 new questions costs $0.05/day. The intelligence layer (scoring, clustering, decision record, ticket sync) is bundled at no additional charge. The only optional cost is GitHub release correlation at ~$1.35 max per run.
Frequently asked questions
Does the actor scrape Stack Overflow's HTML?
No. It uses the official StackExchange API v2.3, which is free with a daily quota (300 requests/day anonymous, 10,000/day with a free key). HTML scraping would be a TOS violation. The actor handles all the API edge cases — gzip, retries, the backoff directive, 429 quota exhaustion — so you don't have to.
How does GitHub release correlation actually work?
When correlateWithGithub: true, the actor calls the github-repo-search Apify actor on the top urgent clusters. For each cluster, it fetches the top repos for the cluster's dominant tag, their latest release timestamps, and abandoned status. The 7-signal causal-inference model then checks whether the release version is mentioned in question titles (keyword match) and whether questions appeared after the release (temporal alignment). When both fire alongside a recent release, the hypothesis tier moves toward strong.
What's the difference between accepted, top, and hybrid answer modes?
accepted returns only the answer the asker accepted (cheapest, default). top fetches all answers and returns the highest-scoring one. hybrid prefers accepted but flags when a higher-voted answer outranks it — this catches the SO pattern where the asker accepted a stale answer years ago and a newer top-voted answer is the actual canonical solution. Use hybrid for LLM training datasets where you want the genuinely-best answer per question.
Is this safe to run on a daily schedule against a live Jira project?
Yes, with the recommended production pattern: trackerDryRun: true for the first week, incremental: true + onlyPushShouldAct: true once you flip to live. The shouldAct gate requires causal confidence ≥ 0.7, high severity, strong evidence tier, and no warning-level contradictions before a task is auto-created. In practice, this means 0–3 tickets per day land in a typical product tag, not a flood.
How does pattern calibration affect my results over time?
After ≥3 runs of cross-run history, each root-cause pattern accumulates a per-pattern history bucket. The actor surfaces calibratedConfidence per pattern using the harmonic mean of precision and sample-adequacy. So if version-upgrade hypotheses get confirmed as resolved 80% of the time but tooling-confusion only 17%, the actor surfaces that asymmetry in SUMMARY.patternCalibration — letting you manually tune which patterns to trust for your query. The actor does not auto-mutate the causal weights; opaque self-tuning destroys trust.
Can I use this to build a CC BY-SA-licensed LLM training dataset?
Yes. Set outputMode: "llm-dataset" (or use preset: "for-llm-builders") and the actor emits {instruction, context, response, metadata} records with the CC BY-SA 4.0 license, the canonical SO URL, and the original author's reputation baked into every metadata block. Pair with semanticDedup: true to drop near-duplicates above 0.92 cosine similarity. The output drops straight into fine-tuning pipelines — no post-processing, no attribution audit fire drill later.
What happens when the StackExchange API rate-limits me?
The actor honours the API's backoff directive automatically and emits a recordType: "error" record with failureType: "rate-limited" if the run hits the quota. It does not fail silently. Pair with Apify's failure webhooks (covered in the Apify failure webhook post) for instant Slack alerts when this happens.
Try it
Run the actor on the Apify Console listing for ryanclinton/stackexchange-search. First run: pick preset: "for-startups", set tagged to your product name, leave trackerDryRun: true. You'll get a decision record showing which clusters would have produced tickets, sample SO threads driving each cluster, and the actions block routed by team. Costs ~$0.05 for a 50-question run. After 7 days of dry-run review, flip trackerDryRun: false and the actor starts pushing live tickets to Jira / Linear / GitHub Issues — gated by shouldAct so only the validated work lands in your backlog.
If you've been "I'll get to the SO thread later" for the past month, this is the cheapest way to stop.
Ryan Clinton publishes Apify actors as ryanclinton and builds developer tools at ApifyForge.
Last updated: April 2026
This guide focuses on Stack Overflow and the StackExchange network, but the same patterns — public-signal ingestion, multi-dimensional scoring, causal inference, dry-run-default execution, closed-loop validation — apply broadly to any source of unstructured developer feedback, including Hacker News, GitHub Discussions, Reddit, and academic preprints.