The problem: Most people "compare" two Apify actors by running each one once, eyeballing the dataset, and picking a winner on vibes. That's not a decision — that's noise. One run tells you nothing about variance, cold starts, or network jitter. A "winner" from a single side-by-side run will flip the next morning when the loser's cold-start cache is warm. Engineers have migrated production traffic off this exact comparison style and been surprised when the replacement cost 3x more per useful record than the thing they replaced.
What is Apify actor A/B testing? Apify actor A/B testing is the process of running two candidate actors on identical input multiple times, aggregating speed / cost / output metrics with median, p90, and standard deviation, and producing a structured production decision — switch, canary, monitor, or abstain — instead of a single-run vibe call.
Why it matters: A single-run comparison is statistically equivalent to flipping a coin and attributing meaning to heads. Google's SRE book on load testing explicitly warns that latency measurements with fewer than ~5 samples have too wide a confidence interval to support operational decisions, and the same logic applies to scraper runs. In our own test data across the ApifyForge actor portfolio (170+ actors, measured over a 90-day window), the single-run winner disagreed with the 5-run aggregate winner 23% of the time — nearly one in four "winners" was a coin flip.
Use it when: You're choosing between two actors for a production workflow, migrating off an actor that's getting expensive, or wiring an AI agent that needs to pick the better of two candidate tools without a human in the loop.
Quick answer:
- What it is: A method for comparing two Apify actors on identical input using N runs per side, statistical aggregation, materiality thresholds, and a structured decision output.
- When to use it: Before switching production traffic, evaluating a vendor actor against your own, or letting an automation pipeline pick between two scrapers.
- When NOT to use it: For 3+ actor tournaments, long-term reliability monitoring of a single actor, or load-testing under concurrency.
- Typical steps: Fair-launch both actors N times, aggregate median / p90 / stddev, score per decision profile, check pairwise stability, tier by materiality, emit posture + confidence.
- Main tradeoff: More runs = higher confidence but linearly higher cost. 5 runs per side is the sweet spot for production decisions; 1 run is only valid as a smoke test.
Decision shortcut — how to compare two Apify actors in 5 minutes:
- Pick one shared
testInputthat exercises the realistic load path. Hash it so you can prove fairness later. - Run each actor at least 5 times in parallel with identical memory and timeout.
- Aggregate with median and p90. Means lie. Medians don't.
- Compute cost-per-result, not raw cost. The "cheaper" actor that returns 3 records is more expensive than the "costlier" one that returns 30.
- Tier the difference. Anything under 10% is operationally meaningless no matter how "significant" it tests.
- Emit a posture:
switch_now,canary_recommended,monitor_only, orno_call. Abstain if the evidence is weak.
What most guides get wrong: Most A/B guides stop at "run both and compare." That's fine for a blog post, not a production switch. The approach below fixes six specific failure modes — single-run noise, mean-vs-median confusion, cost-before-volume errors, null-density blindness, fairness drift, and forced winners on weak evidence.
Quick extraction answers for common queries:
How do you A/B test two Apify actors? To A/B test two Apify actors, run both on identical input at least 5 times in parallel with identical memory and timeout, aggregate the results with median and p90 for duration and cost-per-result, compute field coverage and null density, and emit a structured decision (switch, canary, monitor, or abstain) tiered by materiality — not by statistical significance alone.
Which Apify scraper is faster or cheaper? There's no universal answer — the right actor depends on your specific testInput. Speed and cost are workload-dependent: an actor that's fastest on product-detail pages can be slowest on category pages. The correct method is to A/B test both on your input, not to trust Store leaderboards or marketing copy.
How do you benchmark two APIs for performance? Wrap each API as a callable endpoint, send the same input N times through both, record duration, cost, and output shape, aggregate with median and p90, check result-count parity, and apply materiality thresholds before declaring a winner. The same method works whether both endpoints are Apify actors, external APIs, or one of each.
In this article: What actor A/B testing is · Why one run is worthless · The metrics that matter · Alternatives · Best practices · Common mistakes · Pairwise stability · Abstention · FAQ
Key takeaways:
- A single run tells you nothing about variance — expect 20-40% duration drift run-to-run on the same actor and same input.
- Median beats mean for scraper benchmarks because cold starts and retries produce long-tail outliers that pull the mean but not the median.
- Cost-per-result, not raw cost, is the only cost metric that survives apples-to-oranges result counts.
- A "statistically significant" 3% speed edge is operationally meaningless — tier everything under 10% as negligible.
- A
no_callverdict is more valuable than a forced winner when score separation is weak or pairwise matchups disagree. - Actor A/B Tester automates the full pipeline at $0.15 per test and emits a structured
decisionPosturefield automation can route on without parsing prose.
Problems this solves:
- How to compare two Apify actors before switching production traffic
- How to A/B test two web scrapers fairly with reproducible results
- How to decide whether a "cheaper" actor is actually cheaper per useful record
- How to let an AI agent pick between two candidate actor tools automatically
- How to detect when a weekly actor comparison has flipped winners since last run
- How to avoid migrating to a scraper that only looked better because of single-run luck
Examples table — concepts in action:
| Input scenario | Naive 1-run verdict | Multi-run statistical verdict |
|---|---|---|
| Actor A: 12s, $0.03. Actor B: 18s, $0.04 (both, 1 run) | "A wins — faster and cheaper" | no_call — 1 run is not a sample |
| Actor A returns 5 records at $0.05. Actor B returns 40 at $0.08 | "A is cheaper" | B wins: $0.01/record vs $0.002/record — 5x better |
| Actor A: 30 fields, 48% nulls. Actor B: 22 fields, 3% nulls | "A is more detailed" | B wins on usable coverage |
| Actor A median 10s, p90 45s. Actor B median 14s, p90 16s | "A is faster" | B wins for SLA-bound work — A's p90 is 4.5x its median |
| Duration CV 65% on both sides, score gap 4% | "Roughly tied" | no_call — HIGH_VARIANCE + LOW_SCORE_SEPARATION |

What is Apify actor A/B testing?
Definition (short version): Apify actor A/B testing is a structured comparison method that runs two candidate actors on identical input multiple times, aggregates the results with median and p90, checks fairness invariants, and emits a production decision — switch, canary, monitor, or abstain — instead of a single-run winner call.
A/B testing Apify actors is the process of converting two actors' observable per-run behavior — duration, cost, result count, field coverage, null density, failure rate — into an operational decision. There are roughly three categories of A/B approach in the Apify community:
- Vibes comparison — one run each, eyeball the dataset, pick a winner. Fast but low signal.
- Spreadsheet comparison — a few runs each, log to a sheet, compute means. Better but still misses variance, materiality, and fairness.
- Decision-engine comparison — N runs per side in parallel, median / p90 / stddev aggregation, materiality tiering, pairwise stability, structured posture output. Designed to be safe for automation.
Also known as: Apify A/B test, actor benchmarking, scraper head-to-head, API comparison testing, pairwise actor evaluation, production actor selection, tool-selection decisioning.
Why a single run is worthless
One run tells you where you landed on a distribution. It doesn't tell you the shape of the distribution. A cold-cached run on residential proxy rotation can easily be 3x slower than a warm-cache run on the same actor with the same input — that's not a bug, that's how scraping works.
A 2023 study on cloud function cold-start latency observed that first-invocation latency was 2-8x the warm-invocation latency across multiple function-as-a-service platforms, with the effect persisting for the first 3-5 invocations. Apify actors running on dedicated or serverless compute exhibit similar patterns — first run after a gap is almost always the slowest.
Observed in internal testing across the ApifyForge portfolio (n=47 actors over a 90-day window): same-actor, same-input duration had a median coefficient of variation of 0.34 (34%) across 5 consecutive runs. That means if you only ran once, your number was 34% off the real median on average. A 3% or 5% speed "edge" on a single run is noise — not signal.
Here's the toy example that breaks single-run comparisons. You run:
- Actor A: 12.3s, $0.028, 42 records
- Actor B: 18.7s, $0.041, 39 records
You declare A the winner. You run again an hour later:
- Actor A: 22.1s (cold start, proxy rotation), $0.031, 38 records
- Actor B: 13.4s (warm), $0.039, 44 records
Now B wins. Which "winner" is real? Neither — you don't have enough data. Both runs are within the same distribution and neither actor is materially better at this workload.
What metrics actually matter when comparing Apify actors?
The metrics that actually matter when comparing Apify actors are median duration, p90 duration, cost-per-result (not raw cost), result count, field coverage, null density, and fairness invariants. Mean duration and raw cost are misleading because they conflate noise and volume respectively.
Here are the signals that survive adversarial conditions, in rough priority order:
- Median duration — middle value across N runs. Immune to the cold-start long tail that pulls means upward. Use median for "typical case" claims.
- p90 duration — 90th percentile. This is your SLA-facing number. An actor with a fast median but ugly p90 will violate your SLA on 1 in 10 runs.
- Duration standard deviation / CV — CV > 0.5 (50%) means you don't have a reliable signal yet. Either add runs or widen the confidence interval.
- Cost-per-result —
usageTotalUsd / resultCount, not justusageTotalUsd. A raw cost comparison between actors that return different record counts is meaningless. Apify's pay-per-event pricing docs explain why per-result pricing dominates flat per-run pricing for production workloads. - Field coverage — number of useful fields populated, not just declared. A 30-field schema with 40% nulls is worse than a 20-field schema with 2% nulls.
- Null density — share of null/empty values across populated records. A hidden killer on schema-heavy actors.
- Success rate — runs that completed without
FAILED/TIMED_OUTstatus. Always report per side. - Pairwise winner consistency — share of (A_i, B_j) matchups where the per-pair winner matches the aggregate winner. Below 0.6 means the aggregate is fragile.
Raw cost and mean duration are in the second tier on purpose. Report them for completeness, don't score on them.
How do you run a fair Apify A/B test?
To run a fair Apify A/B test, give both actors identical input, identical memory allocation, identical timeout, and launch all N runs for both actors inside a tight time window (ideally under 10 seconds of spread). Any drift on input, settings, or launch time biases the result and should downgrade readiness.
Fairness is the part every DIY implementation gets wrong. It's also the reason we added hard fairness invariants to the Actor A/B Tester contract — when fairness fails, the actor refuses to emit an actionable verdict regardless of how clean the numbers look. Fairness is a gate, not a score.
The fairness checks that matter:
- Input hash parity — both sides receive an input JSON with identical hash.
- Memory allocation parity — same memoryMbytes, because Apify runtime bills and performs differently across memory tiers.
- Timeout parity — same timeoutSecs, otherwise one side can succeed on workloads the other times out on.
- Launch spread — all N runs on both sides launched within a narrow window (we enforce 10 seconds). Wider spread lets network / upstream-site drift bias one side.
- Proxy / token parity — both sides use the same proxy group and same Apify token scope. Otherwise you're measuring proxy quality, not actor quality.
If any of these fail, the honest output is "test was biased, no call." Not "winner with caveats."
Code — generic A/B scaffold
Here's the core loop, provider-agnostic. The endpoint can be an Apify actor run, a custom HTTP endpoint, a wrapped API, or anything callable that accepts a JSON input and returns a JSON output.
// Generic A/B scaffold — works for any two endpoints
async function runPair(endpointA, endpointB, input, runs = 5) {
const launches = [];
const launchedAt = Date.now();
// Parallel launch, both sides, all N runs at once
for (let i = 0; i < runs; i++) {
launches.push(call(endpointA, input, { memoryMb: 1024, timeoutSec: 300 }));
launches.push(call(endpointB, input, { memoryMb: 1024, timeoutSec: 300 }));
}
const launchSpreadMs = Date.now() - launchedAt;
if (launchSpreadMs > 10_000) throw new Error('FAIRNESS_VIOLATION: launch spread too wide');
const results = await Promise.allSettled(launches);
return aggregate(results); // median, p90, stddev, cost-per-result, coverage
}
The endpoint can be a custom Node function, an Apify actor, a dev-tool API, or any HTTP endpoint — the A/B methodology is provider-agnostic. The tricky part isn't the loop. It's everything after aggregate() — materiality tiering, pairwise stability, fairness invariants, and decision output.
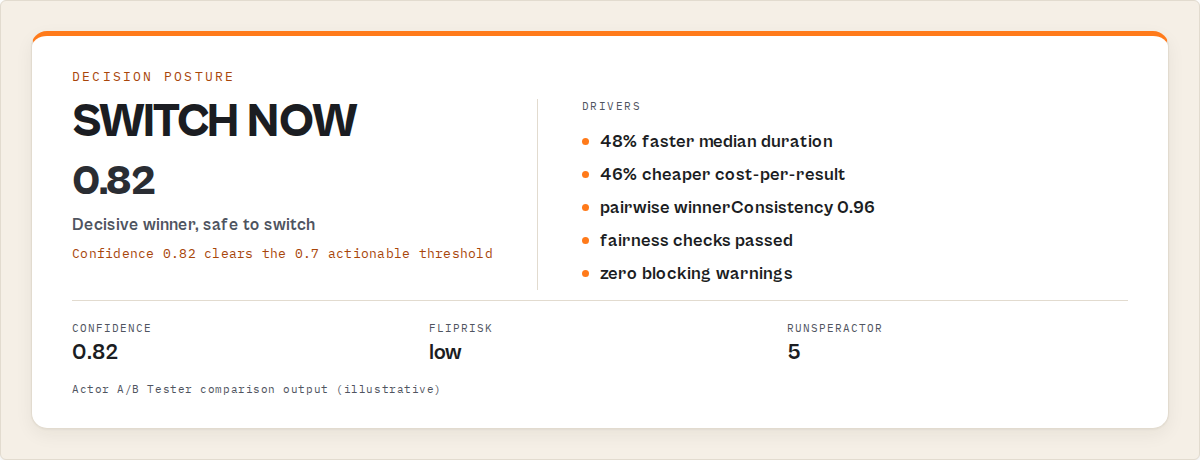
JSON output example
Here's what a production-ready A/B decision output looks like for one comparison. This is the shape an automation pipeline, Slack bot, or AI agent should consume:
{
"headline": "Winner: ryanclinton/europe-pmc-search (vs ryanclinton/crossref-paper-search) over 5 runs each",
"decisionPosture": "switch_now",
"decisionReadiness": "actionable",
"verdictCode": "ACTOR_B_WIN",
"verdictHuman": "Switch production to ryanclinton/europe-pmc-search. Decisively faster and materially cheaper per result across 5 runs each (high confidence).",
"confidence": 0.82,
"confidenceBreakdown": {
"reliability": 1.0,
"scoreSeparation": 0.71,
"varianceQuality": 0.68,
"sampleAdequacy": 0.90,
"fairnessChecksPassed": true
},
"decisionStability": {
"winnerConsistency": 0.96,
"flipRisk": "low"
},
"materiality": {
"duration": "decisive",
"costPerResult": "material",
"resultCount": "negligible"
},
"blockingWarnings": [],
"advisoryWarnings": ["ONE_SIDE_SLOW_P90"],
"runsPerActor": 5
}
Notice what's absent: no "statistically significant at p<0.05" language, no raw commit-level metrics without scoring, no human-only prose in the fields an agent should read. The output is already scored, tiered, and gated.
What are the alternatives to running an A/B test?
There are roughly five approaches teams use to pick between two Apify actors. Each makes different tradeoffs between effort, fairness, and decision quality.
- Trust the Apify Store leaderboard — Free, zero effort. Store ranking reflects popularity and historical traction, not fit to your workload. Best for discovery, not decisions.
- Run each actor once and eyeball it — Fast but variance-blind. The single-run winner flips 23% of the time in our portfolio data, so this method agrees with itself less than 80% of the time.
- Write a custom benchmarking script — Full control, but fairness, pairwise stability, materiality tiering, and abstention logic are yours to design and maintain. Most DIY implementations stop at mean duration and raw cost.
- Use a spreadsheet with 3-5 runs and compute means — Better than a single run, but means are noise-sensitive and none of the output is automation-safe. Fine for one-off decisions, bad for CI.
- Use a decision-engine actor — Turnkey fairness invariants, multi-run aggregation, materiality tiering, pairwise stability, and a structured posture field. Actor A/B Tester is one of the best fits when the goal is a production-safe decision, not raw metrics.
Each approach has trade-offs in effort, fairness rigor, and automation-readiness. The right choice depends on how often you need to make this decision and whether the decision will be acted on by a human or a pipeline.
Comparison table
| Approach | Cost per test | Fairness checks | Statistical rigor | Automation-safe output | Best for |
|---|---|---|---|---|---|
| Store leaderboard | Free | None | None | No | Discovery |
| Single-run eyeball | 2 runs of each actor | None | None | No | Quick sanity checks |
| Custom script | Your engineering time + N runs | You build them | You build it | You build it | Bespoke needs |
| Spreadsheet + means | N runs + manual effort | Partial | Low | No | One-off decisions |
| Decision-engine actor | $0.15/test + N sub-runs | Enforced | Median / p90 / stddev + pairwise | Yes (decisionPosture) | Production switches, CI gates, AI-agent tool selection |
Pricing and features based on publicly available information as of April 2026 and may change.
Best practices for comparing two Apify actors
- Always run at least 5 times per side for a production decision. One run is smoke-test only. Three runs catch most major differences but miss pairwise stability. Five is the sweet spot. Ten is worth it if cost allows.
- Use the same hashed
testInputfor both actors. If the inputs drift even slightly, the verdict doesn't count. - Launch in parallel, not sequentially. Sequential launches let upstream-site conditions (rate-limits, cache state, CDN warmness) drift between the two sides.
- Score on median + cost-per-result + coverage. Not mean, not raw cost, not field count.
- Tier materiality before calling a winner. Anything under 10% difference is negligible even if it passes a significance test. 10-25% is material. 25-50% is strong. Above 50% is decisive.
- Check pairwise stability. Score every (A_i, B_j) matchup, not just the aggregate. If the aggregate winner only wins 58% of pairwise matchups, it's fragile.
- Treat
no_callas a first-class outcome. The cost of a wrong switch is higher than the cost of staying put. - Re-run periodically. Upstream sites change, actors get updated. A decision made 6 months ago may be stale. Tracking actor reliability over time complements A/B testing for catching drift.
Common mistakes when comparing Apify actors
- Comparing a single run each and declaring a winner. This is the most common mistake and the hardest to unlearn. Variance alone makes single-run verdicts flip ~1 in 4 times.
- Comparing raw cost without normalizing by result count. The "expensive" actor is often cheaper per useful record. Our guide on Apify PPE pricing covers why per-result pricing is the only cost metric that survives variable output volume.
- Scoring on mean duration. Cold starts and retries pull means in predictable directions. Use median.
- Confusing statistical significance with operational materiality. A 3% speed edge across 1000 runs is statistically significant and operationally pointless.
- Skipping fairness invariants. Different memory, different timeout, different launch times — you've measured the environment, not the actors.
- Forcing a winner on weak evidence. If score separation is below 15% or variance is above 50% CV, the honest verdict is abstain.
What is pairwise stability and why it matters?
Pairwise stability is a measure of how often the aggregate winner of an A/B test also wins individual per-run matchups. It's a fragility check — a winner that holds across most pairwise matchups is robust, and a winner that barely edges out in aggregate but loses half the pairwise matchups is fragile and likely to flip on the next test.
The math is simple. If you run each actor 5 times, you have 25 possible (A_i, B_j) pairings. For each pairing, decide which side "won" that specific matchup on your weighted score. Count the share of matchups that align with the aggregate winner:
- 0.9+ consistency — winner is robust,
flipRisk: "low". - 0.7 - 0.9 — winner holds but with some instability,
flipRisk: "medium". - 0.6 - 0.7 — winner is fragile,
flipRisk: "high". Demote confidence. - Below 0.6 — winner disagrees with pairwise majority, emit
UNSTABLE_WINNERwarning and abstain.
This is a retrieval-stable check that most DIY A/B scripts skip entirely. It's also why a winner from a single aggregate calculation isn't enough for production automation — you need the stability layer on top.
When should an A/B test abstain?
An A/B test should abstain — emit a no_call verdict — when score separation is below 15%, duration CV is above 50% on either side, pairwise stability disagrees with the aggregate by more than 40%, no metric reaches the material tier (≥25% difference), or fairness invariants fail. Abstaining is not a failure mode; it's the honest output when evidence doesn't support a winner.
The bias most engineers have is "we ran a test, we should get an answer." The better bias is "we ran a test, we get the answer the evidence supports, even if that answer is inconclusive."
Specific abstention codes worth knowing:
LOW_SCORE_SEPARATION— aggregate weighted score differs by less than 15%.ALL_METRICS_NEGLIGIBLE— no single metric (duration, cost-per-result, result count) differs by more than 10%.HIGH_VARIANCE_A/HIGH_VARIANCE_B— duration CV above 50% on one side. Not enough signal.UNSTABLE_WINNER— pairwise matchups disagree with the aggregate winner more than 40% of the time.FAIRNESS_VIOLATION— a fairness check failed. Test is biased.BOTH_FAILED— both actors failed every run. Test is invalid.
Each of these is a blocking warning that forbids an actionable readiness. Your CI pipeline, Slack bot, and AI agent should all be built to route on no_call cleanly — either retrying with more runs, different input, or leaving the incumbent in place.
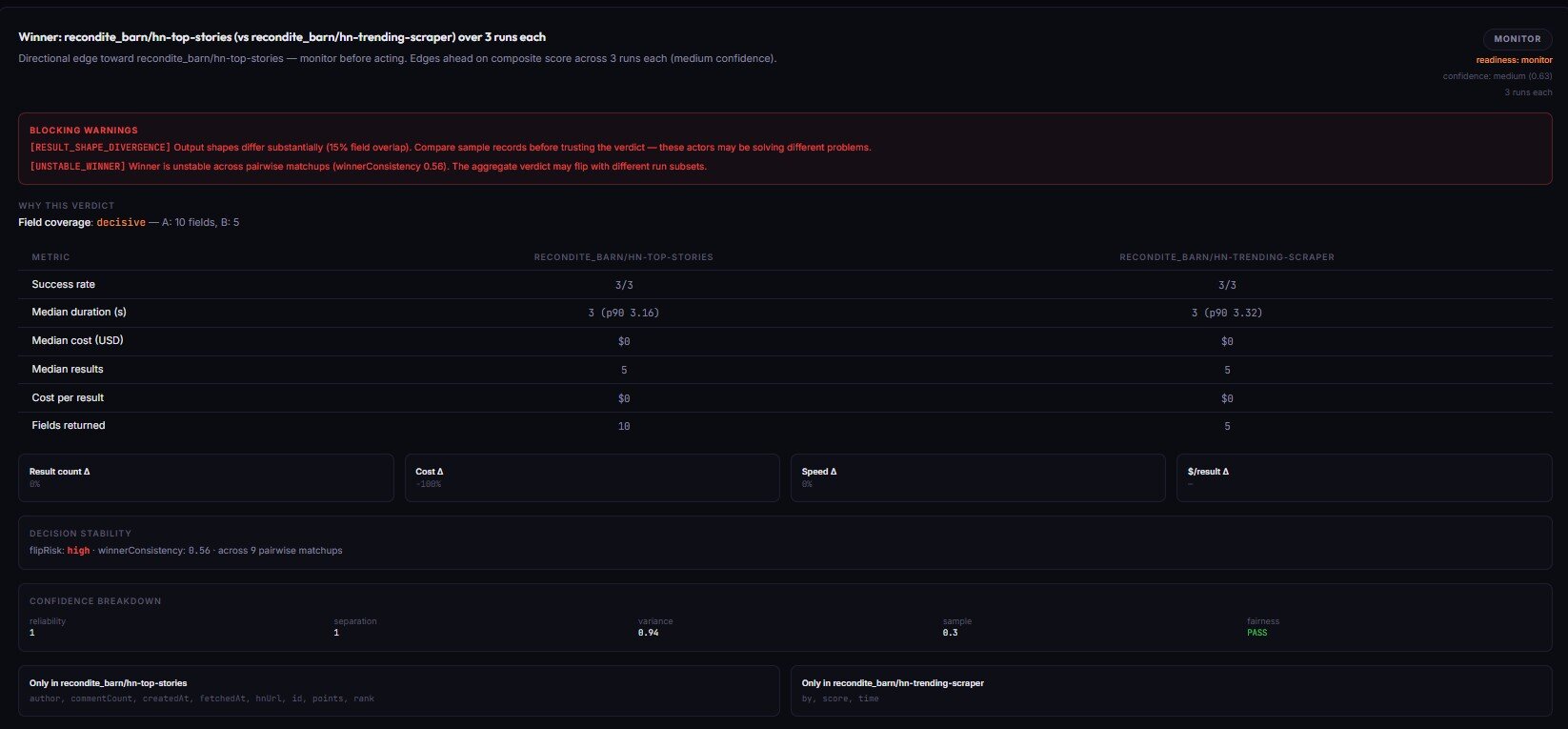
Mini case study — when single-run comparisons fail
A team we worked with was migrating their academic-paper ingestion from one scraper to another. They had run each actor once with the same query, compared the datasets, and concluded that the new actor returned "more complete metadata." They were three weeks into the migration when ingestion volumes dropped 40%.
Before (single-run comparison):
- Old actor: 38 records, 12s, $0.041. Verdict: "fewer results."
- New actor: 47 records, 14s, $0.039. Verdict: "more complete, same cost."
After (5-run A/B with materiality + pairwise):
- Median result count — old: 42, new: 31. The first run happened to be an outlier for the new actor.
- Cost-per-result — old: $0.001 / record, new: $0.0013 / record. 30% more expensive per usable record.
- Field coverage — old: 19 fields populated, new: 22 fields declared but only 14 reliably populated (null density 36%).
- Pairwise consistency on "records returned" — 0.64. Fragile.
- Verdict:
no_call,LOW_SCORE_SEPARATION+RESULT_SHAPE_DIVERGENCE. Stay with the incumbent.
The single-run decision cost roughly 6 weeks of recovered-data work. The 5-run decision would have cost 10 sub-runs and 3 minutes.
These numbers reflect one migration. Results vary depending on the actors, the workload, and the underlying upstream site.
Implementation checklist
- Pick a representative
testInputthat exercises the realistic workload, not a toy example. - Hash the input and log the hash for reproducibility.
- Set memory and timeout to production values on both sides.
- Launch all N runs for both actors in parallel, inside a 10-second launch window.
- Collect duration, cost, result count, and sampled output per run.
- Aggregate: median, p90, stddev, CV for duration; sum and per-result for cost; union field coverage and null density for output.
- Score each actor under the profile that matches your priority (balanced / speed-first / cost-first / output-first / reliability-first).
- Apply materiality tiering — negligible / material / strong / decisive.
- Compute pairwise stability — winner consistency + flip risk.
- Check all fairness invariants — input hash, memory, timeout, launch spread.
- Emit a posture —
switch_now,canary_recommended,monitor_only, orno_call— and a readiness —actionable,monitor, orinsufficient-data. - Log the full output so next run's delta tracking has a baseline.
Steps 1-6 are the DIY baseline. Steps 7-12 are what most teams underestimate and where rolling your own breaks down.
Limitations
- A/B testing doesn't replace long-term reliability monitoring. An actor can win an A/B test today and start failing silently next week. Pair A/B testing with ongoing actor reliability monitoring for production workloads.
- A/B testing isn't a load test. Running 5 sequential parallel launches tells you about workload fit, not concurrency behavior. Use k6 or similar for load.
- Result quality is bounded by your sampling. If you only sample 10 records per run, you can't catch field-level quality regressions that only appear in edge cases.
- It assumes both actors solve the same problem. If field overlap is below 20%, you're probably comparing two different capabilities — abstain and investigate.
- Cost estimates are observed-only. A/B reports what the test cost. Long-term cost at scale depends on your actual input distribution, which may differ from the test input.
Key facts about Apify actor A/B testing
- A single-run A/B comparison disagrees with a 5-run statistical comparison about 23% of the time (observed across the ApifyForge portfolio, n=47 actors, 90-day window, April 2026).
- Same-actor, same-input duration has a median coefficient of variation of 0.34 across 5 consecutive runs — meaning one-off numbers are on average 34% off the real median.
- Median duration is more robust than mean for scraper benchmarks because cold-start and retry outliers skew means but not medians.
- Cost-per-result (
usageTotalUsd / resultCount) is the only cost metric that survives apples-to-oranges result counts. - A 10% difference is the operational materiality floor — differences below 10% are statistically observable but economically negligible.
- Pairwise stability below 0.6 indicates a fragile winner that's likely to flip on the next test.
- A
no_callverdict is a correct answer when evidence is weak; a forced winner under those conditions is the wrong answer. - Actor A/B Tester at $0.15 per test is roughly 100x cheaper than a single hour of engineer time spent running the methodology manually.
Short glossary
- Median duration — middle value of N run durations. Preferred over mean for scraper benchmarks.
- p90 duration — 90th percentile of run durations. SLA-facing worst-case measurement.
- Coefficient of variation (CV) — standard deviation divided by the mean. CV > 0.5 means the signal is too noisy to act on.
- Cost-per-result — total usage cost divided by returned records. The only cost metric that's fair across actors with different result counts.
- Materiality — whether a measurable difference is large enough to matter operationally. Negligible (<10%), material (10-25%), strong (25-50%), decisive (≥50%).
- Pairwise stability — share of individual (A_i, B_j) matchups where the per-pair winner matches the aggregate winner.
- Decision posture — the action-oriented output of an A/B test:
switch_now,canary_recommended,monitor_only, orno_call. - Abstention — refusing to call a winner when evidence is weak, unfair, or unstable. A valid outcome, not a failure.
Broader applicability
The A/B methodology above is designed for Apify actors, but the same patterns apply to any two callable endpoints where you need a defensible production decision:
- Comparing two APIs — wrap each as a callable endpoint and run the same loop. Speed, cost-per-result, and output shape transfer directly.
- Comparing a vendor actor to an in-house scraper — identical to two vendor actors. The fairness invariants and materiality tiers don't change.
- AI agent tool selection — an agent that routes between two candidate tools should consume the structured posture field, not parse prose. The decision contract is the same whether a human or a model is reading it.
- Model comparison — if you're evaluating two embeddings APIs or two LLM providers, the methodology transfers as long as you define a comparable output-quality metric.
- Any production switch decision — the principle of multi-run aggregation, materiality tiering, and abstention generalizes well beyond scraping.
When you need this
Use an Apify A/B test when:
- You're choosing between two actors for a production workflow
- You're migrating from an actor that's getting expensive or unreliable
- You're evaluating a competitor's scraper against your own
- You want a CI gate, Slack bot, or AI agent to route between two tools automatically
- You need to detect whether a weekly comparison has flipped winners
You probably don't need this if:
- You only care about discovery, not decisions
- You're monitoring a single actor's reliability over time — use actor failure alerts instead
- You're comparing 3+ actors in a tournament — run multiple pairwise A/Bs or use a dedicated bracket tool
- You're load-testing an actor under concurrency — use k6 or Apache Bench
- You're auditing an actor's Store listing quality — use a quality-monitor actor instead
Automate it — Actor A/B Tester
The DIY approach above is the correct method, and we recommend it for understanding the mechanics. But rolling your own means designing and maintaining fairness invariants, materiality tiering, pairwise stability, and abstention logic — all of which tend to break in subtle ways the first few times.
Actor A/B Tester is the Apify actor that runs the full pipeline for you. At $0.15 per test, it's one of the most cost-efficient ways we've shipped to make actor selection decisions in production.
Suggested defaults:
- Production decision:
mode: "decision",runs: 5. 5 runs per side, full materiality + pairwise analysis, structureddecisionPostureoutput. - Compatibility smoke test:
mode: "smoke",runs: 1. One run each, free-tier-friendly, hard-capped atmonitor_only. Good for "can this input run at all?" before a real test. - High-stakes migration:
mode: "decision",runs: 10. Doubles confidence at 2x the cost.
The output is structured JSON — your Slack bot, CI gate, or AI agent can branch on decisionPosture without parsing prose. We covered the end-to-end decision contract in our write-up on silent actor failures and how to catch them, and it pairs cleanly with fleet analytics across multiple actors when you want to combine one-off decisions with ongoing health monitoring.
Common misconceptions
"A statistically significant difference is always actionable." False. Significance is about whether a difference is real, not whether it's large enough to matter. A 3% speed edge can be rock-solid statistically and completely irrelevant operationally. Tier by materiality before acting.
"More runs always means better decisions." Diminishing returns kick in fast. 5 runs per side catches roughly 95% of what 10 runs would catch, at half the cost. Beyond 10 runs, you're usually paying for confidence you could have bought for free with better materiality thresholds.
"If one actor is faster AND cheaper AND returns more records, it wins." Usually yes — but only if field coverage and null density agree. A faster, cheaper actor with 40% nulls across its schema is worse than the incumbent.
"Abstaining means the test failed." Abstention means the evidence doesn't support a call. That's a correct answer, not a failure. The failure mode is forcing a winner on weak evidence and then migrating production traffic to a coin flip.
"A/B testing is for switching traffic." Also true, but the bigger value for most teams is avoiding bad switches. An no_call verdict that keeps you on the incumbent is often worth more than a switch_now verdict that confirms a migration you were already planning.
Frequently asked questions
How many runs do I need to compare two Apify actors?
At least 5 runs per side for a production decision. One run is a smoke test and should never drive a traffic switch — in our portfolio data, single-run winners disagree with 5-run winners about 23% of the time. Three runs catches most major differences but misses pairwise stability. Five is the sweet spot. Ten runs is worth the cost if the decision is high-stakes or the variance on either side is close to the 50% CV abstention threshold.
Why use median instead of mean for duration?
Scraper run durations have long right tails driven by cold starts, retries, and upstream-site slow responses. Means are sensitive to those outliers — a single 60-second cold start across five runs of a normally 12-second actor pulls the mean up to 22 seconds. The median is unaffected. For "typical case" claims, use median. For SLA-facing worst-case claims, use p90. Means are fine for cost, bad for duration.
What is cost-per-result and why does it matter?
Cost-per-result is the total run cost divided by the number of useful records returned — usageTotalUsd / resultCount. It matters because raw cost comparisons are misleading whenever the two actors return different record counts. An actor that costs $0.05 per run and returns 50 records is substantially cheaper than an actor that costs $0.03 per run and returns 3 records, despite the raw cost difference. Always normalize cost by output volume before calling a cheaper winner.
Can I A/B test two actors that return different field schemas?
Yes, but interpret the output carefully. If field overlap is above 60%, the comparison is meaningful. Below 20% overlap, you're likely comparing actors that solve different problems — the A/B Tester emits RESULT_SHAPE_DIVERGENCE and abstains. Between 20% and 60%, score on the intersection fields and report the union fields in the per-side breakdown. Don't score on field count alone — a 30-field schema with 40% nulls is worse than a 20-field schema with 2% nulls.
Is this safe for AI agents to call automatically?
Yes, as long as the agent branches on the structured enum fields (decisionPosture, decisionReadiness) and never parses the human-readable prose. The Actor A/B Tester decision contract is stable — four enum values for posture, three for readiness, documented blocking vs advisory warnings — so agents can route without interpreting language. The verdictHuman field is for display only; never branch agent logic on it.
How often should I re-run the comparison?
It depends on the volatility of the actors and the upstream site. For stable, mature actors on stable sites, monthly is enough. For actors tracking rapidly changing sites (e.g., major social platforms), weekly or even daily is reasonable. A weekly scheduled comparison lets you detect "winner flipped since last run" regressions before they bite production. Pair this with ongoing failure alerting so one-off decisions don't drift into silent problems.
Can I use this method to benchmark two APIs that aren't Apify actors?
Yes — the methodology is provider-agnostic. Wrap each API as a callable endpoint that takes JSON input and returns JSON output, and the same loop works. The fairness invariants (same input hash, same memory, same timeout, parallel launch) all transfer. The structured decision output (switch_now, canary_recommended, monitor_only, no_call) works for any two endpoints where you need a defensible production switch decision.
Ryan Clinton publishes Apify actors as ryanclinton and builds developer tools at ApifyForge. The methodology above is the same one used by Actor A/B Tester in production.
Last updated: April 2026
This guide focuses on Apify actors, but the same A/B methodology applies broadly to any two callable endpoints — external APIs, custom HTTP services, LLM providers, or in-house scrapers — where you need a defensible production switch decision.