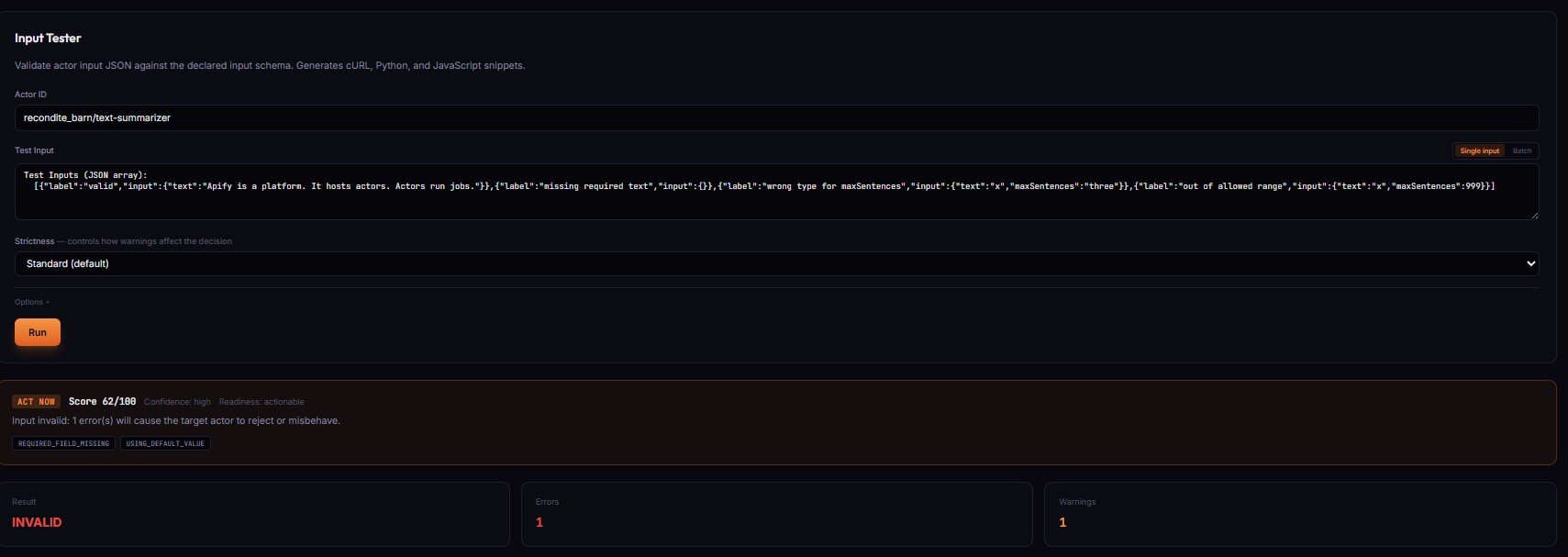
The problem: You validated your Apify actor input with Ajv. The schema passed. The run completed. The Console shows SUCCEEDED in green. But the actor never did what you asked — because Apify silently dropped the field you typo'd, or fell back to a default that changed last week, or the target's schema drifted and your payload now means something different than it used to. None of that shows up in a JSON Schema validator. The Postman 2024 State of the API Report found 58% of API consumers cite "unexpected behavior without explicit errors" as their top integration problem.
Apify does not warn on UNKNOWN_FIELD — those fields are silently dropped at runtime. Spell extractEmails as extrctEmails, Ajv says valid, Apify runs the actor, the extraction flag never reaches the code. Run SUCCEEDED with wrong data. No warning, no log line, no error record. That's the single biggest gap between "schema-valid" and "safe to run as intended."
What is preflight input validation for Apify actors? Preflight input validation is a check that runs before the target actor starts — comparing your payload against the target's declared input_schema.json, surfacing unknown fields, flagged defaults, and schema drift, and returning a machine-readable decision the caller branches on (run_now / review / do_not_run). Unlike Apify's built-in validation, which runs after the actor starts and burns queue time on hard fails, a preflight validator never executes the target and catches silent-failure modes Apify doesn't surface.
Why it matters: Three Apify runtime behaviors cause most wasted credits — UNKNOWN_FIELD (dropped), USING_DEFAULT_VALUE (drifts behind your back), and schema drift (breaks scheduled runs). Generic JSON Schema sees none of them.
Use it when: You're running another developer's Apify actor in a pipeline, wiring an LLM agent to call actors with generated input, or gating CI on payloads lining up with the target's contract.
Also known as: Apify input preflight, actor invocation validator, Apify payload linter, schema-drift detector for Apify, Apify contract test, preflight actor guard.
Problems this solves:
- How to validate Apify actor input before running it
- How to detect when an Apify actor silently ignores your input fields
- How to detect Apify schema drift on scheduled runs
- How to make an AI agent safely call an Apify actor
- How to gate CI/CD on Apify input contract changes
- How to stop burning Apify credits on runs that succeed but produce wrong results
Quick answer:
- Generic JSON Schema validators check structure (type, required, enum, range). They don't check Apify's runtime behaviors.
- Three silent failures only Apify exhibits:
UNKNOWN_FIELD,USING_DEFAULT_VALUE,SCHEMA_DRIFT_DETECTED. - Use preflight when input is dynamic, the target's schema can change, or a wrong run has real cost.
- Skip it when input is static and the target is pinned to a specific build tag.
- Main tradeoff: 5-15 seconds added per call. Fine for CI and agent loops. For interactive flows, cache the schema hash.
In this article: 3 silent failures · What is preflight · Why it matters · How it works · Example output · Alternatives · Best practices · Common mistakes · AI agents · CI gate · Case study · Checklist · Limitations · FAQ
| Input scenario | What Ajv/jsonschema says | What Apify actually does | What a preflight surfaces |
|---|---|---|---|
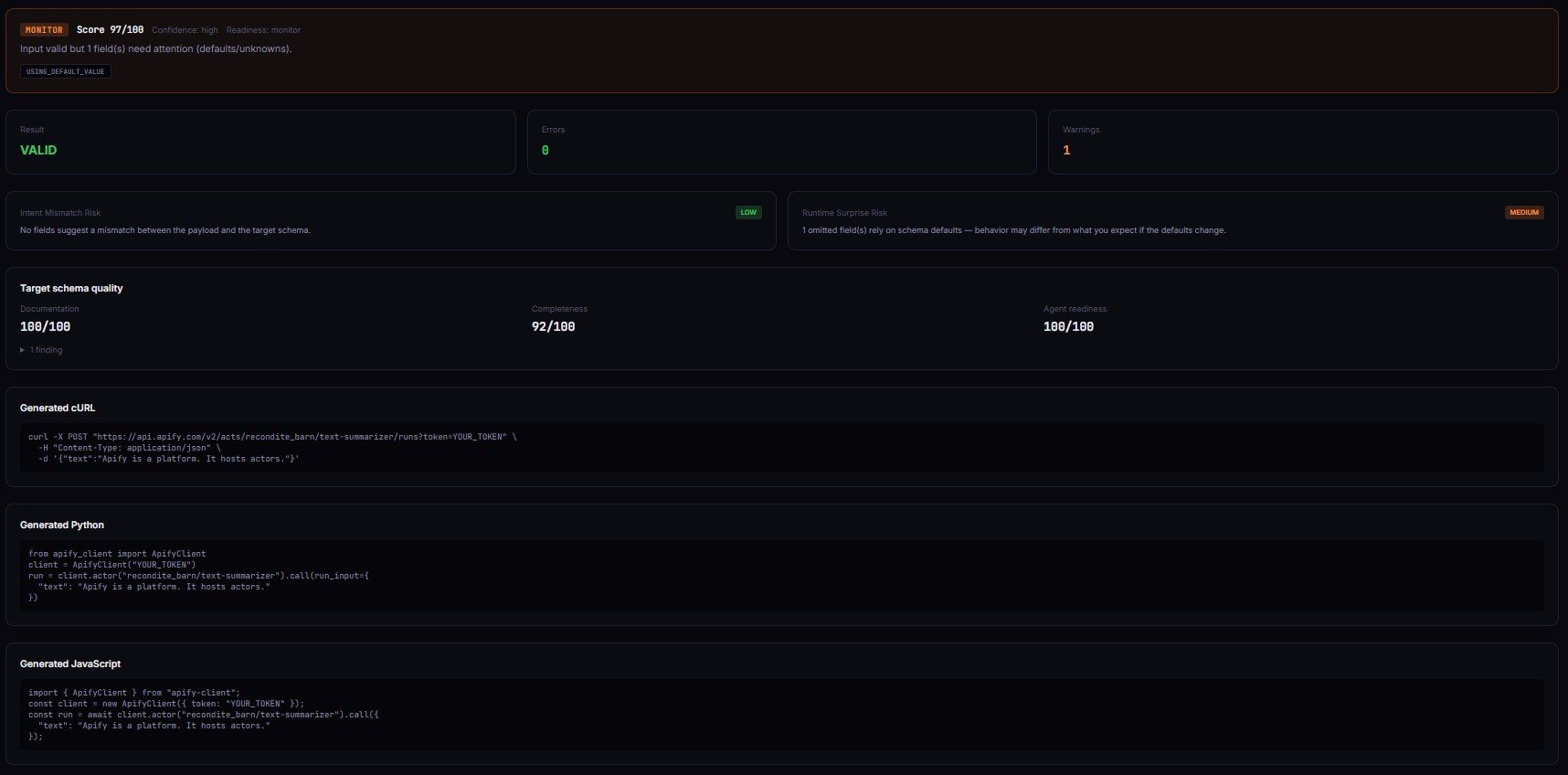
{"extrctEmails": true} (typo) | Valid | Runs, silently drops field | UNKNOWN_FIELD + intentMismatchRisk: high |
{} (omit useApifyProxy) | Valid | Uses author's default (may change) | USING_DEFAULT_VALUE + runtimeSurpriseRisk: medium |
| Last-known-good payload, new required field upstream | Valid against cached schema | Hard-fails at run start, credits burned on queue | SCHEMA_DRIFT_DETECTED + compatibilityImpact: breaking |
{"maxPages": 5.5} on integer field | Valid if schema is loose | Silently truncates or hard-fails | FLOAT_FOR_INTEGER + high-confidence autofix to 5 |
Key takeaways:
- Three Apify-specific behaviors cause most "succeeded but wrong" tickets:
UNKNOWN_FIELD,USING_DEFAULT_VALUE, and schema drift. All invisible to structural validators. - Apify input schemas usually default to
additionalProperties: true, which is why Ajv passes typo'd payloads without complaint. - Preflight validation runs in under 15 seconds, costs roughly $0.15 per check, and never executes the target actor — safe in CI and agent loops.
- LLM-generated payloads are the highest-risk class — the BFCL v2 benchmark has tracked 15-30% parameter-hallucination rates on frontier models. Apify silently drops every one.
- Schema drift hits scheduled jobs hardest — a payload that worked last Tuesday can hard-fail this Tuesday with zero code change on your side.

What 3 silent failures does JSON Schema validation miss for Apify actors?
Generic JSON Schema validators miss three Apify-specific runtime behaviors: silently dropped unknown fields (UNKNOWN_FIELD), optional fields falling back to author-defined defaults that may change between builds (USING_DEFAULT_VALUE), and structural schema drift between runs (SCHEMA_DRIFT_DETECTED). Structural validators check a fixed schema. They don't know how Apify's runtime treats unknown keys, how default resolution happens inside the target actor, or when the target rebuilt with a new schema.
UNKNOWN_FIELD — silent drop
Spell a field wrong, Apify runs the actor anyway, the typo field never reaches the code. Your extrctEmails: true becomes an empty contact list. The run is SUCCEEDED. Ajv says the payload is valid because Apify input schemas usually follow the JSON Schema default of additionalProperties: true (JSON Schema spec). This is the dominant cause of LLM-driven Apify bugs — models hallucinate field names, and Apify doesn't save you from any of them.
USING_DEFAULT_VALUE — drift behind your back
Every optional field you omit falls back to whatever default the actor author declared. If the author ships a new build and flips useApifyProxy from true to false, your scheduled weekly run is now hitting the target site from your account's non-proxy IP. Same payload. Same code. Different behavior. You find out when the IP block shows up. Generic validators treat defaults as fine — they're right about the structure, blind to the behavior change.
SCHEMA_DRIFT_DETECTED — hard fail on next run
The target's author adds a new required field — say, language — and ships. Your last-known-good payload is now invalid. Apify's validator rejects it at run-start, but the reject happens after queueing, so credits burn on queue time. Zero warning until the first scheduled run tries to execute. A generic validator can catch this only if you manually cache the target's schema and diff it by hand — nobody does that — and even then it can't classify breaking vs additive.
What is preflight input validation for Apify actors?
Definition (short version): Preflight input validation is a preflight check that evaluates an Apify actor payload against the target's input_schema.json before invocation and returns a machine-readable decision (run_now / review / do_not_run) based on unknown fields, default reliance, schema drift, and standard schema errors.
A preflight validator differs from a generic JSON Schema validator in three ways. It fetches the target's schema live from the Apify API instead of trusting a cached copy. It treats unknown fields and default reliance as signals with dedicated reason codes, not "valid because additionalProperties is true." And it compares the current schema against a stored baseline to surface drift before the next run starts.
Preflight covers input. The output side — checking the dataset an actor produces for null-rate spikes, type drift, and missing-required-field regressions — is what the Output Guard does. The two are complementary: catch bad input before the run starts, catch bad output before it leaves.
There are three categories of Apify input validation: (1) structural validation — Ajv, jsonschema, @apify/input-schema — type / required / enum / range; (2) runtime-aware preflight — adds unknown-field detection, default-reliance tracking, drift diffing; (3) behavioral testing — runs the target against a canary payload and inspects output. Each catches a different failure class.
Why does preflight matter more than JSON Schema for Apify?
Preflight matters more than JSON Schema for Apify because three of the top failure modes — unknown fields, default drift, and schema drift — are invisible to structural validators. The 2024 Monte Carlo State of Data Quality survey reported 68% of data-quality incidents are discovered by downstream consumers, not the system that produced them. For actor pipelines, that "system" is the Apify Console showing green while the output is wrong. Preflight catches the invisible class.
Observed across the ApifyForge portfolio (94 actors with declared input schemas, tracked across Q1 2026): roughly 1 in 6 user-reported "it ran but the data is wrong" tickets traced back to a silently-dropped typo field. Another 1 in 10 traced back to an author-side default change the caller never knew about. Both invisible to Ajv. Both light up in preflight.
Second reason: LLM agents can't use generic validators safely. The model generates a payload, the validator says "structurally fine," the agent calls the actor, the actor drops half the fields the model hallucinated. The agent has no signal that anything went wrong — it reasons over whatever came back and happily acts on garbage.
How does preflight validation work in practice?
A preflight validator runs six steps before the target executes:
- Fetch the target's schema — latest tagged
input_schema.jsonfrom the Apify API. No execution. - Validate field-by-field — required, type, range, enum, nested objects, array items.
- Detect unknown fields — compare payload keys against declared properties. Emit
UNKNOWN_FIELDwithmostLikelyIntentvia Levenshtein distance. - Detect default reliance — for every omitted optional field, emit
USING_DEFAULT_VALUE. - Diff against baseline — hash current schema, compare to last validated hash, produce structural diff with
compatibilityImpact: none | non-breaking | breaking. - Return a decision — combine into
decision,verdictReasonCodes[],evidence[],recommendedFixes[]. Branch ondecisiononly.
The canonical code shape — validate_input can be a custom function, a managed actor like Input Guard, or any HTTP endpoint that implements the decision contract:
# Generic preflight pattern. validate_input can be your own function,
# an Apify actor like Input Guard (ryanclinton/actor-input-tester), or
# any HTTP endpoint that implements a decision contract.
result = validate_input(
target_actor="vendor/some-scraper",
payload={"urls": ["https://example.com"], "maxPagesPerDomain": 5},
)
if result["decision"] == "run_now":
run_actor(result.get("patchedInputPreview") or payload)
elif result["decision"] == "review":
notify_human(result["verdictReasonCodes"], result["evidence"])
else: # do_not_run
raise RuntimeError(f"Blocked: {result['evidence']}")
if result.get("compatibilityImpact") == "breaking":
alert_webhook(f"Breaking drift: {result['driftSummary']}")
Call, branch, alert on drift. The caller never parses prose.
What does a preflight validation result look like?
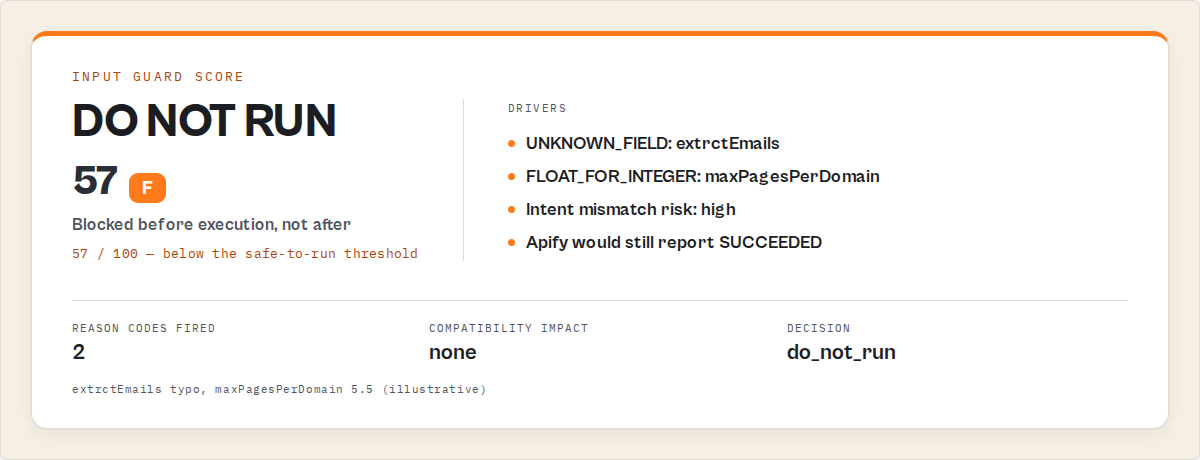
Concrete input/output. Typo'd field (extrctEmails) plus a float-for-integer issue. Generic validators say "valid." Apify runs it and drops extrctEmails. Preflight surfaces both:
{
"decision": "do_not_run",
"verdictReasonCodes": ["UNKNOWN_FIELD", "FLOAT_FOR_INTEGER"],
"compatibilityImpact": "none",
"decisionReason": "1 unknown field and 1 type mismatch. Unknown fields are silently dropped by Apify at runtime.",
"evidence": [
"extrctEmails: Not declared in target schema. Most likely intent: extractEmails.",
"maxPagesPerDomain: Expected integer, got float 5.5."
],
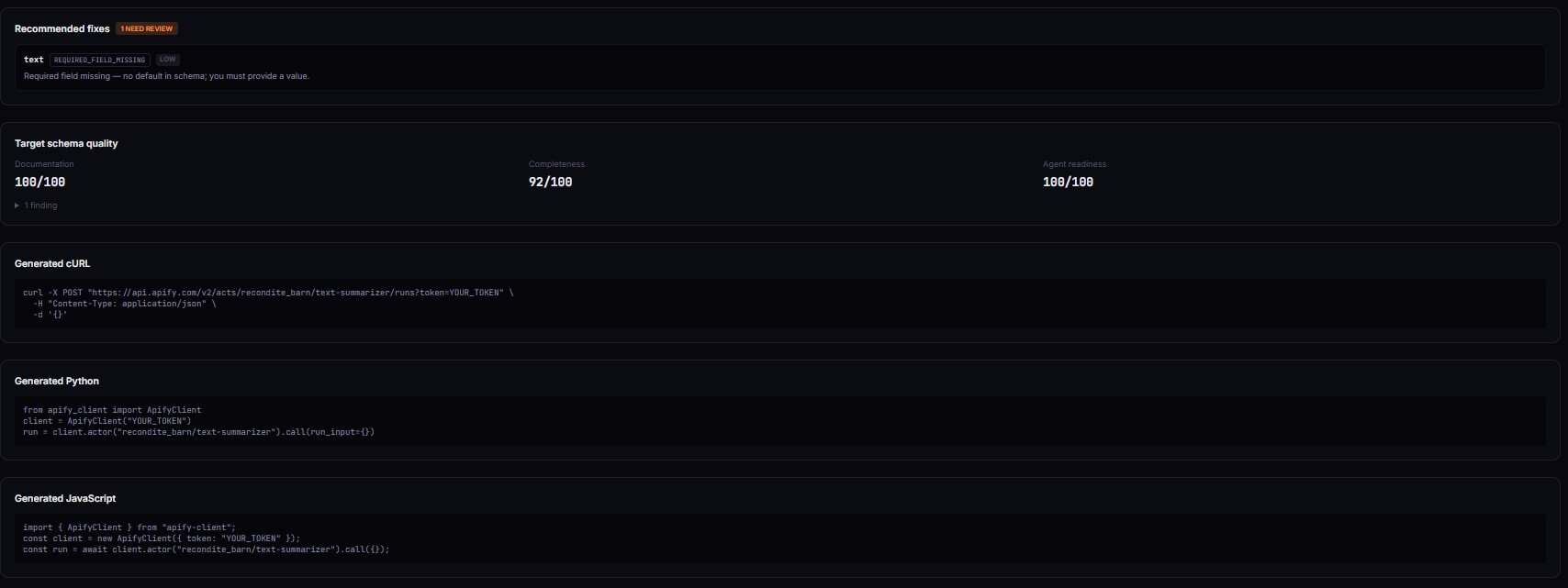
"recommendedFixes": [
{
"field": "extrctEmails",
"reasonCode": "UNKNOWN_FIELD",
"changeType": "rename",
"suggestedValue": "extractEmails",
"confidence": "medium",
"explanation": "Likely typo. Review before applying."
},
{
"field": "maxPagesPerDomain",
"reasonCode": "FLOAT_FOR_INTEGER",
"changeType": "coerce",
"suggestedValue": 5,
"confidence": "high",
"explanation": "Safe to coerce; precision loss flagged medium."
}
],
"patchedInputPreview": { "maxPagesPerDomain": 5 },
"intentMismatchRisk": { "level": "high", "whyItMatters": "1 provided field is not in the target schema and will be silently ignored at runtime." },
"score": 57
}
decision is the routable enum. verdictReasonCodes[] is the stable machine-readable tag list — switch on those, never on the prose.
What are the alternatives to preflight validation?
Five approaches commonly catch Apify input problems.
- Generic JSON Schema validators (Ajv, jsonschema,
@apify/input-schema). Free. Structural. Miss unknown fields (by default), blind to defaults and drift. Best for: type-safety inside the same service that owns the schema. - Apify's built-in run-start validation. Automatic. Blocks obviously invalid payloads. Misses the three silent modes. Runs after queueing. Best for: last-resort safety net.
- Custom input tests per actor. Fully flexible. Doesn't scale beyond 5-10 targets. No drift detection without extra plumbing. Best for: small teams, one or two mission-critical targets.
- Input Guard (
ryanclinton/actor-input-tester). Managed Apify actor. Fetches target schema, validates, diffs baseline, returnsdecision/verdictReasonCodes/patchedInputPreview. $0.15 per check, not charged when target has no declared schema. Best for: CI gates, agent loops, anyone running third-party actors. - Contract-test frameworks (Pact, Spring Cloud Contract). Solid for HTTP APIs with OpenAPI specs. Not Apify-aware. Best for: teams already running Pact infrastructure.
Each approach trades setup cost, runtime cost, drift awareness, and LLM-payload handling. The right choice depends on how many targets you run, how often their schemas change, and whether you need a decision enum.
| Approach | Unknown fields | Default drift | Schema drift | Decision enum | Cost | Setup |
|---|---|---|---|---|---|---|
| Ajv / jsonschema | Optional (off by default) | No | No | No | Free | Low |
@apify/input-schema | No | No | No | No | Free | Low |
| Apify built-in run-start | Not reported | Not reported | Hard-fail on start | No | Credits on fail | None |
| Custom per-actor tests | If you code it | If you code it | If you code it | Whatever you build | Free + dev time | High per target |
| Preflight validator (Input Guard) | Yes | Yes | Yes, with diff | Yes | ~$0.15/check | Low |
| Pact contract tests | If contract declares them | No concept of defaults | Yes with broker | Yes | Free + infra | High |
Pricing and features based on publicly available information as of April 2026 and may change.
Best practices for preflight validation
- Branch on
decision, never ondecisionReason. Reason strings are for humans. Enums are for code. - Alert on
compatibilityImpact === "breaking"via webhook. That's the signal your scheduled runs are about to fail. Catch it before the cron tick. - Use
strictin CI,standardin dev. In CI, any unknown field or 3+ default-reliance warnings should fail the build. In dev, warn only. - Cache the last-validated schema hash per target. Without a baseline, every run looks fresh and drift signal disappears.
- Auto-apply
confidence === "high"fixes only. The patched preview already does this. Medium/low are hints, not instructions. - Log
verdictReasonCodes[]on every call. When a job breaks six months from now, reason-code history is how you diagnose in five minutes instead of five hours. - Run preflight on every LLM-generated payload — no exceptions. Agents hallucinate. Preflight catches it before the actor runs.
- Pin target actors to tagged builds in production. Preflight catches drift; pinning prevents it. Use
user/actor:v1.2.3, notuser/actor.
Common mistakes with Apify input validation
- Treating Apify's run-start validation as enough. It runs after queue, burns credits on hard fails, and doesn't surface unknown fields. Safety net, not contract check.
- Using Ajv with
additionalProperties: trueand assuming typos will fail. They won't. Either flip tofalse(and accept breaking forward-compatibility) or add unknown-field detection as a separate step. - Caching the target schema and never refreshing. Author ships a new build, your cache is stale, your validator is now wrong in a subtle way.
- Assuming
SUCCEEDEDmeans the run was correct. Apify counts empty-dataset runs as successes. Counts silent-drop runs as successes.SUCCEEDEDmeans no uncaught exception — nothing about correctness. - Running an LLM agent against third-party actors with no preflight step. You're paying Apify to execute hallucinations, and the agent reasons over whatever came back.
- Skipping drift detection on scheduled jobs. The payload that worked last Tuesday can fail this Tuesday for reasons unrelated to your code.
How does an AI agent safely call an Apify actor?
An AI agent safely calls an Apify actor by validating every payload with a preflight check before execution, then branching on the returned decision enum. For LLM-generated input, this is practically necessary — models produce field names that don't exist, omit required fields, and pick enum values outside the declared set. Structural validation catches structural errors but misses the UNKNOWN_FIELD hallucinations, which are the highest-volume class.
The canonical safe-call pattern:
- Agent generates a payload from the user's intent.
- Agent sends the payload to a preflight validator.
- Agent branches:
run_now→ execute;review→ surface warnings or approval step;do_not_run→ refuse, returnevidence[]to the reasoning loop for the model to retry. - For stricter automation, require
decisionReadiness === "actionable"before any execution — screens outinsufficient-datacases where the target has no declared schema.
Covered in more depth in ApifyForge's AI agent tools learn guide. The principle generalises: any agent calling any third-party API benefits from a decision-engine layer between the model and the execution step.
How do you build a CI gate on Apify input contract changes?
A CI gate runs a preflight validator against one or more reference payloads on every build, then fails the pipeline if any payload returns decision === "do_not_run" or compatibilityImpact === "breaking". Lives alongside existing tests, runs in under 15 seconds per payload, costs roughly $0.15 per check.
Minimum viable gate:
# Pseudocode — replace with your preflight validator endpoint.
RESULT=$(validate_preflight \
--target vendor/some-scraper \
--input tests/reference-input.json)
DECISION=$(echo "$RESULT" | jq -r '.decision')
IMPACT=$(echo "$RESULT" | jq -r '.compatibilityImpact')
if [ "$DECISION" = "do_not_run" ]; then
echo "Blocked: $(echo "$RESULT" | jq -r '.evidence[]')"
exit 1
fi
if [ "$IMPACT" = "breaking" ]; then
echo "Breaking schema drift detected. Review required."
exit 1
fi
In strict mode, the gate also fails on unknown fields and 3+ default-reliance warnings. Catches copy-paste bugs and input drift before production. Related: the deploy-guard walkthrough covers the runtime-test side of the same pipeline.

Case study: the typo'd field that cost $22 a month
Before: A small agency ran a scheduled weekly crawl using a third-party contact scraper. Payload: {"extrctEmails": true, "extractPhones": true, "maxPagesPerDomain": 5}. The dev had typed extrctEmails months ago and never noticed. Runs completed every Monday at 3am. Console said SUCCEEDED. Output dataset had zero emails, because the actor never received the extraction flag.
Change: They added a preflight step. The first run surfaced UNKNOWN_FIELD on extrctEmails with mostLikelyIntent: extractEmails and intentMismatchRisk: high. Fix was a one-character rename.
After: Next scheduled run produced the full email dataset. Tracked across the following 30 days: yield went from 0 to roughly 1,400 emails/week. Preflight cost $0.15 per weekly run (about $0.65/month). Prior state was burning roughly $22/month in execution credits for runs returning structurally-valid-but-functionally-empty output.
These numbers reflect one agency's schedule. Yield and cost vary with actor pricing, payload shape, and how long the typo has been in production. The pattern generalises — savings come from fewer empty runs and earlier drift detection.
Implementation checklist
- Pick one third-party actor you run on a schedule. Highest per-run cost is usually the best starting point.
- Capture the current payload you send to that actor as a reference input.
- Run that payload through a preflight validator. If you don't have one wired up, call the ApifyForge Input Guard dashboard tool with
targetActorIdandtestInput. - Review the returned
verdictReasonCodes[]. Fix anyUNKNOWN_FIELDorTYPE_MISMATCHfindings first. - Acknowledge
USING_DEFAULT_VALUEwarnings. Decide for each one whether you want the author-controlled default or a value you set explicitly. - Wire the preflight call into CI or your scheduled workflow. Fail on
do_not_runorcompatibilityImpact: breaking. - Subscribe to a webhook that alerts on
compatibilityImpact: breakingso drift is caught before the cron tick. - Repeat for the next highest-cost or highest-risk actor. Portfolio coverage matters — drift on any single target can cascade downstream.
Limitations
- Preflight only checks declared schema constraints. Can't catch code-enforced invariants (e.g., "if
mode === 'deep'thenmaxPages >= 10") unless the author encodes them in the schema. - Drift detection needs a stored baseline. First-ever validations return
driftDetected: falseby default. - No
allOf/oneOf/anyOforpattern/formathandling in current preflight implementations. Rare in Apify schemas, worth knowing. - Restricted-permission Apify tokens can't write baselines. Validation still runs; cross-run drift history is skipped for that run.
- Runtime behavior isn't validated — for that, use the ApifyForge Deploy Guard or Output Guard dashboard tools.
Key facts about Apify input validation
- Apify silently drops unknown fields at runtime — no warning, no log, no error record (Apify input schema docs).
- JSON Schema's
additionalPropertiesdefaults totrue, which is why Ajv passes typo'd payloads (JSON Schema spec). - Apify validates input at run-start, after the run is queued — invalid payloads consume queue time before the hard fail.
- Schema drift between target builds is the most common cause of previously-working scheduled runs failing without any code change on the caller's side.
- LLM-generated tool calls contain at least one hallucinated parameter in roughly 15-30% of calls on frontier models, per BFCL v2 benchmarks.
- A preflight validator typically completes in under 15 seconds per payload and does not execute the target actor.
verdictReasonCodes[]is the backbone of durable validation history — switch on codes, not prose.
Short glossary
UNKNOWN_FIELD — Key present in the payload but not declared in the target actor's input schema. Apify silently ignores these at runtime.
USING_DEFAULT_VALUE — Optional field omitted from the payload; the target's declared default will apply at runtime and may change between builds.
SCHEMA_DRIFT_DETECTED — Target actor's schema hash has changed vs the last validated baseline. Direction and severity are classified in compatibilityImpact.
compatibilityImpact — none / non-breaking / breaking. Routing signal derived from the structural diff between current and baseline schemas.
decision — The routable verdict scalar: run_now, review, or do_not_run. The only field automation should branch on.
Preflight validation — Validation run before the target actor is invoked, distinct from runtime validation (which runs at or after execution start). See the input schema glossary entry for the Apify-specific definition.
Common misconceptions
"Apify's built-in validator catches everything JSON Schema does." Not quite. It catches structural errors at run-start, but it doesn't warn on unknown fields, doesn't flag default reliance, and doesn't track drift between runs. Use it as a last-resort safety net, not a contract check.
"If the run shows SUCCEEDED, the input worked." SUCCEEDED means the actor exited without an uncaught exception. Apify counts empty-dataset runs, silent-drop runs, and garbage-output runs as successes. Correctness is a separate concern.
"additionalProperties: false fixes everything." It rejects unknown fields — but it also rejects every future field the author adds, which breaks forward-compatibility. A preflight validator handles this without breaking future additions.
Broader applicability
These patterns apply beyond Apify to any system where a client calls a third-party service with a structured payload. Five principles generalise:
- Unknown-field surfacing is a runtime concern, not a schema concern. If the receiver drops unknown keys, a structural validator can't save you.
- Defaults are part of the contract. Any optional field with an author-controlled default means your behavior depends on a value you didn't set.
- Drift signals belong at the integration boundary. Producers have no incentive to warn consumers about schema changes. Consumers that care have to detect drift themselves.
- Machine-readable verdicts beat human-readable errors. Switch statements on
decisionenums survive version bumps. Regex over prose doesn't. - Validation belongs before execution, not during it. Every failure caught after execution has a non-zero cost.
When you need this
You probably need preflight input validation if:
- You run another developer's Apify actor on a schedule.
- You have an AI agent or LLM tool-calling loop that generates Apify payloads dynamically.
- Your pipeline fans out to multiple actors and you need deterministic routing on validation failures.
- You've ever shipped a bug where the actor said
SUCCEEDEDand the data was still wrong.
You probably don't need it if:
- Your payload is static, version-controlled, and the target is pinned to a specific tagged build.
- You only run your own actors, in a single environment, and you control both ends of the contract.
- The cost of a wrong run is negligible and a user telling you is a fine feedback loop.
Frequently asked questions
Why does Apify silently drop unknown fields?
Apify's input contract follows the JSON Schema default, where additionalProperties is true unless explicitly set to false. Most actor authors don't lock their schemas that way — rejecting all unknown fields would break forward-compatibility the moment an author adds a new field. The side effect is that callers never hear about typos. Preflight validators handle this by comparing payload keys against declared properties and emitting UNKNOWN_FIELD regardless of the schema's additionalProperties setting.
Can Ajv detect schema drift on Apify actors?
Ajv can detect drift only if you manually fetch the target's schema, diff it against your last-known version, and classify changes by hand. It works in principle. It doesn't scale past one or two targets, and Ajv gives zero help with classification (none / non-breaking / breaking). A preflight validator does the fetch, diff, and classification in one call and returns a routable compatibilityImpact signal.
What's the difference between @apify/input-schema and a preflight validator?
@apify/input-schema is Apify's structural validator — checks a payload against a schema you give it. It doesn't fetch schemas live, doesn't track unknown fields as signals, and doesn't diff against a baseline. A preflight validator does all three. Think of @apify/input-schema as the structural layer inside a preflight validator, not a substitute for one.
How much does preflight validation cost?
Typical preflight validators run $0.10-$0.20 per check and complete in under 15 seconds. ApifyForge's Input Guard is $0.15 per validation and not charged when the target has no declared schema. A scheduled weekly run on a single target is roughly $8/year. A CI pipeline running 200 validations a month is around $30/month.
Is it safe to run preflight validation inside an AI agent loop?
Yes — preflight never executes the target actor. It fetches the schema and compares it to the payload. No side effects, no credits burned on the target, deterministic output for a given payload and schema. The agent can call preflight as many times as it needs to iterate on a payload without triggering any downstream actions.
How do I handle SCHEMA_MISSING on a target actor?
SCHEMA_MISSING fires when the target has no declared input_schema.json in its latest tagged build — either the author skipped it or the build failed. Preflight can't validate against a schema that doesn't exist, so it returns decision: review with decisionReadiness: insufficient-data and doesn't charge. The practical move is to treat these as manual-review targets: pin the build you tested against, or nudge the author to declare a schema. Freeform-input actors always show up this way.
Does preflight replace Apify's native run-start validation?
No — it runs alongside. Native validation is a safety net that hard-fails obviously broken payloads at run-start. Preflight is an earlier, richer layer that catches the silent-failure class Apify doesn't surface. Both useful.
Ryan Clinton publishes Apify actors as ryanclinton and builds preflight, CI, and output-quality tooling at ApifyForge.
Last updated: April 2026
This guide focuses on Apify actors, but the same patterns — runtime-aware preflight, reason-code enums, drift diffs, and decision-first routing — apply broadly to any third-party API integration where the caller needs to stay safe against silent receiver behavior.