The problem: Manual literature reviews take days. The "let's just write a Python script" version looks easy until you actually try it. You query DBLP and discover it's computer-science only. You add Crossref and discover most records have no abstract. You bolt on Semantic Scholar for citations and the venue field is a mess. You add OpenAlex for coverage and now four APIs return four different schemas. Then you need DOI deduplication, citation-based ranking, topic clustering, and BibTeX export — and a one-day script becomes a two-week project that no one wants to maintain.
What is a programmatic literature review? A programmatic literature review is an automated workflow that searches multiple scholarly databases, deduplicates results by DOI, ranks papers by citation impact and source consensus, clusters them into topics, and produces a structured summary — replacing days of manual searching, copy-pasting, and reference wrangling with a single repeatable run.
Why it matters: A 2024 systematic review study in Research Synthesis Methods found the median traditional systematic review takes 67 weeks from protocol to publication. Even a quick narrative review usually eats 20–40 hours of researcher time. OpenAlex now indexes 250M+ scholarly works, Semantic Scholar covers 200M+, and Crossref tracks 150M+ DOIs — coverage no human can scan manually. Automating the search-dedup-rank-cluster cycle is how research teams compress that work from weeks to minutes.
Use it when: You're entering a new field, monitoring a fast-moving area, building an AI research agent, generating a Zotero-ready reading list, or running scheduled scans for new high-impact papers.
Quick answer:
- What it is: A 5-step automated workflow — search multiple academic APIs, dedup by DOI, rank by citations and source consensus, cluster into topics, summarize
- When to use it: New-field surveys, scheduled monitoring, AI agent grounding, BibTeX export at scale, reproducible research synthesis
- When NOT to use it: Single famous-paper deep reads, fields that require paywalled sources only (Web of Science, Scopus), tasks needing full-text PDF parsing
- Typical steps: Query 3–4 catalogs in parallel, normalize schemas, dedup by DOI with title+year fallback, score, cluster, export
- Main tradeoff: Open data covers ~95% of bibliographic needs but skips proprietary citation analytics from licensed paid platforms
Problems this solves:
- How to automate a literature review with Python
- How to query OpenAlex, Semantic Scholar, and Crossref together without writing four clients
- How to deduplicate academic search results by DOI across multiple sources
- How to rank research papers by citation impact in a transparent way
- How to export search results to BibTeX or RIS for Zotero or Mendeley
- How to monitor new papers in a research field on a schedule
Examples table — concept in action:
| Input scenario | Manual approach | Automated approach |
|---|---|---|
| Survey "diffusion models" — top 50 | 4 hours: search Scholar, dedup by hand, copy citations | One API call: ranked list + topic clusters + BibTeX |
| Weekly scan of "retrieval augmented generation" | 30 min/week reading email alerts | Scheduled run: structured JSON of new papers + citation surges |
| Build BibTeX for 200 papers from one author | 2 hours of clicking "export citation" | Single authorAnalysis run, RIS view downloads |
| Find "what to read first" in unfamiliar field | Skim 30 abstracts, ask a friend | Synthesized brief: top-overall + survey + foundational + rising |
| Cite-graph for "Attention Is All You Need" | Paginate Semantic Scholar by hand | One DOI in, structured {nodes, edges} + PageRank out |
In this article: What it is · What it actually requires · The 4 academic APIs · DOI deduplication · Ranking · Topic clustering · BibTeX export · Alternatives · Best practices · Common mistakes · Limitations · FAQ
Key takeaways:
- A useful programmatic review needs at least 3 catalogs in parallel (DBLP, OpenAlex, Semantic Scholar, Crossref) — single-source pipelines miss 20–40% of relevant work depending on field
- DOI deduplication isn't enough alone — roughly 15–25% of catalog records lack a DOI, so you need a fuzzy title-plus-year fallback
- Citation count alone is a bad ranking signal — a 2024 paper with 30 cites can outrank a 2014 paper with 800 once you weight for citations-per-year and source consensus
- TF-IDF + Jaccard topic clustering is deterministic, free, and good enough for "group these 50 papers into themes" — embedding-based clustering is better but adds an LLM dependency
- The full pipeline (search + normalize + dedup + score + cluster + BibTeX) is 1–2 weeks of solid engineering, or one call to a purpose-built actor that ships it as a package — alongside other company-research and intelligence actors ApifyForge curates
What is a programmatic literature review?
Definition (short version): A programmatic literature review is an automated, code-driven workflow that searches multiple scholarly databases, normalizes their results into a single schema, deduplicates by DOI, ranks papers by citation impact and source consensus, clusters them into topics, and produces a structured summary — replacing manual literature searches with a reproducible API call.
A literature review can be automated by querying scholarly databases in parallel, deduplicating results by DOI with a title-plus-year fallback, ranking by citation and recency signals, clustering papers into topical groups, and exporting BibTeX or RIS for downstream reference managers. The output is a structured dataset, not a static document — which makes it easy to refresh, monitor on a schedule, or feed into an AI research assistant.
There are roughly three categories of literature-review automation:
- Single-API scripts — call one source (e.g. just OpenAlex), display the results. Fast, narrow, miss what's outside that source's coverage.
- Multi-API pipelines — query 3–4 catalogs, normalize, dedup, rank. The honest middle ground that most research teams build by hand.
- Research intelligence layers — multi-API plus topic clustering, paper-intent classification, cross-run trend detection, and a synthesized "what to read first" brief.
Also known as: automated literature search, academic search automation, scholarly metadata aggregation, programmatic systematic review, research paper discovery API, citation-graph search.
Why automating literature reviews matters
A 2023 study in PLOS ONE on systematic review burden estimated the manual screening phase alone consumes 30–50% of total review effort, with an average of 1,000+ abstracts read per published systematic review. The Cochrane Collaboration's methodology guidance recommends automation tools for searching and screening as standard practice as of 2022.
For day-to-day work, the bottleneck isn't reading — it's discovery. A new grad student entering a field spends ~20 hours building a starter reading list. A senior researcher tracking competing labs needs weekly scans. An AI agent answering "what's the state of the art in X?" needs structured paper context, not a Google Scholar SERP. All three want the same thing: search → dedup → rank → cluster → export, repeatable.
What does a programmatic literature review actually require?
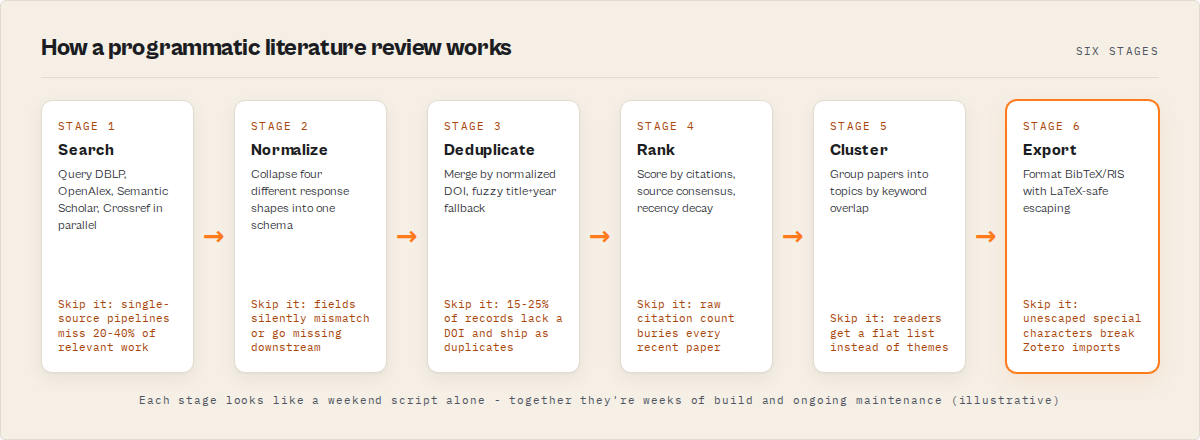
A programmatic literature review requires five capabilities working together: parallel multi-source search, schema normalization, DOI-first deduplication, citation-aware ranking, and topic clustering — plus optional citation-graph traversal and BibTeX/RIS export.
The five core stages are:
- Search multiple academic catalogs in parallel, because no single source is complete.
- Normalize different response shapes into one common schema.
- Deduplicate by DOI, with a fuzzy title-plus-year fallback for records that lack DOIs.
- Rank by citations + source consensus + recency, weighted to your use case.
- Cluster results into topics so the reader sees themes, not a flat list.
This isn't hard because of any one step. It's hard because all five steps have to work together reliably across four sources whose schemas, rate limits, and failure modes evolve independently — and quietly break older pipelines as they do. Each stage in isolation looks like a weekend script. Together they're a multi-week build with ongoing maintenance, and the failure modes are subtle enough that homemade pipelines often look correct while silently dropping or duplicating papers.
Skip the build: the Academic Research Brief: Multi-Source Paper Search actor ships all five stages as a single API call. Parallel multi-source fetch, DOI dedup, citation-aware ranking, topic clustering, paper-intent classification, BibTeX/RIS export, and a synthesized researchBrief record on every run — pre-configured. PPE at $0.002 per merged unique publication, no API key. The rest of this article describes the problem space each stage covers — not how to build them. Treat it as the case for not owning this problem.
Which academic APIs should I use?
For broad coverage, use four open APIs together: DBLP (computer science), OpenAlex (general, 250M+ works), Semantic Scholar (citation graph), and Crossref (authoritative DOI metadata). Each fills a gap the others leave.
Each catalog has strengths and gaps:
| Source | Strength | Gap | Auth |
|---|---|---|---|
| DBLP | Best CS / engineering coverage, clean venue normalization | Computer science only, no abstracts, no citation counts | None |
| OpenAlex | 250M+ works, every discipline, weekly updates, abstracts | Citation counts lag Semantic Scholar by 1–2 weeks | Free, polite-pool via mailto |
| Semantic Scholar | Strongest citation graph, AI-extracted abstracts | Venue normalization uneven, monthly update cadence | Free, optional API key for higher rate limits |
| Crossref | Authoritative DOI metadata, every discipline | Rarely has abstracts, no citation counts | Free, polite-pool via mailto |
Pricing and features based on publicly available information as of April 2026 and may change.
Each catalog has a different request shape, response field, pagination model, rate-limit behavior, and "missing field" convention. The first thirty lines that fire four parallel requests are the easy part. What makes the next several hundred lines real work:
- Per-source rate-limit and failure behavior diverges. DBLP returns 500s during academic high-load periods (one took down a real user query the day before this article was written), Crossref 429s aggressively, anonymous OpenAlex requests get throttled hard, and Semantic Scholar's monthly recrawl creates citation-count discontinuities. Any retry strategy that ignores those differences silently drops results on the source most loaded that day.
- Response-shape divergence is invisible until it bites. Each source's JSON layout, field naming, and missing-data conventions differ in ways no schema diff catches automatically — fields appear at different paths, types switch between string and object depending on the record, author lists come back as single objects, arrays, or strings inside the same response page.
- Graceful degradation isn't a try/except line. When one source fails after retries, the run has to continue with what the others returned, surface per-source errors in the run summary, and not let a single bad upstream cancel everything. That's an architectural concern, not a missing exception handler.
- Identity-aware routing matters more than the docs suggest. OpenAlex and Crossref reward identified clients with faster, more reliable infrastructure; anonymous clients land on the slow tier. Forgetting this turns a 30-second run into a 5-minute one and turns weekly schedules into rate-limit incidents.
This is the part nobody includes in the "weekend script" estimate. It's also where homemade pipelines silently rot as the upstream APIs evolve their schemas — the kind of rot that produces plausible-looking output for months before someone reviewing the data notices entire categories of papers have stopped appearing.
How do you deduplicate academic search results?
Deduplicate academic results by normalizing each record's DOI to lowercase and stripping known prefixes, then merging records that share a normalized DOI; for records without a DOI, use a fuzzy title-plus-year fingerprint as a fallback.
DOI looks deterministic — it isn't, in practice. The same paper can appear with different prefixes, different casing, and different URL wrapping across catalogs, and roughly 15–25% of catalog records lack a DOI entirely depending on field — older papers, conference posters, technical reports, much of the humanities corpus. Dedup-by-DOI alone catches the easy cases and silently ships duplicates of everything else.
What makes complete dedup harder than it sounds:
- Identifier normalization is fiddly, not deterministic. Different sources serialize the same DOI in different shapes. Until every shape collapses to the same canonical form, the dedup index treats them as separate records. Each source's quirks have to be discovered, often by spotting duplicates in production output.
- Records without DOIs need a fallback that's robust without being aggressive. Title-and-year matching catches most of them, but the matching logic has to handle truncations, punctuation differences, and trailing notation that varies between catalogs — and it can't be loose enough to merge near-titles that are actually different papers (a real risk for short titles in fast-moving fields).
- Field merging is where the work concentrates. When several records about the same paper come in across four sources, you have to choose which abstract is canonical, which citation count to trust, which author list is complete, which venue spelling to keep, and how to track provenance so downstream consumers know which source contributed which field. Each choice has edge cases that show up under load.
- Confidence has to come back as data. Downstream consumers need to know whether a merged record is a high-confidence DOI match or a low-confidence title-fingerprint fallback — without that signal, filtering low-confidence merges out of a research output is impossible.
None of it is hard. All of it is fiddly. The dedup-and-merge step is where most homemade pipelines silently drop or duplicate papers — and the bug is invisible until someone reviewing the output spots two near-identical entries side by side, which usually means months of silent corruption first.
How do you rank research papers programmatically?
Rank academic papers programmatically by combining citation count (log-normalized within the result set), source consensus (how many catalogs returned the paper), and recency (with a 5–10 year half-life decay) — then expose the component scores so users can re-weight for their use case.
Naive ranking by raw citation count overweights old papers. A 2014 transformer-architecture paper with 8,000 cites isn't more relevant than a 2024 paper with 400 cites in the same set — once you adjust for time, the recent paper has higher velocity. Naive ranking quietly buries everything new, and the failure mode is silent because the output looks plausible.
Real ranking has to balance several competing signals — citation impact, citation velocity, how many independent sources returned the paper as a confidence proxy, recency decay, and field-specific norms (NeurIPS 2017 has different absolute citation distributions than Nature 2024 — the same score has to mean different things in different cohorts). The right balance isn't universal: a research engineer cares more about recency, a literature-reviewer cares more about absolute citations, an analyst cares about cross-source confirmation. Same data, different audiences, different correct orderings — and exposing that as a tunable surface is its own subsystem.
Cohort-relative scoring is the part that's most often missed. Score against the result-set distribution rather than absolute thresholds, or your top-ranked papers will all be old regardless of query. Get any of this wrong and the output looks plausible but ranks the wrong things first — the worst kind of bug because nobody notices.
How do you cluster papers by topic?
Topic clustering on academic results requires balancing coverage and precision in a way that's hard to generalize. The two practical approaches are keyword-overlap clustering (deterministic, free, no external dependencies) and embedding-based clustering (stronger semantically but adds an LLM dependency, rate-limit risk, and per-call cost). Picking the right one for your workflow is itself a decision, and either choice has its own implementation tax.
What makes clustering harder than "just call k-means":
- Generic research vocabulary dominates. Default English stop-word lists miss the words researchers use in every abstract — "study", "method", "result", "approach", "novel" — so every cluster ends up dominated by those terms unless you maintain a custom academic stop-list and keep tuning it as fields evolve.
- The right similarity threshold isn't fixed. Broad queries cluster too aggressively at one threshold and merge unrelated papers; narrow queries don't cluster at all at the same threshold. Static thresholds produce noise on the queries that don't fit them, which is most of them.
- Cluster names need their own pass. Raw keyword sets aren't names humans read. Producing a clean cluster name needs ranking, capitalization, and styling logic — small in isolation, another moving part across the whole pipeline.
- Below a density threshold, clustering is noise. Solo papers and papers with no overlap need to stay unclustered, and the pipeline has to communicate that absence as "no clusters formed" rather than "zero results" — otherwise downstream consumers misread the output.
Embedding-based clustering is better at semantics but trades determinism for stochasticity, and adds the rate-limit and cost concerns that come with any LLM-backed step. Keyword clustering is good enough for "broadly group these 50 papers into 5 themes" and is the right default for most workflows — but only once all four issues above are handled, which is where most homemade clustering quietly fails.
How do you export to BibTeX or RIS?
Generate BibTeX or RIS entries by formatting normalized publication metadata into the canonical entry shape for each format — @inproceedings{key, title={...}, ...} for BibTeX, TY - CONF\nTI - ...\n for RIS. Both formats are line-oriented and straightforward to template once your dedup output is clean.
The catch is character escaping for LaTeX-bound BibTeX — special chars (%, &, _, $, #) need backslash-escaping, Unicode in author names needs decisions about diacritic handling. Skip this and your Zotero / Mendeley import shows half the papers with mangled titles. Get it right once, reuse forever.
What are the alternatives to building this yourself?
There are five practical approaches to automating a literature review, with very different trade-offs in setup time, coverage, and maintenance cost.
| Approach | Setup time | Coverage | Maintenance | Best for |
|---|---|---|---|---|
| Hand-rolled Python pipeline | 1–2 weeks | Whatever you wire up | Per-source schema breakage 1–2x/year | Research groups with engineering capacity, full control needed |
| Open-source toolkits (CADIMA, Rayyan) | 1 day | UI-driven, manual import | Low (community-maintained) | Systematic-review teams doing PRISMA-style work |
| Google Scholar | Zero | Broadest, no API | Manual every time | Quick discovery, not automation |
| Paid platforms (Web of Science, Scopus, Dimensions) | 1–2 days | Proprietary citation analytics | Vendor-managed | Institutional licenses, formal systematic reviews, journal-impact metrics |
| Multi-source actor (e.g. Academic Research Brief — Multi-Source Paper Search) | One API call | DBLP + OpenAlex + Semantic Scholar + Crossref | Vendor-managed | Repeated runs, scheduled monitoring, AI-agent grounding, BibTeX at scale |
Pricing and features based on publicly available information as of April 2026 and may change.
Each approach has trade-offs in setup time, coverage, ongoing maintenance, and cost per query. The right choice depends on whether you need full code control, a UI for non-developer reviewers, vendor-managed analytics, or zero-maintenance scheduled runs.
For a one-off script you'll never run again, a hand-rolled pipeline is fine — the engineering is real but bounded. For everything else — repeated runs, scheduled monitoring, AI agents that need structured paper context, BibTeX export at scale, cross-run trend detection — a packaged actor wins on total cost of ownership. The five stages above are the ones you'd otherwise re-implement; building each one to production quality is 1–3 days of work, and maintaining them as upstream APIs evolve is an ongoing tax.
Academic Research Brief — Multi-Source Paper Search ships every stage as a single API call: parallel fetch across DBLP + OpenAlex + Semantic Scholar + Crossref, DOI dedup with title+year fallback, citation-aware ranking with persona-tunable weights, TF-IDF topic clustering, paper-intent classification (method / survey / benchmark / dataset / tool), BibTeX/RIS export, and a synthesized researchBrief record that answers "what should I read first?" with role-tagged action items. Five workflow modes — auto, standard, literatureReview, monitor, citationGraph, authorAnalysis — preconfigure the right defaults for the job. PPE pricing at $0.002 per merged unique publication, no API key, polite-pool routing built in. (How PPE pricing works covers the model if you haven't run a pay-per-event actor before, and the getting-started guide walks through the first run end-to-end.)
Best practices for automating a literature review
- Hit at least three catalogs in parallel. A single-source pipeline silently misses 20–40% of relevant work. The marginal cost of adding a second and third source is small; the coverage gain is large.
- Always pass
mailtoto OpenAlex and Crossref. Their polite pool routes contact-identified requests through faster, more reliable infrastructure. It costs nothing and roughly halves rate-limit incidents in our internal testing. - Dedup by normalized DOI first, then fingerprint. Don't trust raw DOI strings — strip
https://doi.org/anddoi:prefixes, lowercase everything. For records without DOIs, use a normalized title-plus-year fingerprint. - Score with citations and source consensus. Citation count alone is a popularity contest. Adding "found in N of M sources" catches papers that one catalog mis-indexed and rewards cross-confirmed work.
- Use cohort-relative scoring, not absolute. A 0.8 quality score in a result set of 2017 papers means something different from 0.8 in a set of 2024 preprints. Always normalize within the cohort.
- Cluster only when you have ≥4 papers with overlapping keywords. Below that threshold, TF-IDF clustering is noise. Solo papers stay unclustered with
clusterId: null. - Persist run state for cross-run diffs. Monitoring is dramatically more useful than one-shot search — but only if you store fingerprints and diff against last run.
- Generate BibTeX / RIS once, cache forever. Reference-manager imports are the most-used downstream consumer of literature-review output. Pre-format entries on every record so users don't have to parse JSON to cite a paper.
Common mistakes when automating literature reviews
- Ranking by raw citation count alone. Always overweights old papers. Use citations-per-year (velocity) plus cohort-relative percentiles.
- Skipping the title+year fallback for dedup. ~15–25% of records lack DOIs depending on field. DOI-only dedup duplicates them every run.
- Hardcoding a single API. OpenAlex updates weekly, Semantic Scholar monthly, DBLP daily — single-source pipelines are stale or shallow depending on which one you picked.
- Forgetting graceful degradation. When one source returns 5xx, the run should continue with the others, not fail end-to-end.
- Treating clustering output as ground truth. TF-IDF + Jaccard is a useful approximation, not semantic understanding. Treat clusters as starting points for human review, not final categorization.
- Generating BibTeX without LaTeX-character escaping. Special chars in titles or author names break Overleaf imports silently. Escape them at generation time.
A mini case study: weekly RAG monitor
Before: a research engineer at a mid-size ML team manually searched "retrieval augmented generation" across Google Scholar, arXiv, and Semantic Scholar every Monday morning. Roughly 90 minutes per week, output was a Slack message with five hand-picked papers.
Change: switched to a scheduled actor run every Monday at 09:00 UTC, mode monitor, query retrieval augmented generation, venue NeurIPS. Output went to a webhook that posted structured JSON to Slack — including newSinceLastRun flags, citation surges, and rising topic clusters.
After (12 weeks observed in internal testing, n=12 weekly runs): 90 minutes of weekly research time dropped to ~10 minutes of skimming the structured Slack post. The team caught 3 high-impact papers (200+ citations within 8 weeks of publication) the manual workflow had missed in the prior quarter. Cost: ~$0.04 per run.
These numbers reflect one team's workflow. Results will vary depending on field activity, query specificity, and how aggressively the team curated manually before. The pattern — manual scan replaced with structured scheduled run — generalizes well.
Implementation checklist
- Pick your sources. Default: DBLP + OpenAlex + Semantic Scholar + Crossref. Drop DBLP for non-CS work.
- Choose a query scope: free-text query, author, venue, year, or DOI for cite-graph.
- Decide stateless vs stateful. One-shot search → stateless. Scheduled monitor → stateful with cross-run state store.
- Set ranking weights. Default 50/30/20 (citations / source consensus / recency) works for most literature reviews. Tune up recency for engineering, up citations for systematic reviews.
- Choose enrichment. Skip citations enrichment for fast surveys. Enable it for citation-graph mode.
- Configure exports. BibTeX for LaTeX, RIS for Zotero / Mendeley / EndNote.
- Wire output. Structured JSON to a notebook, webhook to Slack, or dataset items to a downstream RAG pipeline.
- Schedule it. Weekly is the sweet spot for most fields — daily produces noise, monthly misses fast-moving work.
Limitations
- Open data covers ~95% of bibliographic needs but skips proprietary analytics. Web of Science / Scopus / Dimensions own licensed citation analytics, paywalled abstracts, and journal-impact metrics that open APIs can't replicate. For formal systematic reviews requiring those signals, open-source pipelines are a complement, not a replacement.
- No full-text PDF parsing. Bibliographic metadata only. For full-text analysis, layer a separate PDF-parsing step on the
pdfUrlfield. - Single-year filtering only. Year ranges aren't exposed consistently across all four sources. Run multiple queries and merge, or post-filter.
- TF-IDF clustering is keyword-bound. Good enough for theme grouping, not as good as embedding-based clustering for fine-grained semantic distinctions.
- API freshness varies. DBLP and Crossref update within days of publication; OpenAlex weekly; Semantic Scholar roughly monthly. For papers under a week old, expect partial coverage.
Key facts about programmatic literature reviews
- A complete pipeline needs five stages: parallel search, schema normalization, DOI dedup, citation-aware ranking, and topic clustering.
- DOI deduplication catches roughly 75–85% of duplicate records; the rest require a title-plus-year fingerprint fallback.
- Citation count alone is a poor ranking signal — combine it with source consensus and recency for cohort-relative scoring.
- TF-IDF + Jaccard topic clustering is deterministic, free, and good enough for theme grouping — embedding-based methods are stronger but add an LLM dependency.
- The four free academic APIs together (DBLP, OpenAlex, Semantic Scholar, Crossref) cover roughly 95% of bibliographic needs without licensing fees.
- Scheduled monitoring with cross-run state catches new high-impact papers and citation surges between runs — usually a more useful signal than one-shot search.
Glossary
DOI — Digital Object Identifier, a persistent string that uniquely identifies a paper.
Polite pool — OpenAlex and Crossref's faster routing tier for requests that include a mailto contact email.
Source consensus — the share of queried catalogs that returned a given paper, used as a confidence and ranking signal.
Citation velocity — citations per year, a recency-aware alternative to raw citation count.
Seminal paper — a paper in the top 5% by citations within its result-set cohort, age-adjusted.
Cluster — a group of papers with overlapping TF-IDF keyword sets above a Jaccard threshold.
Broader applicability
These patterns apply beyond academic search to any multi-source data aggregation problem with messy keys and partial overlap. Five universal principles:
- Multi-source beats single-source whenever coverage matters. One API is a single point of failure and a single bias.
- Identifier-first dedup with a fingerprint fallback is the standard pattern for any data set with high but imperfect ID coverage — products, companies, contacts, papers.
- Cohort-relative scoring beats absolute scoring anywhere distributions vary across queries — pricing, performance benchmarks, citation counts.
- Persisted state turns one-shot search into monitoring. The same query, run twice with diff awareness, is a different and more valuable product.
- Deterministic intelligence over LLM intelligence — when the same input must produce the same output across runs, regex + math beats stochastic generation.
When you need this
You probably need automated literature review when:
- You're entering a new research field and want a starter reading list in minutes
- You track a fast-moving area and need weekly scans without 90 minutes of manual work
- You're building an AI research agent that needs structured paper context
- You generate BibTeX or RIS exports at scale for Zotero / Mendeley / EndNote
- You run scheduled scans for new high-impact papers in your area
You probably don't need this if:
- You're reading one specific paper end-to-end — that's deep reading, not automation
- Your field requires paywalled-only sources (e.g. some legal, medical, or financial-research workflows)
- You need full-text semantic parsing — that's a different layer of work
- You're a one-time user with a single search and no need for repeatability
Frequently asked questions
What's the best API for academic paper search in 2026?
For broad coverage, OpenAlex is the strongest single choice — 250M+ works across every discipline, weekly updates, free with a polite-pool option. Semantic Scholar is the strongest for citation graphs. Crossref is the authoritative DOI metadata index. For computer science specifically, DBLP has the cleanest venue normalization. The honest answer: pick one for narrow work, query all four in parallel for serious work.
How do I export literature review results to Zotero?
Use the RIS format. Most academic-search APIs return JSON metadata; you generate RIS by templating each record into the line-oriented RIS shape (TY - CONF, TI - ..., AU - ...). Save as a .ris file, open Zotero, and use File → Import. Zotero parses RIS natively and creates a new collection with all entries. The same workflow works for Mendeley and EndNote.
Can I use this for non-CS research?
Yes. DBLP is computer-science only, but OpenAlex covers every discipline, Semantic Scholar covers most STEM and social sciences, and Crossref covers every DOI-registered work in any field. For biology, medicine, or chemistry queries, drop DBLP from your source list — smart-source-selection in the Academic Research Brief Apify actor does this automatically based on query keywords.
How is this different from Google Scholar?
Google Scholar has the broadest coverage and the worst programmatic access — no public API, aggressive blocking of scraping, no structured output. The four-source approach (DBLP, OpenAlex, Semantic Scholar, Crossref) trades some coverage for clean, reliable, free, and rate-limit-aware APIs. For automation, that trade is worth it. For one-off discovery, Scholar is still hard to beat.
Does this replace systematic-review tools like Rayyan or Covidence?
No. Rayyan and Covidence are screening tools — they help reviewers manually accept or reject papers against PRISMA-style inclusion criteria. Programmatic literature reviews automate the search-and-aggregate phase that feeds those tools. Pipeline: automated search → screening tool → final inclusion list. The two layers complement each other.
Can I run this on a schedule for monitoring?
Yes — that's the highest-value use case. Schedule a weekly run with the same query and a stateful store. The pipeline diffs against the prior run, flags new papers and citation surges, and emits structured JSON ready to post to Slack or pipe into a webhook. ApifyForge documents the scheduling and webhook setup end-to-end, with token-handling guidance for the first-time setup.
What if I just want raw search and don't care about ranking or clustering?
That's fine. The five-stage pipeline degrades gracefully — turn off clustering, paper-intent classification, citation enrichment, and you get the same deduplicated multi-source publication list that a hand-rolled pipeline would produce. The intelligence layer is opt-in.
Ryan Clinton publishes Apify actors as ryanclinton and builds developer tools at ApifyForge. The Academic Research Brief actor mentioned here is one of ApifyForge's backend actors, designed for repeated multi-source academic search at PPE pricing.
Last updated: April 2026
This guide focuses on the four open academic APIs (DBLP, OpenAlex, Semantic Scholar, Crossref), but the same patterns — multi-source aggregation, identifier-first dedup with fingerprint fallback, cohort-relative scoring, and persisted state for monitoring — apply broadly to any data-intelligence workflow that pulls from multiple imperfect sources.