The problem: Everyone optimizes for fresh data. Teams pay for the newest scrape, the live pull, the "captured 4 minutes ago" timestamp, and treat staleness as the enemy. So they chase freshness and ignore the thing underneath it: whether they can even tell that today's row and last month's row are the same real-world place. They can't. The IDs churned. And a fresh row you can't re-find, join, or track is just a prettier version of a dead row.
I publish actors on the Apify Store as ryanclinton, including ones that scrape live data, so I'm not here to tell you freshness is worthless. It isn't. The argument is narrower and more contrarian than that: for most durable data work, a stable identity matters more than freshness, because freshness without identity decays into noise the moment you try to use it twice.
The pillar piece, Google Maps Scraping Isn't a Data Strategy, argues a scrape is a tactic, not a foundation. This post zooms into the single sharpest reason why: the identity problem.
If your problem is already "my place records keep losing their identity between runs," that's the job the Business Data Enricher actor was built for, but read on for why stability beats freshness in the first place.
What is a stable identifier? A stable identifier is a key that points at the same real-world entity over time, across data releases and re-runs, so a record stays re-findable, joinable, and trackable. Overture Maps' GERS ID is one; a scraped Google
place_id, documented as subject to change, is not.Why it matters: Without a stable key you can't confirm two rows are the same place, so you can't dedupe, join to a CRM, or build a change history. Record linkage research treats stable identity as the precondition for all of it. Freshness gives you a good photo; stability gives you the same subject in every photo.
Use it when: You re-run a dataset, merge sources, maintain a CRM, or track openings and closures over time. Any data you'll touch more than once needs a key that survives the second touch.
Also known as: stable IDs vs fresh data · persistent identifier vs ephemeral key · identity over freshness · durable join key vs churning ID · entity resolution before enrichment · stability is a system, freshness is a snapshot.
Quick answer
- What it is: the claim that for reusable data, a persistent identity matters more than how recently the data was captured.
- When freshness wins: live reviews, current star ratings, today's opening hours, real-time signals, the territory a Google Maps scrape genuinely owns.
- When stability wins: anything you re-run, join, dedupe, resell, or track over time, which is most data work that lasts.
- The core failure mode: fresh data with churning IDs can't be re-found or joined, so it rots into duplicates and orphaned rows.
- Main tradeoff: a snapshot is fresher; a stable-ID'd record is durable. Different jobs, and most teams pick the wrong one by default.
In this article: What it is · Why stability wins · When freshness wins · Alternatives · Best practices · Mistakes · FAQ
Key takeaways
- Google's
place_idis explicitly documented as subject to change (Google Places API docs), so even a freshly scraped ID can't be trusted to re-find the same place later. - A stable identifier is the precondition for deduplication, joins, and change tracking, record linkage literature treats identity as upstream of everything else you do with data.
- Local business data decays roughly 20-30% per year, but you can only measure that decay if the same place keeps the same ID across captures.
- Overture Maps' GERS IDs stay stable across releases (Overture GERS docs), which is what lets a record built on Overture be re-found release after release.
- Freshness without identity produces duplicates, not data, merge two fresh scrapes of one city and every overlapping business doubles, because there's no stable key to collapse them on.
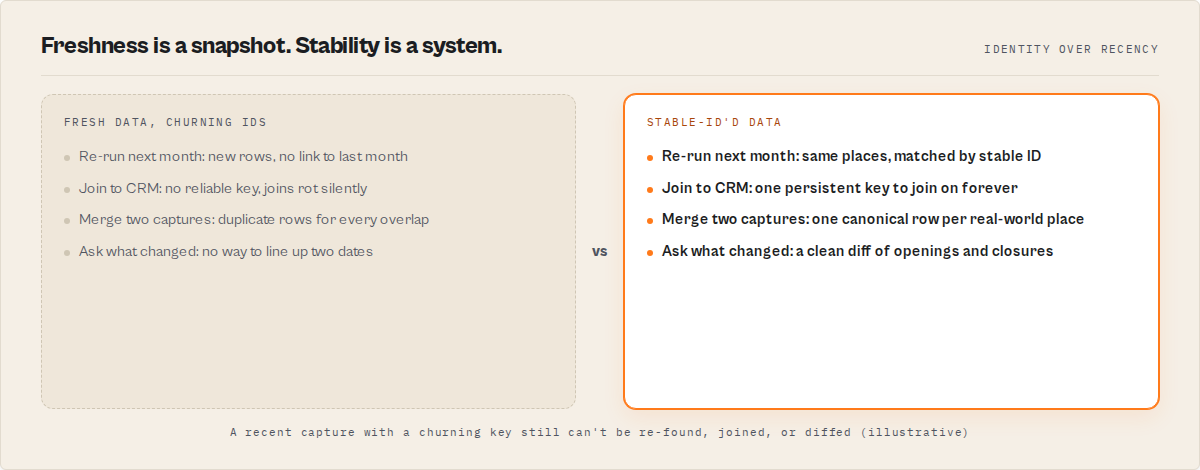
Stability vs freshness, in concrete terms
| Scenario | Fresh data with churning IDs | Stable-ID'd data |
|---|---|---|
| Re-run the same query next month | New rows, no link to last month | Same places, matched by stable ID |
| Join places to your CRM | No reliable key, joins rot silently | One persistent key to join on forever |
| Merge two captures of one city | Duplicate rows for every overlap | One canonical row per real-world place |
| Ask "which of these closed?" | No way to line up two dates | A diff of openings, closures, rebrands |
| Today's opening hours and rating | This is where fresh wins | Open data doesn't carry it, use a scrape |
What is the difference between stable IDs and fresh data?
The difference is that freshness describes when a record was captured, while a stable ID describes whether you can find that same record again. Fresh data tells you the world as of a moment. A stable identifier lets you connect that moment to every other moment. One is a property of a snapshot; the other is a property of a system.
Definition (short version): A stable ID is a persistent key that refers to the same real-world entity across time and re-runs, whereas fresh data is simply a recent capture with no guarantee its keys will mean the same thing tomorrow.
Here's the thing people miss. Freshness and stability aren't on the same axis, so "I have the freshest data" doesn't answer the question stability asks. You can have a row scraped four minutes ago whose identifier is already useless for re-finding it, and a row from last quarter that joins cleanly because its key is designed to persist. The recent one feels better. The stable one is more useful for anything you do twice.
There are broadly two kinds of identifier in play. An ephemeral key (a scraped Google place_id, a session token, a row index) is convenient now and unreliable later. A persistent identifier (Overture's GERS ID, an ISIN, a Wikidata QID) is built to survive. The whole argument of this post is that for durable data, the second kind beats fresh data carrying the first kind.
Why do stable IDs matter more than fresh data?
Stable IDs matter more because every durable operation on data, re-finding a record, joining it, deduplicating it, tracking its change, depends on identity, not recency. Freshness improves the content of a single row. Stability is what lets that row participate in a dataset at all.
Walk through what you actually do with data that matters. You re-run it. You join it. You dedupe it. You diff it across time. Now ask which of those a churning ID survives. None of them. A fresh scrape with an unstable place_id breaks on every single one, because the handle you'd use to line rows up is gone or reassigned by the next pull.
Freshness is a property of a snapshot. Stability is a property of a system.
That's the whole thesis, and it's why the contrarian framing holds. The instinct to chase freshness is optimizing the snapshot. But the value in a dataset lives in the relationships between snapshots, re-finds, joins, diffs, and those relationships are made of stable identity. Optimize the snapshot all you want; if the keys churn, you don't have a dataset, you have a stack of unrelated photographs.
Re-finding: the operation freshness can't do
To re-find a place is to ask "show me this exact business again next month." A stable ID answers it directly. A scraped place_id can't, because Google documents it as subject to change, the freshest possible scrape of an unstable key is still unstable.
Make it concrete. You scrape "Domino's Pizza, Belfast" in January, and again in March. Both rows look identical. Can you prove they are the same store, and not a closure plus a new opening at a similar address? With a stable ID, yes, both captures carry the same key, so it is provably one continuous business. With a churning place_id you genuinely cannot tell, which means you cannot trust any "still operating" or "newly opened" conclusion you draw from the pair. Re-findability is the quiet operation everything else depends on, and it is the one freshness alone can never give you.
Joining: the operation that rots silently
A join needs a key both sides agree on. Scraped IDs churn, so a CRM join on a place_id works for a few weeks, then quietly produces orphaned rows and false non-matches. The data was fresh every time. The join still rotted, because freshness never touched the join key.
Change tracking: the operation that needs two stable captures
The most valuable question in place data is "what changed?", who opened, who closed, who rebranded. Answering it requires the same identities differenced across two dates. Two fresh scrapes can't do it, because without stable keys you can't even confirm a row in January is the same business in March.
When does fresh data actually win?
Fresh data wins whenever the value is the current state itself and you don't need to connect it to past or future captures. Live star ratings, today's review count, current opening hours, "is it busy right now," real-time price, these are pure-freshness fields, and a Google Maps scrape is genuinely the right tool for them.
I want to be honest about this because the contrarian headline cuts both ways. Open ground-truth datasets like Overture Maps refresh monthly and carry no reviews, no ratings, no live hours. If your use case lives entirely on "what's this restaurant's rating and is it open right now," stability buys you nothing and a fresh scrape buys you everything. That's a real category, and it's exactly the territory a Google Maps scraper was built for.
The mistake isn't valuing freshness. The mistake is valuing freshness for a job that needs stability. A snapshot of today's hours is the right freshness call. A snapshot as the foundation for a CRM you'll re-sync for two years is a stability job dressed up as a freshness one. Match the property to the work.
| Field | Freshness-critical | Stability-critical |
|---|---|---|
| Current star rating | Yes, use a Maps scrape | No |
| Today's opening hours | Yes, use a Maps scrape | No |
| The place's persistent identity | No | Yes, needs a stable ID |
| Whether two rows are the same place | No | Yes, needs a stable ID |
| Openings and closures over time | Partly | Yes, needs stable IDs to diff |
Open datasets refresh monthly and don't carry reviews, ratings, or live hours; for those, a Maps scrape still wins. Information based on publicly available sources as of June 2026 and may change.
What does stable-ID'd output look like?
Stable-ID'd output is a canonical record where every entity carries a persistent global identifier, so the same input run twice produces the same identity and changes line up. Below is the shape of what you get back, a resolved record stamped with a GERS ID, not a scrape with extra columns.
{
"resolved": [
{
"gers_id": "08f2a7b3c1...e09",
"name": "Domino's Pizza",
"category": "pizza_restaurant",
"address": "Belfast BT9 6AA",
"matched_inputs": ["Dominos Pizza", "Domino's", "Domino's Pizza - Belfast"],
"license": "CDLA-Permissive-2.0",
"source": "overture-maps"
}
]
}
The point isn't the field names. It's that gers_id. Three messy input rows collapsed to one entity, and that entity now carries a key designed to be the same next month and next release. Re-run the list and Domino's resolves to the same gers_id. That is what makes a re-find, a join, and a diff possible, none of which a fresh scrape's churning place_id can support, no matter how recent it is.
What are the alternatives to relying on fresh data?
There are four honest ways to get identity stability into your data. Each has real tradeoffs, and the right choice depends on whether you need live freshness, scale, budget, or durable identity. I'm naming where each one breaks, not handing you a build guide, assigning and maintaining stable IDs yourself is the hard part, and it's a maintained system, not a script.
1. Keep relying on fresh scrapes (and accept churning IDs). Best for disposable, single-use data where you'll never re-find a row. It wins on review counts, ratings, and live hours. It loses the moment you re-run, join, or diff, because the scraped place_id is documented as unstable. Fine as a tactic, wrong as a foundation.
2. Mint and maintain your own internal IDs. Best for organizations with a data team and a permanent need. You'd own the entity resolution that decides which rows are the same place, the ID-minting scheme, the re-matching every time a source refreshes, and the drift handling when your own scheme collides with reality. It's weeks of recurring work, and your IDs are only as durable as the discipline behind them. Real, but expensive and slow.
3. License a commercial data provider's IDs. Best for enterprises that want a turnkey contract. You buy the vendor's identifiers and refresh cadence, usually at enterprise pricing, and you're locked to their schema and their definition of identity. Good if the contract fits; heavy if you just have a list that needs stable keys.
4. Resolve your list against an open, stably-identified ground truth. Best for teams that have a place list (a CRM, store locations, a scrape they already paid for) and want every record stamped with a persistent global ID without building the ID system. This is the category the Business Data Enricher Apify actor sits in, you bring a list or pull a territory and get back canonical records stamped with Overture GERS IDs under CDLA Permissive 2.0, so they stay joinable across runs and over time. It's one of the few tools built to give your data identity rather than just freshness. Best when the job is "make my records re-findable," not "show me today's map."
| Approach | Stable IDs | Live freshness | Resale license | Re-findable next run | Maintenance burden |
|---|---|---|---|---|---|
| Fresh scrapes | Ephemeral place_id | Yes (reviews, hours) | Restricted by Google TOS | No | Re-scrape each time |
| Mint your own IDs | Only if you build it | Depends on source | Depends on source | If you maintain it | High, recurring |
| Commercial provider | Vendor's IDs | Often | Per contract | Yes | Vendor-managed, costly |
| Resolve vs open ground truth | Yes (GERS) | Monthly refresh | Yes (CDLA) | Yes | Handled by the actor |
Pricing and features based on publicly available information as of June 2026 and may change. Open datasets like Overture refresh monthly and do not carry reviews, ratings, or live hours; for those, a Maps scrape still wins.
Each approach trades off identity durability against freshness, cost, and maintenance. The right choice depends on whether the data is disposable or durable, and how often you'll re-run it.
Best practices for data identity
Seven things I'd tell anyone treating data as more than a one-off pull.
- Decide if the data is disposable before you pull it. Touch it once, freshness is all that matters. Touch it twice, identity matters more. Make that call upfront, not after the project is built on churning keys.
- Never use an ephemeral key as a join key. A scraped
place_idwill churn, and your joins will rot silently. Join on a persistent identifier designed to survive, or don't join. - Resolve identity before you enrich. Adding contacts or signals to un-resolved rows enriches your duplicates. Stamp the stable ID first, then layer on top of the clean cohort.
- Treat freshness and stability as separate requirements. Write down which fields need to be current (ratings, hours) and which need to be durable (identity, join keys). They're different sources and different tools.
- Diff on identity, not on files. Change tracking means the same stable IDs differenced across two dates, not eyeballing two fresh exports side by side and guessing which rows match.
- Audit your ID stability, not just your row count. A fresh dataset with a high ID-churn rate is worse than a slightly older one that re-finds cleanly. Measure re-find rate, not just recency.
- Match the source to the property you need. Live ratings come from a scrape; durable identity comes from resolution against ground truth. Don't ask one source to do the other's job.
Common mistakes with data identity
Six mistakes I see constantly, each with a real cost.
- Optimizing freshness for a durability job. Paying for the newest scrape to feed a two-year CRM is solving the wrong problem. The CRM needs stable identity; the scrape gives it recency and churning keys.
- Using a scraped
place_idas a primary key. It works for weeks, then the IDs churn, the re-sync creates duplicates, and the table fills with orphaned rows exactly when the data starts to matter. - Believing fresher means cleaner. Freshness has nothing to do with dedupe. Two fresh scrapes of one city double every overlapping business, because freshness never touched the identity problem.
- Diffing files instead of identities. Re-running a scrape and comparing the exports by hand flags spelling changes as "moves," because without stable IDs the rows won't line up.
- Enriching before resolving. Layering emails onto un-resolved rows means you enrich the duplicates too, and now your contact counts are inflated by the duplicate rate.
- Confusing "captured recently" with "trustworthy." A recent capture of an unstable key is still unstable. Recency is not reliability, and treating it as such is how datasets quietly rot.
A concrete before/after
A franchise-scouting team I talked through this was obsessed with freshness. They re-scraped every metro monthly to "keep the data current," pasted it into a master sheet, and deduped by hand. The before state: a fresh pull every month, roughly 18% duplicate rows by their own count, scraped IDs they couldn't join on, and, despite all that freshness, zero ability to answer "which locations closed since last month," because the IDs never lined up.
The change was reframing the job from "keep it fresh" to "give it identity." They stopped chasing the newest scrape as the dataset and started resolving their list against stably-identified ground truth, stamping each record with a persistent ID. After: the same place kept the same ID across runs, the duplicate rate dropped to near zero because dedupe was no longer a manual eyeball pass, and the closures they'd been blind to surfaced as a clean diff between two captures. The two analyst-days per refresh dropped to about an hour of review. Their numbers, their context, results vary with list quality and territory size.
Implementation checklist
The sequence for moving from freshness-chasing to a real identity strategy.
- Audit your current data. Measure two things: how stale it is, and how stable its keys are. Most teams measure only the first and are shocked by the second.
- Classify each field. Mark which fields need to be fresh (ratings, hours) and which need to be durable (identity, join keys). They come from different places.
- Inventory your inputs. A CRM table, store locations, supplier lists, a scrape you already paid for, anything with a name and a location is a valid input to resolution.
- Resolve against stable ground truth. Run the list through a resolution tool like the Business Data Enricher Apify actor to stamp every record with a persistent GERS ID.
- Adopt the stable ID as your join key. Replace any scraped
place_idjoins with the persistent identifier. This is what makes re-runs and joins durable. - Pull freshness separately, on demand. When you need live ratings or hours, run a targeted Maps scrape against the stable cohort, don't make freshness the foundation.
- Diff captures for change. Once identities are stable, differencing two pulls gives you openings, closures, and rebrands for free.
Limitations
Honest constraints, because stability isn't magic and freshness isn't useless.
- Stable IDs don't make stale data current. A GERS ID keeps a record re-findable, but it won't update last quarter's rating. For live fields you still need a scrape layered on top. Identity and freshness are complementary, not substitutes.
- Resolution needs an input. Stamping a stable ID matches a list you bring or a territory you pull against ground truth. It's not a discovery tool for "find every business that might exist", it's a match, which is a different and more reliable thing.
- Match confidence isn't always 100%. A name with no coordinates resolves at lower confidence than a name plus a location. Resolution flags the uncertain matches rather than pretending they're certain, but sparse input has a low-confidence tail.
- Open ground truth has coverage gaps. Stably-identified open datasets are strong in well-mapped areas and thinner in some regions. Dense urban markets resolve better than sparse rural ones.
Key facts about stable IDs vs fresh data
- Freshness describes when a record was captured; a stable identifier describes whether you can re-find that same record later.
- Google's
place_idis documented as subject to change, so even a freshly scraped ID is unreliable as a long-term join key. - Deduplication, joins, and change tracking all depend on stable identity, not on how recent the data is.
- Overture Maps' GERS IDs stay stable across releases, keeping records joinable over time.
- Two fresh scrapes of one area produce duplicates, because freshness never resolves the identity problem.
- Live ratings, review counts, and today's hours are pure-freshness fields where a Google Maps scrape is the right tool.
- Local business data decays roughly 20-30% per year, and only stable IDs let you measure that decay across captures.
- A record's value in a dataset lives in its relationships to other records, re-finds, joins, diffs, all of which are made of stable identity.
Glossary
- Stable identifier, A key that refers to the same real-world entity across time and re-runs, so records stay re-findable and joinable.
- GERS ID, Overture Maps' Global Entity Reference System identifier; a persistent global fingerprint for a place that stays stable across data releases.
- Ephemeral key, A convenient-now, unreliable-later identifier (like a scraped
place_id) that can churn or get reassigned. - Data freshness, How recently a record was captured; a property of a single snapshot, not of the dataset over time.
- Entity resolution, The discipline of deciding which records refer to the same real-world thing, a precondition for stable IDs.
- Record linkage, The broader field of matching records across sources to a shared identity; identity stability is its foundation.
Where these patterns apply beyond Google Maps
The stability-over-freshness distinction isn't really about Maps. It's a general truth about identity in any data you reuse, and it applies far past local business records.
- Identity is upstream of everything. Any data you'll re-run needs a persistent key, whether it's places, companies, products, or people. Unstable IDs poison every join, in every domain.
- Freshness and stability are different axes. Recency improves a single record; stability connects records across time. Optimizing one never gives you the other.
- The value is in the relationships. A dataset's worth lives in re-finds, joins, and diffs, all of which are made of stable identity, not recency.
- Change is the high-value signal. A snapshot tells you state; stable identity tells you what moved. True for prices, jobs, filings, and storefronts alike.
- Match the property to the job. Some work needs the newest possible capture; most durable work needs a key that survives the second capture. Picking wrong is the common failure.
When you need this
You probably need stable identity (not just fresh data) if:
- You re-run the same queries or territories on a schedule.
- You're maintaining a CRM or any dataset you'll re-sync over time.
- You need to merge multiple sources without duplicates.
- You care about openings, closures, or rebrands over time.
- You plan to join place data to other tables on a reliable key.
You probably don't need this if:
- You're doing a genuine one-off lookup you'll never touch again.
- Your use case lives entirely on live reviews, ratings, and today's hours.
- The list is small enough to use once and discard.
Frequently asked questions
What's more important, fresh data or stable IDs?
It depends on the job, but for any data you reuse, stable IDs matter more. Freshness improves a single snapshot; a stable identifier lets that snapshot connect to past and future ones through re-finds, joins, and diffs. Fresh data with churning keys can't do any of those, so it rots into duplicates the moment you touch it twice. Freshness wins only when the value is the current state itself, like live ratings or today's hours.
Why does a Google place_id change?
Google documents the place_id as subject to change, it can be updated as the underlying place record is refined, merged, or re-indexed. That means even a freshly scraped place_id isn't guaranteed to point at the same business next quarter. It's a convenient handle for one lookup, but it was never designed to be a durable join key, which is why building re-runs or CRM joins on it eventually breaks.
What is a GERS ID?
GERS (Global Entity Reference System) is Overture Maps' persistent identifier for a real-world place. Unlike a scraped place_id, a GERS ID is designed to stay stable across data releases, so a record carrying one stays joinable and re-findable over time. That stability is what turns a one-time list into a dataset you can build durable joins and change tracking on, rather than a stack of unrelated captures.
Can I just keep my data fresh enough to avoid the ID problem?
No, that's the contrarian point. Re-scraping more often doesn't fix identity, it multiplies the problem. Each fresh pull brings new churning keys, so the more often you scrape, the more duplicate and orphaned rows you accumulate, because there's no stable key to collapse them on. Freshness and identity are different axes. You can't reach stability by turning the freshness dial up; you need a persistent identifier underneath the fresh data.
Do stable IDs mean I never need to scrape again?
Not at all. Stable IDs and fresh data are complementary. A persistent ID keeps a record re-findable and joinable, but it won't update last quarter's rating or today's hours, those live fields still come from a Google Maps scrape. The right pattern is to resolve your list to stable identities once, then layer targeted freshness on top of that stable cohort when you actually need current values. Identity is the foundation; freshness is the layer.
How do I get stable IDs without building the system myself?
Assigning and maintaining stable IDs yourself means owning entity resolution, an ID-minting scheme, and re-matching every time a source refreshes, a maintained system, not a script. The shortcut is resolving your list against open ground truth that already carries persistent IDs. The Business Data Enricher Apify actor does this: you bring a list or pull a territory, and every record comes back stamped with a stable GERS ID under a resale-safe license, joinable across runs.
Ryan Clinton publishes Apify actors and MCP servers as ryanclinton and builds developer tools at ApifyForge.
Last updated: June 2026
This guide focuses on Google Maps and place data, but the same stability-over-freshness patterns apply broadly to any data you intend to re-find, join, or track over time.