The problem: You have a pile of business records. Maybe it's a CRM export, maybe a Google Maps scrape someone paid for, maybe three supplier lists glued together. The names are spelled six ways, half the rows are duplicates, the IDs don't survive a re-run, and you can't legally ship any of it in a product. Everyone keeps calling this "our place data." It isn't a dataset yet. The thing that turns it into one has a name, and most people have never heard it: place resolution.
I publish actors on the Apify Store as ryanclinton, including ones in this exact space, so I've watched this gap wreck more than a few projects. The pillar piece on why a Google Maps scrape isn't a data strategy made the argument that a scrape is a tactic, not a foundation. This post defines the foundation it pointed at. Place resolution is one of the least discussed but most important concepts in local business data, the layer everything durable sits on, and almost nobody names it.
If your problem is already "I have a business list and need it cleaned, deduplicated, stably identified, and safe to reuse," that's the job the Business Data Enricher Apify actor was built for, but read on, because resolution is a category, not just a tool.
What is place resolution? Place resolution is the process of matching a list of messy business listings against a canonical, licensed ground-truth dataset to produce one deduplicated, persistently-identified record per real-world place, records you can join, track over time, and legally reuse.
Why it matters: Local business data decays roughly 20-30% per year as places move, close, rebrand, and change hands. Without resolution you can't tell which rows are the same place, which closed, or whether you're even allowed to keep the data (Overture Maps ships under CDLA Permissive 2.0, built for reuse, most scrapes do not).
Use it when: You're populating a CRM, building a product on place data, mapping a territory, merging multiple sources, or maintaining any place dataset you'll re-run, join, or audit more than once.
Also known as: POI resolution · point-of-interest resolution · place entity resolution · location data resolution · business listing reconciliation · canonical place matching · place data canonicalization · ground-truth place matching.
Quick answer
- What it is: matching messy business listings to a canonical, licensed ground-truth record so each real-world place gets one deduplicated, stable identity.
- When to use it: any place data you'll re-run, join, resell, ship in a product, or track over time.
- When NOT to use it: genuine one-off lookups, throwaway prospecting, or use cases that live entirely on live reviews and today's hours.
- Typical inputs: a dirty list, CRM rows, store locations, supplier files, or a scrape you already paid for, each with a name and ideally a location.
- Main tradeoff: resolution gives you owned, stable, deduplicated, resale-safe records; it does not give you live reviews, ratings, or popular times. Different job from scraping.
In this article: What it is · Why it matters · How it works · Extraction vs resolution vs enrichment · Alternatives · Best practices · Mistakes · FAQ
Key takeaways
- Place resolution collapses many dirty rows into one canonical record per real-world place, which is the single thing a raw scrape or export can't do for you.
- It assigns a persistent global identifier, Overture's GERS ID, that stays stable across data releases, unlike Google's
place_id, which is documented as subject to change. - It produces records under a resale-permissive license (CDLA Permissive 2.0 on Overture data), the opposite legal posture of scraped Google content bound by the Google Maps Platform Terms.
- It's a distinct middle layer between extraction (scraping listings) and enrichment (adding contacts and signals), and it's the one most data stacks skip.
- Stable identities make change tracking possible: openings, closures, and rebrands fall out of differencing two captures, something a snapshot structurally can't produce.
Resolution in concrete terms
| Your input | What raw data gives you | What place resolution gives you |
|---|---|---|
| "Dominos Pizza", "Domino's", "Domino's - Belfast" | Three ambiguous rows | One canonical place, one stable ID |
| Two scrapes of the same city | Duplicate rows for every overlap | One row per real-world business |
A scraped place_id as a join key | An ID that may churn next quarter | A persistent GERS ID that joins forever |
| "Can I resell this?" | A Google TOS minefield | Records under CDLA Permissive 2.0 |
| "Which of these closed?" | No way to know | A change feed of openings and closures |
What is place resolution?
Definition (short version): Place resolution is a data process that matches messy business listings against a canonical, licensed ground-truth dataset and returns one deduplicated, persistently-identified record per real-world place.
The word doing the work is canonical. A scrape or an export gives you listings, whatever showed up, however it was spelled, with whatever IDs the source happened to mint. Resolution decides which of those listings refer to the same real place, picks the authoritative version of each, attaches a stable identity, and hands back a clean record you can actually build on.
It's worth being precise about what resolution is not. It's not discovery (finding businesses that might exist). It's not enrichment (bolting contacts onto rows). It's not a scraper with a dedupe button. It's a match against ground truth, which is a more reliable and more durable operation than any of those.
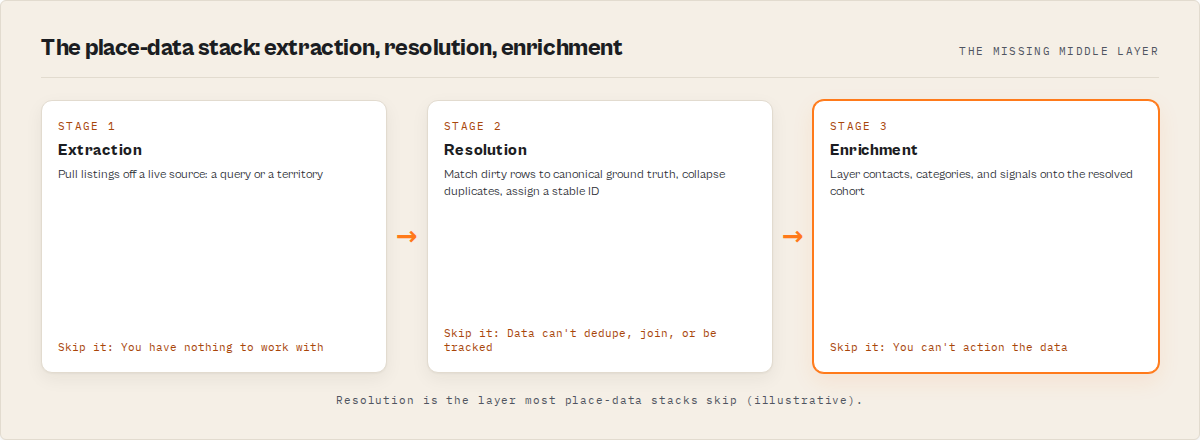
There are broadly three layers in any place-data stack, and resolution is the middle one. Extraction pulls listings off a live source. Resolution matches those listings to canonical entities. Enrichment layers contacts, categories, or signals on top. Most teams build the first and third and leave a hole where the second should be, which is exactly why their place data rots.
Why does place resolution matter?
Place resolution matters because local business data is constantly changing and inherently messy, and without a canonical, stably-identified foundation you can't dedupe it, join it, track its changes, or legally reuse it. Resolution is the layer that makes place data survive a re-run.
The decay rate is the part people underestimate. Businesses move, close, rebrand, and change owners at roughly 20-30% per year. A snapshot is blind to all of it. The U.S. Bureau of Labor Statistics has long tracked establishment churn in the same ballpark, about half of new businesses don't survive five years. If your data has no stable spine, you can't even tell which of your rows are the casualties.
How does place resolution work?
Place resolution works by taking each messy input row, finding the single real-world place it refers to in a licensed ground-truth dataset, collapsing duplicates that point at the same place, and returning a canonical record carrying a persistent identifier and resale-safe attributes. Same input run twice yields the same identity.
I'm going to describe what resolution produces, not how to build it, because the matching logic is the hard part and the part worth paying for. Conceptually: you bring a list, the resolution layer reconciles each row against ground truth, and you get back canonical entities. The difficulty hides in the reconciliation, names spelled inconsistently, addresses formatted half a dozen ways, coordinates that drift, franchise brands that legitimately repeat across a city, and a confidence judgment for the matches that aren't obvious.
That reconciliation is a genuine, maintained data-engineering discipline. If you owned it yourself you'd own fuzzy name comparison, address normalization, geospatial tolerance, brand handling, a confidence model for uncertain matches, stable-ID assignment, and re-running all of it every time the ground-truth dataset refreshes (Overture publishes monthly). That's a service, not a script. The point of a resolution tool is that it carries that weight so you don't.
What does a resolved record actually look like?
A resolved record is one canonical row per real-world place, carrying a persistent global ID, a normalized name and category, and a resale-safe license tag. The dirty inputs that matched it are collapsed into that single row, with the slang and the misspellings reconciled to the real entity.
Here's the shape, using the classic ambiguous case. Three dirty inputs go in; two canonical entities come out, the duplicate collapsed and the slang resolved:
{
"input": [
{ "name": "Dominos Pizza", "lat": 54.5810, "lng": -5.9398 },
{ "name": "Domino's", "address": "Belfast BT9 6AA" },
{ "name": "Maccies", "lat": 54.5972, "lng": -5.9301 }
],
"resolved": [
{
"gers_id": "08f1949...c3a",
"name": "Domino's Pizza",
"category": "pizza_restaurant",
"address": "Belfast BT9 6AA",
"matched_inputs": ["Dominos Pizza", "Domino's"],
"confidence": 0.97,
"license": "CDLA-Permissive-2.0"
},
{
"gers_id": "08f1951...b07",
"name": "McDonald's",
"brand": "wikidata:Q38076",
"category": "fast_food_restaurant",
"matched_inputs": ["Maccies"],
"confidence": 0.89,
"license": "CDLA-Permissive-2.0"
}
]
}
That's the whole value in one object. Two real places, each with a stable ID you can join on forever, a confidence score on the match, and a license that says you're allowed to keep it. That record survives a re-run, a join, and an audit. The three input strings don't.
Extraction vs resolution vs enrichment
Extraction, resolution, and enrichment are three different jobs in a place-data stack, and confusing them is why so much local data rots. Extraction gets the listings, resolution makes them canonical, and enrichment adds signals on top, in that order, because enriching un-resolved rows just enriches your duplicates.
Raw listings
↓
Place resolution ← the missing middle layer
↓
Canonical businesses (one stable-ID'd record per real place)
↓
Enrichment
↓
Actionable data
The order matters more than people think. Enrich before you resolve and you spend money adding contacts to duplicate rows, then dedupe and throw half of them away. Resolve first, enrich the clean cohort, and every enrichment dollar lands on a real, distinct place. I've seen teams burn a chunk of an enrichment budget learning this the expensive way.
| Layer | Job | Input | Output | Skip it and… |
|---|---|---|---|---|
| Extraction | Pull listings off a live source | A query or territory | Raw rows (a snapshot) | You have nothing to work with |
| Resolution | Match rows to canonical ground truth | A dirty list | One stable-ID'd record per place | Your data can't dedupe, join, or be tracked |
| Enrichment | Add contacts, categories, signals | A resolved cohort | Rows with extra attributes | You can't action the data |
This is a layering model, not a vendor ranking. The same row often passes through all three at different points in its life.
What are the alternatives to place resolution?
There are four honest paths once you accept that raw place data needs a canonical foundation. Each has real tradeoffs, and the right choice depends on whether you need live freshness, resale rights, scale, or stable identity. None is free of work, I'm naming where each one breaks, not handing over a build guide.
1. Do nothing and keep the dirty list. Best for genuinely disposable data you'll touch once. It "wins" only because it's zero effort. It loses the moment you re-run, join, merge, or ship, the duplicates double-count, the IDs churn, and the legal posture is whatever the source's terms say. Fine for a throwaway lookup, wrong as a foundation.
2. Build resolution in-house. Best for organizations with a standing data team and a permanent need. You'd own the spatial match against an open dataset, fuzzy name matching, address normalization, deduplication, a confidence model, and stable-ID assignment, then own re-running all of it every monthly refresh. It's weeks of recurring engineering, and the output is only as durable as the ID scheme you invent. Real, but slow and expensive, and it never stops needing maintenance.
3. License a commercial place-data provider. Best for enterprises that want a turnkey contract and have budget. You buy cleaned data, but you're buying the vendor's identifiers, their refresh cadence, and their schema, usually at enterprise pricing. Good if the contract fits; heavy if all you have is a list that needs cleaning.
4. Resolve your list against licensed open ground truth. Best for teams that already have a dirty place list and want it canonical, deduplicated, stably identified, and resale-safe without building the pipeline. This is the category the Business Data Enricher Apify actor sits in, you bring a list or pull a territory and get back canonical records on Overture Maps data under CDLA Permissive 2.0, with a change feed of openings, closures, and rebrands. It's one of the few tools built for place resolution rather than extraction. Best when the job is "make my place data durable," not "show me a map."
| Approach | Stable IDs | Legal to resell | Deduplicated | Change tracking | Effort |
|---|---|---|---|---|---|
| Keep the dirty list | No | Depends on source | No | No | None upfront, high later |
| Build in-house | Only if you build it | Depends on source | If you build it | If you build it | Weeks, recurring |
| Commercial provider | Vendor's IDs | Per contract | Yes | Often | Procurement + lock-in |
| Resolve vs open ground truth | Yes (GERS) | Yes (CDLA) | Yes | Yes (change feed) | Bring a list, run it |
Pricing and features based on publicly available information as of June 2026 and may change. Open datasets like Overture refresh monthly and carry no reviews, ratings, or live hours, for those, a Google Maps scrape still wins.
Best practices for place resolution
Eight things I'd tell anyone treating local business data as more than a one-off pull.
- Decide disposability before you resolve. If you'll touch the data once, you don't need resolution. If you'll touch it twice, you do. Make that call before the project is built, not after it cracks.
- Resolve before you dedupe, count, or score. Every duplicate double-counts. Resolution is the first operation, not a cleanup pass tacked on at the end.
- Adopt the stable ID as your join key. Replace any scraped
place_idjoins with the persistent GERS identifier. Unstable IDs rot your joins silently. - Check the license at ingestion. "Can I resell this?" is a question for the moment data enters your stack, not the moment a customer asks where it came from. CDLA Permissive 2.0 exists for exactly this.
- Keep a confidence threshold. Resolution should flag low-confidence matches, not pretend they're certain. Names-only inputs with no coordinates resolve weaker than name-plus-location, treat the tail accordingly.
- Enrich the resolved cohort, never the raw rows. Run a contact enrichment pipeline over canonical places, so you don't pay to enrich duplicates.
- Capture change by differencing identities, not files. Re-running and eyeballing two exports isn't change tracking. Same stable IDs, two dates, differenced, that's a change feed.
- Match freshness needs to the source. If your use case lives on review counts and today's hours, the open datasets won't carry it and a Maps scrape (or a hybrid) is the honest answer. Be clear which job you're doing.
Common mistakes with place data
Six mistakes I see constantly, each with a real cost.
- Treating an export as a dataset. A CRM dump or a scrape is input to resolution, not the finished product. Skipping the middle layer is the root error everything else descends from.
- Joining on a scraped place ID. It works for a month, then the IDs churn, the re-sync spawns duplicates, and your CRM fills with ghost records, right when the data starts to matter.
- Enriching before resolving. You pay to add emails to duplicate rows, then dedupe and bin the wasted spend. Order is resolution first, enrichment second.
- Counting on un-resolved rows. Density, market size, targeting, all wrong in proportion to your duplicate rate, and you won't know by how much.
- Mistaking two snapshots for a change feed. Without stable identities the rows won't line up, so you'll flag spelling changes as relocations and miss the actual closures.
- Ignoring the license question. Shipping scraped Google content as "your" data is a contractual hole that surfaces in a legal conversation, not a code review.
A concrete before/after
A regional franchise-scouting team I talked through this had a working setup: a Google Maps scraper run per metro, results pasted into a master sheet, deduplicated by hand. The before state was about two days of analyst time per refresh, a master sheet running roughly 18% duplicate rows by their own count, scraped IDs they couldn't trust as join keys, and zero visibility into which locations had closed since the last pull.
The change was reframing the job from "scrape and clean" to "resolve once." They stopped treating the scrape as the dataset and started treating their list as input to resolution against licensed ground truth. After: one run produced canonical, deduplicated, stably-identified records; the duplicate rate dropped to near zero because dedupe was no longer a manual eyeball pass; the stable IDs gave them a join key that survived refreshes; and a change feed surfaced the closures the old workflow had been blind to. Two analyst-days per refresh became roughly an hour of review. Those are their numbers in their context, results vary with list quality and territory size.
Implementation checklist
The sequence for moving from "dirty list" to a real, resolved place dataset.
- Audit what you have. Pull your current place data into one place and measure the duplicate rate and ID stability. The numbers are usually worse than people expect.
- Classify the use case. Disposable lookup, or durable dataset? This single decision drives everything downstream.
- Inventory your inputs. CRM tables, store locations, supplier lists, scrapes you already paid for, anything with a name and a location is a valid input to resolution.
- Resolve against licensed ground truth. Run the list through a resolution tool like the Business Data Enricher Apify actor to get canonical, deduplicated, stable-ID'd records under a resale-safe license.
- Adopt the stable ID as your join key. Swap scraped
place_idjoins for the persistent GERS identifier. This is what makes re-runs and joins durable. - Stand up change tracking. With identities stable, differencing two captures gives openings, closures, and rebrands without extra work.
- Layer enrichment last. Need contacts on top? Run a contact enrichment pipeline or a Google Maps lead enricher over the resolved cohort, not over raw rows.
Limitations
Honest constraints, because resolution isn't magic and a scrape isn't useless.
- Open ground truth isn't live. Overture Maps refreshes monthly and carries no reviews, ratings, live hours, or popular times. For "what's this place's rating and today's hours," a Google Maps scrape genuinely wins. Resolution is canonical identity, not a real-time Maps replacement.
- Match confidence has a tail. Names-only inputs with no coordinates resolve at lower confidence than name-plus-location. Resolution flags the uncertain matches rather than faking certainty, but a sparse input list will leave a low-confidence tail you have to review.
- Resolution needs an input. It cleans and canonicalizes a list you bring or a territory you pull. It's not a discovery engine for "find every business that might exist", it's a ground-truth match, which is a different and more reliable thing.
- Coverage varies by region. Open place datasets are strong in well-mapped areas and thinner elsewhere. Dense urban markets resolve better than sparse rural ones.
Key facts about place resolution
- Place resolution matches messy business listings against canonical ground truth to produce one deduplicated, stably-identified record per real-world place.
- It sits between extraction (scraping listings) and enrichment (adding signals) and is the layer most place-data stacks skip.
- It assigns a persistent GERS identifier that stays stable across data releases, unlike Google's churning
place_id. - It produces records under CDLA Permissive 2.0 on Overture data, a license built for resale and product-building.
- Local business data decays at roughly 20-30% per year, which is why a one-time snapshot can't be a durable dataset.
- Change tracking, openings, closures, rebrands, requires stable identities differenced across two captures, something raw scrapes can't produce.
- Resolving before enriching prevents paying to enrich duplicate rows.
- Proper resolution is a maintained data-engineering discipline, not a spreadsheet filter, because the matching logic must be re-run every time the ground-truth dataset refreshes.
Glossary
- Place resolution, Matching a list of business listings against canonical ground truth to produce deduplicated, stably-identified records.
- Entity resolution, The broader data-engineering discipline of deciding which records refer to the same real-world thing; place resolution is its application to physical places.
- GERS ID, Overture Maps' Global Entity Reference System identifier; a persistent global fingerprint for a real-world place that stays stable across data releases.
- Canonical record, The single authoritative row chosen to represent a real-world place after duplicates are collapsed.
- Ground truth, A reference dataset treated as authoritative, against which messy input is matched and corrected.
- CDLA Permissive 2.0, A Community Data License Agreement license that permits redistribution and product-building on the licensed data.
Where these patterns apply beyond places
Resolution isn't really a Maps idea. It's a general truth about turning extractions into datasets, and it applies anywhere you're tempted to treat raw rows as a foundation.
- Identity must be stable to be useful. Companies, products, people, places, anything you'll re-run needs a persistent key, or every join silently rots.
- Resolution is upstream, not cleanup. Counting or scoring on un-resolved rows is wrong in proportion to the duplicate rate, in every domain.
- License posture is a design decision. "Can I legally reuse this?" should be answered at ingestion for any external data, not discovered downstream.
- Change is the high-value signal. A snapshot tells you state; a resolved, stable spine tells you what moved. True for prices, filings, jobs, and storefronts alike.
- Extraction, resolution, and enrichment are separate jobs. Getting rows, knowing what they mean, and acting on them are three problems, and the middle one is where durable value lives.
When you need this
You probably need place resolution if:
- You're populating or maintaining a CRM with local business records.
- You plan to resell, ship, or productize place data.
- You re-run the same territories or queries on a schedule.
- You need to merge multiple sources of place data without duplicates.
- You care about openings, closures, or rebrands over time.
You probably don't need it if:
- You're doing a genuine one-off lookup you'll never touch again.
- Your use case lives entirely on live reviews, ratings, and today's hours.
- The list is small enough to clean by hand once and discard.
Frequently asked questions
What is place resolution in simple terms?
Place resolution is the process of taking a messy list of business listings, different spellings, duplicates, unreliable IDs, and matching each one to a single canonical record in a licensed ground-truth dataset. You end up with one clean, stably-identified row per real-world place that you can join, track, and legally reuse. It's the layer that turns a pile of listings into an actual dataset.
How is place resolution different from scraping?
Scraping (extraction) pulls listings off a live source as a one-time snapshot with no stable identity and no deduplication. Place resolution takes those listings and matches them to canonical ground truth, collapsing duplicates and assigning persistent IDs. Scraping gets you the raw rows; resolution makes them durable. The pillar piece covers why a scrape alone isn't a foundation.
Is place resolution the same as enrichment?
No. They're different layers. Resolution makes your place list canonical and deduplicated, the foundation. Enrichment adds contacts, emails, categories, or signals on top, which is what a Google Maps lead enricher does. You resolve first to get a clean cohort, then enrich it. Enriching before resolving just adds attributes to duplicate rows you'll later throw away.
What is a GERS ID and why does it matter for resolution?
GERS (Global Entity Reference System) is Overture Maps' persistent identifier for a real-world place. Unlike a scraped place_id, which is documented as subject to change, a GERS ID is designed to stay stable across data releases. That stability is what lets a resolved record stay joinable and re-findable over time, it's the spine change tracking and durable joins are built on.
Can I do place resolution myself with a spreadsheet?
Not reliably. Proper resolution is entity resolution applied to places: fuzzy name matching, address normalization, geospatial tolerance, franchise-brand handling, and a confidence model for uncertain matches, re-run every time the ground-truth dataset refreshes. It's a maintained data-engineering system, not a filter. Most teams underestimate it badly, which is why end-to-end resolution tools like the Business Data Enricher Apify actor exist.
Is resolved place data legal to resell?
That depends on the source. Records resolved against Overture Maps ship under CDLA Permissive 2.0, a license built for redistribution and product-building, so yes, that posture is resale-friendly. Scraped Google content, by contrast, is bound by the Google Maps Platform Terms, which restrict caching, redistribution, and building competing datasets. This isn't legal advice, but the difference in posture is stark.
When should I still just scrape instead of resolving?
When the data is disposable, or when your whole use case lives on live signals. A one-off competitor check, a quick prospecting list you'll burn after one campaign, or anything that needs current reviews, ratings, and today's hours, a Google Maps scrape is the right tool. The moment the data has to survive a re-run, a join, a resale, or a "what changed" question, you need resolution.
Ryan Clinton publishes Apify actors and MCP servers as ryanclinton and builds developer tools at ApifyForge.
Last updated: June 2026
This guide focuses on local business data and Apify, but the same extraction-resolution-enrichment patterns apply broadly to any messy data you intend to treat as a durable dataset.