The problem: You merged two exports of business listings, ran a "remove duplicates" pass on the name column, and shipped it. It looked clean. Then someone noticed "Domino's Pizza," "Dominos," and "Domino's Pizza - Belfast" all survived as separate rows, the same franchise showed up four times because four real branches share a name, and your count of "businesses in the territory" was off by a quarter. Dedup felt like a one-line job. At scale it isn't. It's entity resolution, and it quietly breaks every project that treats it as a spreadsheet filter.
Notice the example didn't depend on where the data came from. A CRM export, a supplier feed, a directory dump, marketplace data, two Google Maps scrapes glued together, they all produce the same duplicate problem, because the problem isn't the source. It's that none of them carry a stable identity for the real-world place each row is supposed to represent. This is a problem about identity, not about any one scraper.
I publish actors on the Apify Store as ryanclinton, including ones in exactly this space, so I'm not here to tell you data work is hard for the sake of it. The argument is specific: deduplicating business listings at scale is not a cleanup step you bolt on at the end, it's a discipline, and past a few thousand rows the durable answer is to resolve your list against canonical ground truth rather than build the dedup yourself. This is supporting reading for the pillar Google Maps Scraping Isn't a Data Strategy, where dedup is one of five structural gaps. Here I'm zooming all the way into that one gap.
If your actual problem right now is "I have a messy business list and need one clean row per real place," that's the job the Business Data Enricher Apify actor was built for, but read on for why naive dedup fails first, because that's the part most teams learn the expensive way.
What is business listing deduplication? Deduplicating business listings means collapsing multiple records that describe the same real-world business into one canonical record, while keeping genuinely different businesses separate, even when they share names, addresses, or coordinates.
Why it matters: Local business data is messy by nature, names are spelled multiple ways, addresses are formatted inconsistently, coordinates drift, and franchise brands repeat legitimately. Without correct dedup, every downstream count, score, and join is wrong in proportion to the duplicate rate.
Use it when: You're merging multiple sources, populating a CRM, sizing a market, or maintaining any business dataset where "how many real places are in here" has to be a trustworthy number.
Also known as: business record deduplication · place entity resolution · listing record linkage · merging duplicate business records · canonicalizing place data · business data deduplication at scale.
Quick answer
- What it is: the work of collapsing duplicate business listings into one record per real-world place, which at scale is entity resolution, not a "remove duplicates" button.
- When a simple dedup is fine: a few hundred rows from one clean source, deduped once and discarded.
- When it is not fine: merging sources, anything you re-run, anything where the count has to be right, or any list past a few thousand rows.
- The hard parts: name variants, address formats, coordinate drift, legitimate franchise repeats, and merging multiple sources with no shared key.
- Main tradeoff: building dedup yourself is a maintained system you re-run forever; resolving against ground truth hands you canonical, stably-identified records without owning the pipeline.
In this article: What it is · Why naive dedup fails · The five reasons · Alternatives · Best practices · Mistakes · FAQ
Key takeaways
- Deduplicating business listings at scale is entity resolution, a recognized data-engineering discipline, not a spreadsheet operation (record linkage, Wikipedia overview).
- Local business data decays at roughly 20-30% per year as places move, close, and rebrand, so dedup isn't a one-time pass, the duplicates regenerate every refresh.
- Exact-match dedup on a name or address column silently fails the moment spelling, formatting, or punctuation varies, which for business names is almost always.
- Merging two scrapes of the same area multiplies duplicates rather than removing them, because neither source carries a stable identifier to match on (place IDs are documented as subject to change).
- Resolving a list against licensed ground truth like Overture Maps returns one canonical record per place with a persistent global ID, under a resale-permissive CDLA license, the durable alternative to building dedup in-house.
What dedup looks like in practice
| Input rows (what you have) | Naive dedup result | Correct resolution result |
|---|---|---|
| "Domino's Pizza", "Dominos", "Domino's Pizza - Belfast" (one store) | 3 rows survive | 1 canonical record |
| "McDonald's" at 4 real branch addresses | 1 row (over-merged) or 4 (fine) depending on your rule | 4 canonical records, correctly distinct |
| Same café in two scrapes, names spelled differently | 2 rows | 1 canonical record |
| "Joe's Coffee" and "Joe's Coffee Roasters" next door (two businesses) | 1 row (wrong merge) | 2 canonical records |
| 50k merged rows from 3 sources, no shared key | Untrustworthy count | One stable ID per real place |
What is deduplicating business listings at scale?
Definition (short version): Deduplicating business listings at scale is entity resolution applied to place data, deciding which records refer to the same real-world business and collapsing them to one canonical record, while keeping genuinely separate businesses apart, across thousands or millions of inconsistently-formatted rows.
A small, clean list deduplicates with a sort and an eyeball. That's not the case that breaks. The case that breaks is the real one: tens of thousands of rows merged from a CRM, a couple of scrapes, a supplier export, and a partner feed, where the same business appears under different names, different address formats, and slightly different coordinates, and where four legitimate branches of one chain must stay four rows.
There are broadly three layers people conflate. Exact deduplication removes byte-identical rows, useful, but it almost never fires on business data because nothing is byte-identical. Fuzzy deduplication tries to match similar-looking rows, which is where most DIY attempts live and where they quietly start making wrong merges. Entity resolution is the full discipline: matching records to canonical real-world entities with a confidence model for the cases that aren't obvious. The whole point of this post is that business listings at scale need the third one, and the third one is a system, not a script.
Why does naive deduplication fail at scale?
Naive deduplication fails at scale because business listings vary in every field you'd dedup on. Names are spelled multiple ways, addresses are formatted six ways, coordinates drift, and franchises repeat legitimately. An exact-match or simple-fuzzy pass either leaves real duplicates or merges distinct businesses, and you can't tell which.
Here's the trap. A "remove duplicates on the name column" pass feels decisive. It deletes rows. The sheet gets shorter. It looks like progress. But it only catches byte-identical names, and business names are almost never byte-identical across sources, one feed has "St.", another "Saint", a scrape has a trailing " - Downtown", a CRM has an old trading name. So the obvious duplicates survive, hiding in plain sight.
Then someone turns up the aggressiveness with fuzzy matching, and the failure flips direction. Now "Joe's Coffee" and "Joe's Coffee Roasters", two different businesses on the same block, get merged because the names are similar. You've traded false negatives for false positives, and the second kind is worse, because a wrong merge is invisible. A surviving duplicate looks wrong. A bad merge looks clean. You only find it when a customer asks why their location isn't in your dataset.
The five reasons business listings resist deduplication
None of these is a quirk of one data source. They're inherent to local business data, and they're why dedup-at-scale is a maintained discipline rather than a one-liner. I'm describing why each is hard so it's clear what you'd be signing up to own, not how to solve them.
1. Names vary in ways no exact match catches
The same business carries a dozen surface forms: legal name, trading name, abbreviated name, the version with the neighborhood appended, the one with an old franchise tag, the typo. Exact dedup catches none of these. Fuzzy dedup catches some and over-reaches on others. Getting it right means a name-comparison model that knows "St." and "Saint" are the same but "Joe's Coffee" and "Joe's Coffee Roasters" aren't, and that judgment is the hard part, not the string compare.
2. Addresses are formatted every possible way
"123 Main Street, Suite 4", "123 Main St #4", "123 Main St., Ste 4, Belfast BT1", same place, three strings, zero exact matches. Address normalization is its own sub-discipline with edge cases for every country's postal conventions. Treating the raw address string as a dedup key means near-identical addresses never line up, so address-based dedup quietly does almost nothing while looking like it should work.
3. Coordinates drift, so "same lat/lng" doesn't work either
You might think coordinates would save you. They don't. The same business gets geocoded to slightly different points by different sources, and two genuinely different businesses in the same building or strip mall can sit meters apart. So a coordinate-distance rule needs a tolerance, and any tolerance you pick either merges neighbors or splits the same place, and the right tolerance is different for a rural plaza than a dense high street.
4. Franchises repeat legitimately, and over-merging destroys them
This is the one that punishes aggressive dedup. A city has many real branches of the same chain, same name, same brand, different real places. Any dedup rule tuned hard enough to catch name variants will start collapsing legitimate franchise branches into one row, silently deleting real locations from your dataset. Distinguishing "duplicate listing" from "different branch of the same brand" is a genuinely hard call that simple rules get wrong in both directions.
5. Merging multiple sources has no shared key to match on
The moment you combine a CRM, a scrape, and a supplier list, you have no common identifier to join on. Scraped place IDs are documented as subject to change and differ between sources anyway, so there's nothing reliable to match records by. You're back to matching on the messy fields above, across sources that each formatted them differently. This is where naive dedup goes from "imperfect" to "produces a number you cannot trust," and where most teams' duplicate counts quietly explode instead of shrinking.
What a duplicate rate actually costs
Duplicates aren't a tidiness problem, they're a counting problem. Every duplicate inflates your market size, your density, and your targeting by the same proportion, and the inflation is invisible until someone checks. Here is what a "100,000 businesses" dataset really contains at different duplicate rates:
| Duplicate rate | What "100,000 businesses" actually means |
|---|---|
| 5% | 95,000 real businesses |
| 10% | 90,000 real businesses |
| 20% | 80,000 real businesses |
| 30% | 70,000 real businesses |
A 20% duplicate rate, common in merged business data, means one in five "businesses" in your market sizing doesn't exist. That stops being a data-quality footnote the moment the number lands in a board deck, a territory plan, or a per-rep quota.
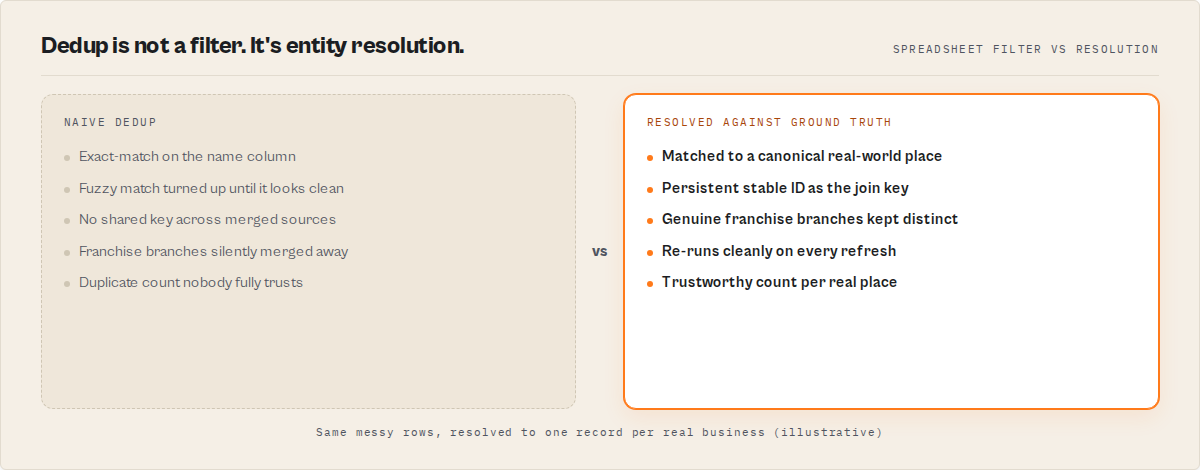
What does correct deduplication produce instead?
Correct deduplication produces one canonical record per real-world business, each carrying a persistent identifier so the same place lines up across sources and across re-runs. Genuinely distinct businesses, including separate franchise branches, stay separate. The duplicate count becomes a number you can trust.
Here's the shape of the difference. Dirty input with three forms of one store and one slang nickname for another resolves to two canonical entities, the duplicate collapsed and the distinct place kept:
{
"input": [
{ "name": "Dominos Pizza", "lat": 54.5810, "lng": -5.9398 },
{ "name": "Domino's", "address": "Belfast BT9 6AA" },
{ "name": "Maccies", "lat": 54.5972, "lng": -5.9301 }
],
"resolved": [
{
"gers_id": "08f1949...c3a",
"name": "Domino's Pizza",
"category": "pizza_restaurant",
"address": "Belfast BT9 6AA",
"matched_inputs": ["Dominos Pizza", "Domino's"],
"license": "CDLA-Permissive-2.0"
},
{
"gers_id": "08f1951...b07",
"name": "McDonald's",
"brand": "wikidata:Q38076",
"category": "fast_food_restaurant",
"matched_inputs": ["Maccies"],
"license": "CDLA-Permissive-2.0"
}
]
}
That's the output you're actually after: three dirty inputs became two canonical entities, the duplicate collapsed, the slang resolved to a real brand, and every record carries a stable ID and a resale-safe license. The point isn't the columns, it's that this survives a re-run, a join, and an audit, which a deduped sheet does not.
This is also why resolving against ground truth beats turning your fuzzy matcher up higher. Pairwise matching compares your messy rows to each other, with no fixed point of truth, so any comparison can be wrong and the errors compound as the list grows. Resolving against a canonical reference set flips the question from "do these two rows look alike?" to "which real-world place is this row?" There is an anchor, so a match is a match to something true rather than a guess that two strings resemble each other, and that is the difference between a count you can defend and one you just hope is right.
What are the alternatives for deduplicating business listings?
There are four honest ways to deal with duplicate business listings at scale. Each has real tradeoffs, and the right choice depends on volume, how often you re-run, whether you need a trustworthy count, and whether you have a data team to spare. I'm naming where each one breaks, not handing you a build recipe.
1. Manual / spreadsheet dedup. Best for a few hundred rows from one source, once. Sort, scan, delete the obvious doubles, ship it. It's fine at small scale and falls apart fast: it's slow, it's inconsistent between whoever does it, it can't catch cross-source variants, and it has to be redone every refresh. Past a few thousand rows it's not a method, it's a backlog.
2. Build fuzzy dedup in-house. Best for organizations with a data team and a permanent need. You'd own name-variant comparison, address normalization, coordinate tolerance, franchise-vs-duplicate logic, a confidence model for the uncertain matches, and a stable-ID scheme, and then you'd own re-running and re-tuning all of it every time the data refreshes or a new source arrives. It's weeks of work that recurs, and the output is only as durable as the identifier scheme you invent. Real, but it's a maintained service, not a script.
3. License a commercial master-data / place-data provider. Best for enterprises that want a turnkey contract and have budget. You're buying their identifiers, their match logic, and their refresh cadence, usually at enterprise pricing and locked to their schema. Good if the contract fits; heavy if you just have a list to clean.
4. Resolve your list against licensed open ground truth. Best for teams that have a dirty business list and want one canonical, stably-identified record per real place without building or maintaining the dedup. This is the category the Business Data Enricher Apify actor sits in: you bring a list (a CRM, store locations, merged scrapes you already paid for) and get back canonical records on Overture Maps data under CDLA Permissive 2.0, each with a persistent GERS ID. It's one of the few tools built for place resolution rather than just extraction. Best when the job is "make my business data trustworthy and deduplicated."
| Approach | Handles name/address variants | Stable IDs | Re-runs cleanly | Trustworthy count | Maintenance burden |
|---|---|---|---|---|---|
| Manual / spreadsheet | Inconsistently, by hand | No | No | No | Redone every time |
| In-house fuzzy build | Only if you build it | Only if you build it | Only if you maintain it | If tuned well | You own it forever |
| Commercial provider | Yes | Vendor's IDs | Yes | Yes | Vendor's, at vendor cost |
| Resolve vs open ground truth | Yes | Yes (GERS) | Yes | Yes | None (tool handles it) |
Pricing and features based on publicly available information as of June 2026 and may change. Open datasets like Overture refresh monthly and carry no reviews, ratings, or live hours, for those, a Maps scrape still wins. See the Google Maps scrapers comparison for that tradeoff.
Best practices for deduplicating business listings
Seven things I'd tell anyone whose dedup has to be trusted, not just tidy.
- Decide what "the same business" means before you start. Is a separate branch a duplicate or a distinct record? Is a closed location a duplicate of the new one? Answer this first, it's a definition problem, and getting it wrong corrupts everything downstream.
- Never dedup on a name column alone. It catches byte-identical names, which business data almost never has, while missing every real variant. A name-only pass feels productive and does close to nothing.
- Treat cross-source merges as the hard case, not the easy one. Merging a CRM and two scrapes has no shared key, so the duplicates multiply on naive concatenation. Plan for resolution before you merge, not after.
- Protect legitimate franchise branches explicitly. Aggressive dedup deletes real locations. If your rule can't tell a duplicate listing from a different branch of the same brand, it's not ready to run on a chain-heavy market.
- Match on a persistent identifier, not a scraped place ID. Scraped IDs churn and differ across sources. Resolve to a stable global ID and use that as the join key, or your re-runs will regenerate duplicates.
- Dedup before you count, score, or route. Every duplicate double-counts. Doing dedup last means every metric you computed first is wrong by the duplicate rate, and you won't know by how much.
- Check the license before deduped data touches a product. "Can I resell this" is an ingestion-time question. Resolving against a resale-permissive source like CDLA answers it upfront instead of when legal asks.
Common mistakes when deduplicating listings
Five mistakes I see constantly, each with a real cost.
- Trusting a "remove duplicates" pass. It catches exact matches only. On business data that means it deletes a handful of rows and leaves most of the real duplicates standing, while the shorter sheet convinces everyone the job is done.
- Turning fuzzy matching up until the count looks right. A count that looks right is often a count that over-merged. Aggressive fuzzy dedup quietly fuses distinct businesses and deletes franchise branches, and the damage is invisible because a bad merge looks clean.
- Concatenating sources, then deduping. Merging first and deduping after multiplies the problem, you've combined every formatting inconsistency from every source with no shared key to match on. Resolve, don't concatenate-and-hope.
- Using a scraped place ID as the match key. It changes over time and differs between sources, so the re-run can't line records up and the duplicates regenerate. An unstable ID is not a dedup key.
- Deduping once and assuming it's done. Local data decays 20-30% a year. New duplicates arrive with every refresh and every new source. Dedup is a recurring process, not a one-time cleanup.
How do you deduplicate millions of business listings?
You don't deduplicate millions of listings by scaling up a fuzzy-match script, the comparison cost and the error rate both grow faster than the row count. At that scale the reliable approach is to resolve every record against a canonical ground-truth dataset that already carries one stable entity per real place, so dedup becomes a lookup against truth rather than an all-pairs comparison you maintain.
How is deduplication different from entity resolution?
Deduplication is one outcome of entity resolution. Entity resolution is the broader discipline of deciding which records refer to the same real-world entity; deduplication is what you get when you collapse those matched records into one. At scale you can't do the dedup correctly without doing the resolution, which is why "dedup business listings" and "resolve business listings" are, past a few thousand rows, the same job.
A concrete before/after
A regional retail-scouting team I talked through this had merged a CRM, two Google Maps scrapes per metro, and a supplier list into one master sheet, then deduplicated by hand in a couple of analyst-days per refresh. The before state: a master sheet they estimated was roughly 18% duplicate rows despite the manual pass, several real franchise branches accidentally merged away, and a "businesses per metro" number nobody fully trusted.
The change was reframing the job from "merge then clean" to "resolve once." Instead of deduping the concatenated mess, they ran their inputs through resolution against licensed ground truth and got back one canonical, stably-identified record per real place. After: the duplicate rate dropped to near zero, the lost franchise branches came back as distinct records, and the per-metro count became a number they could put in a board deck. The couple of analyst-days per refresh became roughly an hour of review. Their numbers, their context, results vary with list quality and territory.
Implementation checklist
The sequence for moving from "dedup by hand" to trustworthy, repeatable resolution.
- Inventory every source. CRM, scrapes, supplier feeds, store locations, list them and note that none share a reliable key.
- Define your matching rules in words first. What counts as the same place; how franchise branches are handled; whether closures dedup against re-opens. This is a decision, not a setting.
- Measure your current duplicate rate. Before you fix anything, quantify how bad it is. You'll usually be surprised, and it gives you a baseline.
- Resolve against licensed ground truth. Run the inputs through a resolution tool like the Business Data Enricher Apify actor to get canonical, deduplicated, stable-ID'd records under a resale-safe license.
- Adopt the persistent ID as your join key. Replace any scraped or vendor place IDs with the stable global ID so future merges match instead of duplicate.
- Re-resolve on a schedule, not by hand. Because the data decays, treat resolution as a recurring run, not a one-off.
- Enrich last. If you need contacts on the clean cohort, run a contact enrichment pipeline over the deduplicated records, never over the raw duplicate rows.
Limitations
Honest constraints, because resolution isn't magic and manual dedup isn't always wrong.
- Open datasets aren't live. Overture Maps refreshes monthly and carries no reviews, ratings, or today's hours. If your use case lives on those, dedup against open ground truth won't carry them, that's an enrichment layer, not the canonical identity.
- Match confidence isn't always 100%. A names-only input with no address or coordinates resolves at lower confidence than a name plus a location. Good resolution flags the uncertain matches rather than guessing, but a sparse input list will leave a low-confidence tail to review.
- Resolution needs an input list. It cleans and canonicalizes what you bring or a territory you pull; it's not a discovery engine for "find every business that might exist." That's a different and less reliable job.
- Coverage varies by region. Open place datasets are strong in well-mapped areas and thinner in some regions, so dense urban markets resolve more completely than sparse rural ones.
- Tiny one-off lists don't need this. A few hundred clean rows you'll use once and discard are genuinely fine to dedup by hand. The case for resolution is scale, re-runs, and trust, not every list.
Key facts about business listing deduplication
- Deduplicating business listings at scale is entity resolution, a recognized data-engineering discipline, not a spreadsheet operation.
- Exact-match dedup on a name or address column almost never fires on business data, because nothing is byte-identical across sources.
- Aggressive fuzzy dedup creates invisible errors by merging distinct businesses and deleting legitimate franchise branches.
- Merging multiple sources multiplies duplicates rather than removing them, because there's no shared key to match on.
- Scraped place IDs are documented as subject to change, so they can't serve as a durable dedup or join key.
- Local business data decays roughly 20-30% per year, so duplicates regenerate every refresh and dedup is recurring, not one-time.
- Resolving against Overture Maps returns one canonical record per place with a persistent GERS ID under a resale-permissive CDLA license.
- Correct dedup is what makes "how many real businesses are in this dataset" a number you can trust.
Glossary
- Entity resolution, The data-engineering discipline of deciding which records refer to the same real-world entity.
- Deduplication, Collapsing multiple records that describe the same real-world business into one canonical record.
- Record linkage, The broader practice of matching records across datasets that refer to the same entity; entity resolution is its modern form.
- GERS ID, Overture Maps' Global Entity Reference System identifier; a persistent global fingerprint for a real-world place that stays stable across data releases.
- Canonical record, The single authoritative row chosen to represent a real-world entity after duplicates are collapsed.
- CDLA Permissive 2.0, A Community Data License Agreement license that permits redistribution and product-building on the licensed data.
Where these patterns apply beyond business listings
Listing dedup is a specific instance of a general truth about messy data, and the same patterns apply wherever you're matching records to real-world things.
- Identity must be canonical to be countable. Any "how many distinct X" question is wrong by your duplicate rate until you resolve to one record per real entity, companies, products, people, or places.
- Exact match is almost never enough. Real-world identifiers vary in spelling, format, and punctuation, so matching is a confidence problem, not an equality check, in every domain.
- False merges are worse than false splits. A surviving duplicate is visible; a wrong merge is invisible and deletes real records. Tune toward caution wherever the cost of a silent loss is high.
- Resolution is upstream, not cleanup. Counting, scoring, and joining on un-resolved rows is wrong in proportion to the mess. Resolve first, compute second.
- Stable identity is what makes data durable. Without a persistent key, every re-run and every new source regenerates the duplicates you just removed.
When you need this
You probably need resolution-grade deduplication (not a manual pass) if:
- You're merging business listings from more than one source.
- You re-run or refresh the same territories on a schedule.
- "How many real businesses are in here" has to be a trustworthy number.
- Your data has franchise brands that repeat across a city.
- You'll resell, ship, or productize the deduplicated data.
You probably don't need this if:
- You have a few hundred clean rows from one source you'll use once.
- The list is disposable and the exact count doesn't matter.
- You'll never re-run, join, or merge the data again.
Frequently asked questions
Why does removing duplicates in a spreadsheet not work for business listings?
A spreadsheet "remove duplicates" matches byte-identical rows. Business listings are almost never byte-identical across sources, names carry abbreviations, neighborhood tags, and old trading names, addresses are formatted inconsistently, and coordinates drift. So the pass deletes a few obvious doubles and leaves most real duplicates standing, while the shorter sheet makes it look finished. Correct dedup needs entity resolution, which a spreadsheet filter can't do.
How do you deduplicate business listings from multiple sources?
Merging sources first and deduping after multiplies the problem, because the sources share no reliable key and each formatted the fields differently. The durable approach is to resolve every record against a canonical ground-truth dataset that already carries one stable entity per real place, so each source's rows match to the same canonical record. That's what tools like the Business Data Enricher Apify actor do, resolution instead of concatenation.
Is deduplication the same as entity resolution?
Deduplication is one outcome of entity resolution. Entity resolution is the broader discipline of deciding which records refer to the same real-world entity; deduplication is collapsing those matched records into one. At scale you can't dedup correctly without doing the resolution, so for business listings past a few thousand rows the two are effectively the same job, which is why a "dedup script" tends to grow into a maintained system.
How do I keep franchise branches from being merged?
This is the hardest part of business dedup. Many real branches of one chain share a name and brand but are distinct places, and any rule aggressive enough to catch name variants will start merging them away. Distinguishing a duplicate listing from a different branch needs a model that weighs location and identity together, not just name similarity. Resolution against ground truth handles it by matching each branch to its own canonical entity rather than its brand.
Why can't I use the scraped place ID to deduplicate?
Google's place_id is documented as subject to change, and different sources assign different IDs to the same business anyway, so there's no shared, stable key to match on. Deduping or joining on a scraped ID means your re-runs can't line records up and the duplicates regenerate. A persistent global identifier like Overture's GERS ID is designed to stay stable, which is what a dedup key actually needs to be.
Does deduplication need to be re-run, or is it one-time?
It's recurring. Local business data decays at roughly 20-30% a year as places move, close, and rebrand, and every new source adds fresh duplicates. A one-time clean is correct only for a disposable list. Anything you maintain needs dedup as a scheduled process, which is another reason scale tilts toward resolution against ground truth over a hand pass you repeat forever.
Ryan Clinton publishes Apify actors and MCP servers as ryanclinton and builds developer tools at ApifyForge.
Last updated: June 2026
This guide focuses on business listings and Google Maps-style data, but the same resolution-over-dedup patterns apply broadly to any record-matching problem where identity has to be canonical and stable.