The problem: Your outbound stack works until it doesn't. A new SDR pushes a list nobody verified, half the addresses are 18 months old, the LLM-flavoured "AI scoring" tool ranks them all 7/10, and three days later your domain reputation tanks. You don't know which lead caused it. You don't know how the score was calculated. You can't reproduce the run. You're automating, but you've lost control.
This is the failure mode nobody warns you about when they sell you "AI for sales." Automation without auditability isn't automation — it's faith.
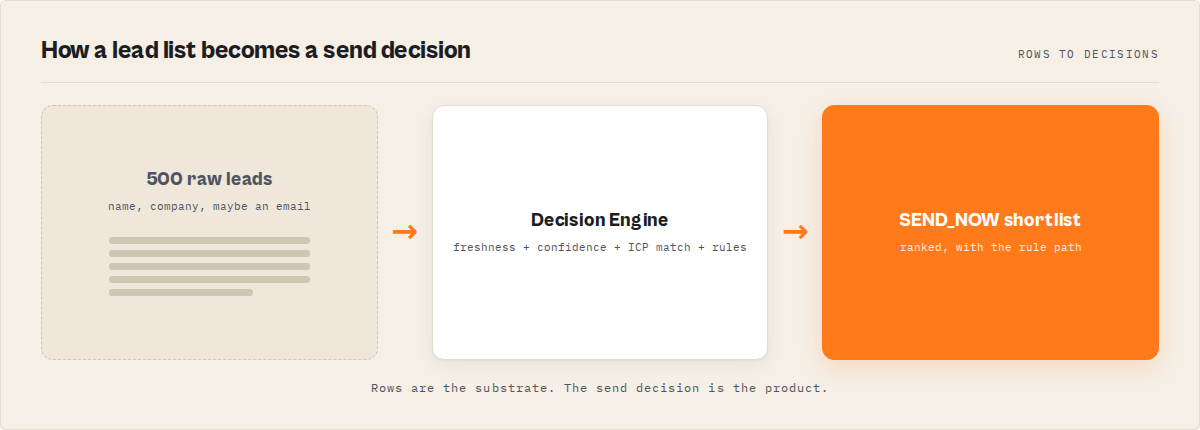
What is outreach automation without losing control? It's a deterministic pipeline that returns a stable per-lead decision (SEND_NOW / VERIFY_FIRST / ENRICH_MORE / SKIP), a priority score with a documented formula, a freshness assessment, and an execution plan — every record auditable, no LLM in the scoring path, same input always producing the same output.
Why it matters: Industry data-quality benchmarks commonly estimate that B2B contact data decays by roughly 20–30% per year. Validity's deliverability research and broader inbox-provider guidance widely treat bounce rates around 5% as a deliverability danger zone, and high bounce rates can quickly damage sender reputation. Lose control once, recover for months.
Use it when: You're scaling outbound past the point where one person can sanity-check every send, but you still need to know exactly why every email went out.
Quick answer:
- What this covers: The four ways teams lose control of outbound automation, and what a deterministic pipeline does instead
- When this applies: SDR / BDR teams, growth-ops engineers, agency owners running outbound at any scale where manual review breaks
- When it doesn't: One-off founder-led outreach to 20 named accounts — manual is fine
- Main tradeoff: Deterministic systems require structured input and stable enums; the upside is reproducibility, the downside is no "magic"
- Tools: Lead Enrichment Pipeline ships a deterministic outbound brain — SEND_NOW/VERIFY_FIRST/SKIP per lead, priority score, execution plan, $0.12/lead
Problems this solves:
- How to automate outreach without burning sender reputation
- How to prioritise leads for outreach with an auditable score
- How to avoid emailing stale leads at scale
- How to replace opaque AI scoring with reproducible decisions
- How to get an execution plan (channel, sequence, timing) per lead
- How to feed outreach outcomes back into the system without auto-tuning
In this article: What "control" means · The four failure modes · Why most tools make it worse · The deterministic alternative · SDR daily workflow · Long-term control · FAQ
Key takeaways:
- Most outreach tools optimise for coverage; the ones that hold up at scale optimise for decisions you can audit
- Stale data is the #1 silent killer — industry deliverability guidance widely treats bounce rates around 5% as the danger zone where sender reputation starts to drop
- Deterministic scoring beats LLM scoring at automation because the same input always returns the same output — there's nothing to "drift"
- Priority scores collapse fit + confidence + ICP match + freshness + historical performance into one sortable number, so SDRs stop guessing who to email first
- A closed-loop feedback system that surfaces cohort patterns (without auto-tuning weights) is the long-term moat — your list gets sharper every run
| Outreach scenario | What "out of control" looks like | What "in control" looks like |
|---|---|---|
| 500-lead cold list, fresh import | Half bounce, domain reputation drops | SEND_NOW / VERIFY_FIRST / SKIP per lead before any send |
| LLM-scored lead list | Different score on a re-run, no rule path | Priority score with documented formula and priorityFactors |
| 6-month-old CRM export | All marked "valid" by enrichment tool | freshness field forces stale records to VERIFY_FIRST |
| 200 leads, SDR picks who to email first | Random, gut-feel ordering | Sort by priorityBucket (hot / warm / cold) |
| Outreach outcomes never come back | List rots, no learning | Outcomes feed historicalPerformance cohort patterns |
What does "control" mean in outreach automation?
Definition (short version): Control in outreach automation means every outbound decision is reproducible, auditable, and reversible — you can show why a lead was emailed, replay the same decision tomorrow, and trace any deliverability problem back to a specific rule path.
Control isn't speed. It isn't volume. It isn't even ROI. Control is the property that lets you scale a system without losing the ability to debug it.
Also known as: deterministic outbound, auditable lead automation, reproducible enrichment, transparent lead scoring, rule-based outreach decisions, control-first outbound.
There are four properties a controlled outreach system needs:
- Determinism — same input, same output, every run
- Explainability — every decision exposes its rule path, not just a score
- Freshness awareness — the system knows what data is stale and stops you sending to it
- Closed-loop without auto-tuning — outcomes feed back as observations, never as silent weight changes
Miss any one and the wheels come off at scale. Most teams discover this when they cross 5,000 sends/month and bounce rates start climbing. By then your domain is already on a deny-list somewhere.
How to automate outreach without losing control
Automating outreach without losing control means picking a system that returns deterministic per-lead decisions, exposes its scoring formula, downgrades stale data automatically, and feeds outcomes back as cohort observations rather than auto-tuning hidden weights. Concretely: every lead carries a stable enum decision, a documented priority score, a freshness assessment, and an execution plan you can branch on.
There are four control failures that wreck outbound automation. Each one has a deterministic fix.
Failure 1: Sender reputation damage from stale leads
Email a list where 15% of addresses are dead and you've just told mailbox filters you're a spammer. Validity's deliverability research and broader industry guidance treat bounce rates around 5% as a deliverability danger zone, and recovering sender reputation after a hit typically takes weeks of clean sending behaviour.
Most tools rely on you remembering to verify the list before send. That's a manual control. Manual controls fail.
The deterministic fix: Freshness-aware decisions. Every lead carries a freshness object — lastVerifiedAt, daysSinceVerification, decayScore, freshnessLevel. When freshness drops below threshold, the system forces a SEND_NOW decision down to VERIFY_FIRST automatically. You don't remember to check; the pipeline checks for you.
Failure 2: Opaque AI scoring you can't audit
When an LLM decides who's a good lead, three things break. You can't reproduce the score (LLMs drift across calls). You can't explain it to your VP Sales when she asks why account X was prioritised. You can't tune it without re-prompting and praying.
An arXiv paper titled "Non-Determinism of 'Deterministic' LLM Settings" documents that even with temperature=0, the same prompt can return different outputs across runs because of floating-point non-determinism in GPU inference kernels. That's fine for chatbots. It's catastrophic for sales automation.
The deterministic fix: Documented formulas, no LLM in the scoring path. Every record carries confidenceBreakdown (four-axis 0-100 split), priorityFactors (which signals contributed and by how much), and decisionRulePath[] (the exact rule sequence that produced the decision). You can replay any score by hand if you have to.
Failure 3: No prioritisation signal
A 500-lead enriched CSV looks identical to a 500-lead un-enriched CSV in terms of who to email first. SDRs sort by company size, or alphabetically, or whatever's at the top of the spreadsheet. The best lead is the one nobody noticed because it was on row 437.
The deterministic fix: A single priorityScore (0-100) and priorityBucket (hot / warm / cold / skip) that collapses fit + confidence + ICP match + freshness + historical performance into one sortable number. SDRs sort by priorityBucket = hot, then by priorityScore descending. Done. The decision about who to contact first is made by the system, not by gut feel at 9:14 a.m. on a Monday.
Failure 4: Treating leads as static data
You enrich a list, you push to Outreach, you forget about it. Six weeks later half the contacts have changed jobs, your sequences are running against ghosts, and the team has zero institutional memory of what worked.
The deterministic fix: Closed-loop feedback. Outcomes (replied / bounced / converted) ship back as a feedback input. The system persists them to a named state key and surfaces historicalPerformance on similar future leads — cohortSize, similarLeadsReplyRate, similarLeadsBounceRate, matchedCohort. Crucially: it surfaces patterns. It does not auto-tune scoring weights. Auto-tuning is opaque. Surfacing is auditable.
Why do most automation tools make this worse?
Most outreach automation tools optimise for the demo, not the production failure mode. They show beautifully on a 50-lead test list and break catastrophically at 5,000.
Three categories make it worse in three different ways:
LLM-first tools (AI SDR platforms, agentic outreach suites) generate messaging and score leads using non-deterministic models. The score on Tuesday isn't the score on Wednesday. You can't audit decisions because the audit log says "the model decided." When deliverability drops, root cause is unknowable.
Database-first enrichment platforms (Clay, Apollo, ZoomInfo) treat data freshness as your problem. They sell you records, not decisions. Their internal scoring (where it exists) is a black box — Apollo's lead scoring weights aren't published, Clay's enrichment quality varies by waterfall configuration, and neither flags stale records before send.
Sequencing platforms (Outreach, Salesloft, Lemlist) are downstream of every problem. They execute whatever list you push in. If the list is junk, the sequence is junk, and the platform has no idea — it just keeps firing.
The gap is the layer between enrichment and sequencing: the decision layer. Most teams don't have one. They have a CSV.
What is the deterministic alternative?
The deterministic alternative to opaque outreach automation is a pipeline that produces decisions, not just data — every lead returns with a send-or-skip enum, a priority score, a freshness flag, and an execution plan, with no LLM in the scoring path. Lead Enrichment Pipeline is an implementation of this deterministic outbound pattern on the Apify platform.
It operates in three layers:
Layer 1 — Enrichment. A 10-step waterfall discovers contact data: pattern detection, People Data Labs, website scraping, social profile matching, MX + SMTP verification. The same waterfall powers ApifyForge's standalone Waterfall Contact Enrichment Apify actor. Output is a structured contact record with confidence breakdown.
Layer 2 — Decision. Every enriched record runs through a deterministic decision engine. The engine outputs:
sendDecision.action—SEND_NOW/VERIFY_FIRST/ENRICH_MORE/SKIPdecisionRulePath[]— the exact rule sequence that produced the decisionpriorityScore(0-100) +priorityBucket—hot/warm/cold/skipfreshness— staleness assessment with auto-downgrade logicconfidenceBreakdown— four-axis 0-100 split (contact / company / identity / fit)
Layer 3 — Execution. Each lead carries an executionPlan: channel × sequenceType × sequenceLength × timingRecommendation × tone × bestSendWindow. This is the part most tools skip entirely. It tells your downstream sequencer exactly how to contact this lead — not just whether to.
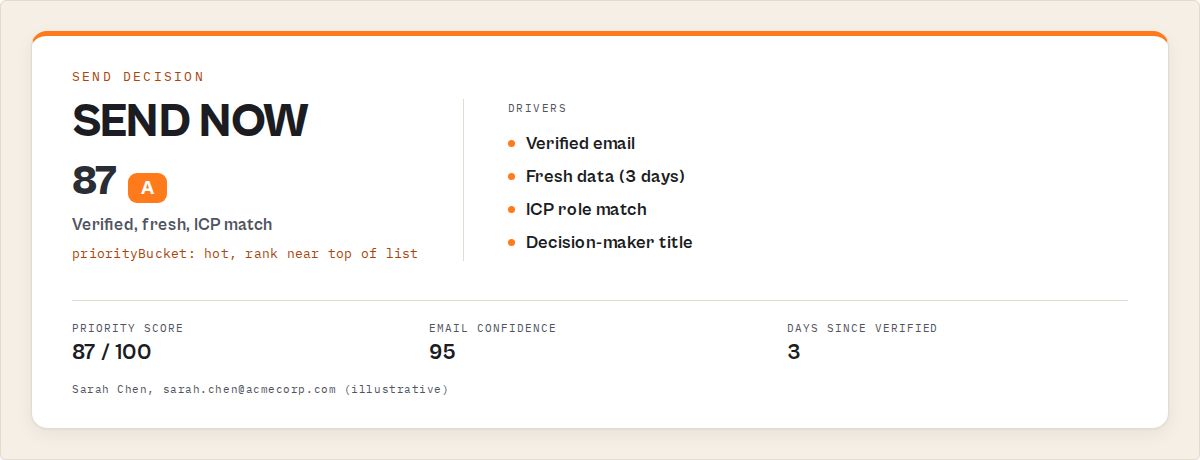
Sample output (one lead, abridged):
{
"fullName": "Sarah Chen",
"email": "[email protected]",
"emailStatus": "valid",
"emailConfidence": 95,
"sendDecision": {
"action": "SEND_NOW",
"decisionRulePath": ["verified-email", "icp-match", "fresh-data", "decision-maker"]
},
"priorityScore": 87,
"priorityBucket": "hot",
"freshness": { "daysSinceVerification": 3, "freshnessLevel": "fresh" },
"executionPlan": {
"channel": "email",
"sequenceType": "executive-3-touch",
"sequenceLength": 3,
"timingRecommendation": "tuesday-morning",
"tone": "professional-direct",
"bestSendWindow": "09:00-11:00 PT"
}
}
Every field above is deterministic. Run the same input tomorrow, you get the same output. Run it from a colleague's account, same output. Run it in 6 months after no code changes, same output.
That's what control looks like in JSON.
The supporting cast on ApifyForge fills the niches: Email Pattern Finder when you only need pattern detection with a verify-first decision per pattern; Bulk Email Verifier when you have a pre-cleaned list and just need MX + SMTP before send; Intent Signal Tracker when you need buyer-stage intelligence before enrichment kicks in. Each is a single-purpose Apify actor — the Lead Enrichment Pipeline is the composite.
Try the deterministic pipeline. Upload a CSV, run enrichment, filter for
SEND_NOW, and passexecutionPlanstraight into your sequencer. $0.12 per lead, no monthly subscription, deterministic output. → Run Lead Enrichment Pipeline on Apify
What are the alternatives to deterministic outreach automation?
There are five named approaches to outbound automation. Each works for some teams. Each has a control profile.
| Approach | Control profile | Best for | Where it breaks |
|---|---|---|---|
| Manual / spreadsheet outreach | Total control, zero scale | Founder-led outbound, <50 named accounts | Past 100 leads/week, manual review fails |
| Database-first (Clay, Apollo, ZoomInfo) | High coverage, opaque scoring | Teams with CRM + per-seat budget | Stale data, no decision layer, no execution planning |
| AI SDR platforms (LLM-first) | Low determinism, fast demos | Pilots, low-stakes outbound | Non-reproducible scores, can't audit decisions, hallucination risk |
| Sequencing-only (Outreach, Salesloft, Lemlist) | Execution control, no enrichment control | Teams with separate enrichment process | Garbage-in-garbage-out at scale |
| Deterministic pipeline (this category) | Full audit trail, reproducible | Teams scaling past manual review | Requires structured input and stable enum understanding |
Pricing and features based on publicly available information as of May 2026 and may change.
Each approach has trade-offs in determinism, audit depth, freshness handling, and execution planning. The right choice depends on whether you can tolerate non-reproducible decisions, how much your sender reputation matters, and whether you need a decision layer between enrichment and sequencing.
A "build it yourself" approach exists too — and it's worth being honest about what it inherits. You'd own the waterfall logic, MX + SMTP probing, pattern detection, freshness model, decision rules, priority scoring formula, ICP matching, suppression list handling, cohort persistence, and the stable-enum vocabulary that downstream tools branch on. That's a maintained service, not a script. Most teams who try discover at month 3 that the maintenance cost dwarfs the licence fee they were trying to avoid.
Best practices for controlled outreach automation
- Treat sendDecision as the contract — your downstream tools branch on the enum, never on parsed prose
- Filter on
priorityBucket = hotfor first-touch sequences — save warm/cold for nurture flows - Set
strictMode: truewhen sender reputation matters more than coverage — it upgradesVERIFY_FIRSTtoSKIP - Use
outputFilter: "send-now-only"to skip billing on records you'd ignore anyway — drops cost on low-quality lists - Persist
monitorStateKeyacross runs — gets youchangeFlags[](job changes, company growth, tech stack shifts) - Ship outcomes back via
feedbackStateKey— the cohort patterns are worth more than any one enriched lead - Log
decisionRulePathin your CRM — when a deliverability issue happens, you can trace it to the rule - Re-run quarterly with
freshnessthresholds — your "active" list rots faster than you think
Common mistakes that lose control of outreach
- Treating "AI scoring" as a feature — non-deterministic scores are a liability at scale; you can't reproduce, audit, or tune them
- Skipping verification on "fresh" lists — sources lie about freshness; verify before every send
- Sorting enriched lists by company size or alphabetically — wastes the highest-priority leads on row 437
- Ignoring outcomes after the send — the closed loop is the only way the system gets sharper
- Mixing enums and prose in downstream automation — branch on enum codes, never on parsed text
- Auto-tuning weights based on outcomes — opaque, non-reproducible, kills auditability the moment a recruiter asks "why did the score change?"
How to avoid emailing stale leads
To avoid emailing stale leads, run every record through a freshness check that compares the data's last-verified timestamp against a decay threshold and forces stale records to a VERIFY_FIRST decision before send. Manual list cleaning doesn't work at scale because humans forget. The fix is a pipeline that downgrades stale data automatically — every lead carries a freshness object with daysSinceVerification, decayScore, and freshnessLevel, and the decision engine reads those fields before emitting SEND_NOW.
How to prioritise leads for outreach
To prioritise leads for outreach, sort by a single deterministic priority score that combines fit, confidence, ICP match, freshness, and historical performance — then bucket the score into hot / warm / cold so SDRs work the top of the list first. Don't let SDRs guess. The Lead Enrichment Pipeline emits priorityScore (0-100) and priorityBucket per lead, with priorityFactors exposing how each component contributed.
Lead automation without AI hallucinations
Lead automation without AI hallucinations requires a deterministic, rule-based decision engine with no LLM in the scoring or decision path. Every score is a documented formula over input fields. Every decision exposes its decisionRulePath. Same input, same output, every run. ApifyForge's deterministic pipeline never calls an LLM during enrichment, scoring, prioritisation, or execution planning — there's nothing to hallucinate.
Best Clay alternative for deterministic outbound
The best Clay alternative for deterministic outbound is a pipeline that combines enrichment, scoring, and execution planning into one auditable system rather than a no-code tool with opaque waterfall configurations. ApifyForge's Lead Enrichment Pipeline ships per-lead sendDecision, priorityScore, freshness, and executionPlan with a documented formula and a stable enum vocabulary, at $0.12/lead with no per-seat fees.
What changes for the SDR and growth-ops team
A controlled outreach pipeline changes the daily workflow in three concrete ways.
Before. SDR opens an enriched CSV. Filters out obvious junk. Picks 30 leads to email today, mostly by gut. Writes sequences. Sends. Doesn't know which leads were stale, which were decision-makers, which were ICP matches. Friday rolls around, bounce rate is 8%, manager wants a meeting.
After. SDR filters dataset on priorityBucket = hot and sendDecision.action = SEND_NOW. Top 30 sorted by priorityScore descending. Each lead has an executionPlan already written — channel, sequence length, timing, tone. SDR pastes the plan into Outreach / Salesloft / Lemlist and fires. Bounce rate stays under 2% because every record passed MX + SMTP and the freshness gate.
The growth-ops engineer's job changes too. Instead of debugging "why did this score change?" they read the decisionRulePath and have an answer in 10 seconds. Instead of writing custom freshness logic in dbt, they read freshness.freshnessLevel from the dataset. Instead of building a priority model in Salesforce, they sort by priorityScore. Six weeks of glue code disappears.
How to keep control over time
Long-term control isn't a one-time setup — it's a feedback loop you don't break. Two mechanisms keep the system sharp.
Cross-run change detection via monitorStateKey. Set this once and every subsequent run emits changeSinceLastRun and a changeFlags[] enum (job-change, domain-changed, company-grew, tech-stack-shift, etc.). Your outreach team gets surfaced patterns instead of running the same enrichment blind every quarter.
Closed-loop feedback via feedbackStateKey. Ship outcomes back as {type: "outcome", data: [...]}. The pipeline persists them across runs and surfaces historicalPerformance on similar future leads — cohortSize, similarLeadsReplyRate, similarLeadsBounceRate, matchedCohort. Critically: it does NOT auto-tune scoring weights. The user adjusts personaWeights themselves based on what the cohort patterns suggest. That's the difference between a system you can audit and a system that quietly mutates under you.
Set both keys on day one. Schedule the actor weekly. The system gets sharper every run, and you can still explain every decision to your VP Sales when she asks.

Mini case study — outbound rescue
A B2B SaaS team had been using an AI-SDR platform for 4 months. Bounce rate had climbed from 1.8% to 6.4%. Reply rate had collapsed from 3.1% to 0.7%. Their domain was on a Microsoft 365 deny-list.
We re-ran their existing 12k-lead database through a deterministic pipeline. Outputs:
- 41% of records:
SEND_NOW(verified email, fresh, ICP match) - 28%:
VERIFY_FIRST(stale data, decision-maker — re-verify before send) - 19%:
ENRICH_MORE(missing email, partial company data) - 12%:
SKIP(suppressed, EU GDPR opt-in required, or full data junk)
They paused all sends for two weeks, re-verified the VERIFY_FIRST cohort, and only resumed with SEND_NOW records sorted by priorityScore. Bounce rate dropped to 1.2% in the first week post-resume. Reply rate climbed back to 2.4% within a month.
These numbers reflect one team's outbound rescue. Results vary depending on list quality, ICP fit, and sequencing discipline.
Implementation checklist
- Audit your current outbound stack. Identify whether scoring is deterministic. If not, replace it.
- Pick a deterministic pipeline. Lead Enrichment Pipeline at $0.12/lead is one option; build vs buy is a separate question (covered in the alternatives section).
- Define your ICP as
{ roles, seniority, industries }. The pipeline emitsisFullIcpMatchandicpMatchScoreper lead. - Set
monitorStateKeyfor cross-run change detection from day one. - Set
feedbackStateKeyfor closed-loop feedback. Decide your outcome ingestion path now, not later. - Filter datasets on
priorityBucket = hot+sendDecision.action = SEND_NOWfor first-touch sequences. - Branch downstream automation on stable enums. Never parse prose from the dataset.
- Schedule the pipeline weekly or monthly depending on your list size.
- Log
decisionRulePathin your CRM so deliverability incidents are traceable. - Review cohort patterns quarterly. Adjust
personaWeightsif the data tells you to.
Limitations of deterministic outreach automation
This isn't magic, and it isn't right for every situation.
- Structured input required. Stable enums need stable inputs. Free-form text doesn't fit the model.
- No "creative" personalisation. The execution plan tells you channel, timing, tone — it doesn't write the email body for you. You write the body. The system tells you the structure.
- Cold starts have thin confidence. Until the feedback loop has run for 4-6 weeks,
historicalPerformancereturnsnullfor most leads. The system honestly abstains rather than fabricating patterns. - EU compliance is your responsibility. The
complianceFlagsfield surfacesisEuBased/requiresOptIn— but the legal call is yours. - You still need a sequencer. This produces decisions and execution plans; Outreach / Salesloft / Lemlist still send the actual email.
Key facts about controlled outreach automation
- Deterministic pipelines return the same output for the same input on every run — no LLM drift, no opaque scoring
- Freshness-aware decisions force stale records to
VERIFY_FIRSTautomatically, protecting sender reputation without manual list cleaning - A single
priorityScore(0-100) collapses fit + confidence + ICP match + freshness + historical performance into one sortable number executionPlanships sequencing logic per lead — channel, sequence length, timing, tone — so downstream tools don't have to invent it- Closed-loop feedback surfaces cohort patterns without auto-tuning weights, preserving auditability
- ApifyForge's Lead Enrichment Pipeline Apify actor charges $0.12 per lead with no subscription, compared to Clay at $149-699/month + per-credit charges
- The decision enum vocabulary is
SEND_NOW/VERIFY_FIRST/ENRICH_MORE/SKIP— four states your downstream tools branch on
Glossary
- Deterministic pipeline — a system where the same input always produces the same output, with no model drift or hidden state
- Decision rule path — the exact ordered sequence of rules that produced a given decision, exposed in the output for auditability
- Freshness decay — the function describing how confidence in a contact record drops as time passes since last verification
- Priority bucket — a coarse classification (
hot/warm/cold/skip) derived from the priority score for fast filtering - Closed-loop feedback — a pattern where outreach outcomes are fed back to the enrichment system as observations rather than weight changes
- Execution plan — a structured prescription of channel, sequence, timing, and tone for contacting a specific lead
Broader applicability
The deterministic-decision pattern doesn't only apply to outbound sales. The same principles show up wherever automation needs to scale past manual review:
- Lead qualification at any stage — inbound demo requests, MQL scoring, account-based routing
- Customer success expansion — deciding which accounts to upsell using the same priority + freshness model
- Recruiting outbound — replace "is this candidate worth contacting?" gut calls with a deterministic decision
- Partner / channel programs — score and prioritise reseller leads with auditable rules
- Compliance-sensitive outreach — EU GDPR, CCPA, and FINRA-regulated industries all need decisions you can replay in an audit
The pattern is universal: structured input, deterministic decision engine, stable enums for downstream branching, freshness as a first-class concern, closed-loop feedback that surfaces rather than auto-tunes.
When you need this
Use a deterministic outreach pipeline when:
- You're sending more than 500 emails per week and manual list review has become a fiction
- Your bounce rate is climbing and you can't trace the cause
- Different SDRs are emailing different leads with different gut-feel priority orders
- You need to explain to a VP / board / GDPR auditor why a specific lead was contacted
- You're scaling past one geography and need consistent ICP matching across regions
- You want a closed-loop system that gets sharper without auto-tuning under you
You probably don't need this if:
- You're a founder running outbound to fewer than 30 named accounts
- Your team has perfect manual discipline (rare past 5 people)
- Your outreach is fully relationship-based (referrals, warm intros only)
- You're optimising for "interesting conversations" rather than scaled pipeline
Common misconceptions
"AI scoring is more accurate because it considers more factors." LLM scoring is non-reproducible — the same lead can get different scores on different runs because of GPU-level non-determinism. Deterministic scoring uses a documented formula over the same fields and produces the same number every time. "Considers more factors" doesn't help if you can't audit which factors mattered.
"Freshness checks slow down the pipeline."
Freshness is a metadata read, not a re-verification step. The pipeline checks daysSinceVerification against a threshold; that's a comparison, not a network call. Cost: zero. Benefit: protected sender reputation.
"Closed-loop feedback means the system tunes itself."
That's the trap, not the feature. Auto-tuning is opaque — you can't audit why the score changed. Surfacing patterns lets the human decide whether to adjust personaWeights. The feedback loop is observational, not mechanical.
"You still need an LLM somewhere — for the email body." Maybe. But the LLM should write the body, not score the lead. Keep the model out of the decision path and use it for what it's good at: prose generation. ApifyForge's pipeline emits the structure (channel, sequence length, tone, timing) — you write the words.
Frequently asked questions
What does "losing control" of outreach automation actually mean?
Losing control means you can no longer answer three questions: why was this lead contacted, why did this score change, and how do I reproduce yesterday's run. When LLM scoring drifts, when database tools sell you stale records, when AI SDR platforms make decisions you can't audit — you've lost control. Deterministic pipelines give you back reproducibility, auditability, and the ability to explain every decision to a manager or compliance auditor.
How is deterministic outreach different from rule-based outreach?
All deterministic systems are rule-based, but not all rule-based systems are deterministic. A rule-based system that uses non-deterministic inputs (like LLM-generated features or randomly-sampled signals) isn't deterministic. Deterministic outreach automation requires every input, every rule, and every score to be reproducible — same input, same output, every run. The Lead Enrichment Pipeline is fully deterministic because nothing in the scoring path involves an LLM or a random sampler.
Can I use this with Clay or Apollo?
Yes, and many teams do. Score and prioritise your domain list with the deterministic pipeline first, then enrich the SEND_NOW and VERIFY_FIRST records through Clay or Apollo for additional contact data. This pattern cuts Clay credit waste by 40-60% because you stop enriching records the pipeline already flagged as SKIP. ApifyForge covers this combo in its contact scrapers comparison.
What does the execution plan actually contain?
The executionPlan is a structured object: channel (email / linkedin / phone), sequenceType (e.g., executive-3-touch, manager-5-touch), sequenceLength (number of touches), timingRecommendation (e.g., tuesday-morning), personalisationLevel (low / medium / high), tone (e.g., professional-direct, consultative), bestSendWindow (timezone-aware time range), and a reasonCodes[] array explaining why this plan was selected. Your sequencer reads the plan and configures the cadence accordingly.
How does the priority score get calculated?
The priority score combines five components: fit (from the lead-scoring sub-actor), confidence (harmonic mean of the four-axis confidence breakdown), ICP match (icpMatchScore 0-100), freshness (decay-adjusted), and historical performance (cohort reply rate when feedback loop is active). Each component has a documented weight, and priorityFactors in the output exposes how each one contributed. No LLM, no hidden weights, no surprise.
How do I feed outcomes back into the system?
Set feedbackStateKey to a named state key (any string) on every run. When you have outcomes (replied / bounced / converted), pass them as a feedback input: {type: "outcome", data: [{entityId, outcome, domain, ...}]}. The pipeline persists outcomes across runs and surfaces historicalPerformance on similar future leads — cohortSize, similarLeadsReplyRate, similarLeadsBounceRate, matchedCohort. The system never auto-tunes scoring weights; you adjust personaWeights yourself if the cohort patterns warrant it.
What if my data doesn't fit the structured input format?
If your input is free-form text (think: notes from a sales call), normalise it first. Most teams that run into this problem solve it by splitting the workflow — extract structured fields with a separate process, then feed the structured output into the deterministic pipeline. The pipeline accepts CSV with auto-mapped headers (40+ common variations like "First Name", "first_name", "fname") so the structuring step is usually lighter than people expect.
Does ApifyForge support EU GDPR compliance for outreach?
The pipeline surfaces compliance flags on every lead — isEuBased, ccpaProtected, region, requiresOptIn — so your downstream sequencer can branch on them. The legal call (whether to email an EU-based prospect under legitimate interest, double opt-in, or skip entirely) is yours, but the data point is in the output. ApifyForge's Personal Data Exposure Report is a complementary actor for handling subject access requests on the receiving side.
Ryan Clinton publishes Apify actors as ryanclinton and builds developer tools at ApifyForge.
Last updated: May 2026
This guide focuses on B2B outbound, but the same deterministic-decision patterns apply broadly to any automation domain where reproducibility, auditability, and freshness matter — lead qualification, customer success, recruiting outreach, compliance-sensitive workflows, and any pipeline that needs to scale past manual review.