OpenAlex Research Radar — Impact, Funders & Competitors is an Apify actor on ApifyForge. Understand a research field in one run: landmark and rising papers by field-normalized impact (FWCI), the institution and funder graph, who's winning, and where the opportunities are. It costs $0.002 per paper-fetched. Best for investigators, analysts, and risk teams conducting due diligence, regulatory tracking, or OSINT research. Not ideal for real-time surveillance or replacing classified intelligence systems. Maintenance pulse: 90/100. Last verified March 27, 2026. Built by Ryan Clinton (ryanclinton on Apify).
OpenAlex Research Radar — Impact, Funders & Competitors
OpenAlex Research Radar — Impact, Funders & Competitors is an Apify actor available on ApifyForge at $0.002 per paper-fetched. Understand a research field in one run: landmark and rising papers by field-normalized impact (FWCI), the institution and funder graph, who's winning, and where the opportunities are. Deterministic research intelligence, not raw rows.
Best for investigators, analysts, and risk teams conducting due diligence, regulatory tracking, or OSINT research.
Not ideal for real-time surveillance or replacing classified intelligence systems.
What to know
- Limited to publicly available and open-source information.
- Report depth depends on the availability of upstream government and public data sources.
- Requires an Apify account — free tier available with limited monthly usage.
Maintenance Pulse
90/100Cost Estimate
How many results do you need?
Pricing
Pay Per Event model. You only pay for what you use.
| Event | Description | Price |
|---|---|---|
| paper-fetched | Charged per research record retrieved from OpenAlex. | $0.002 |
Example: 100 events = $0.20 · 1,000 events = $2.00
Documentation
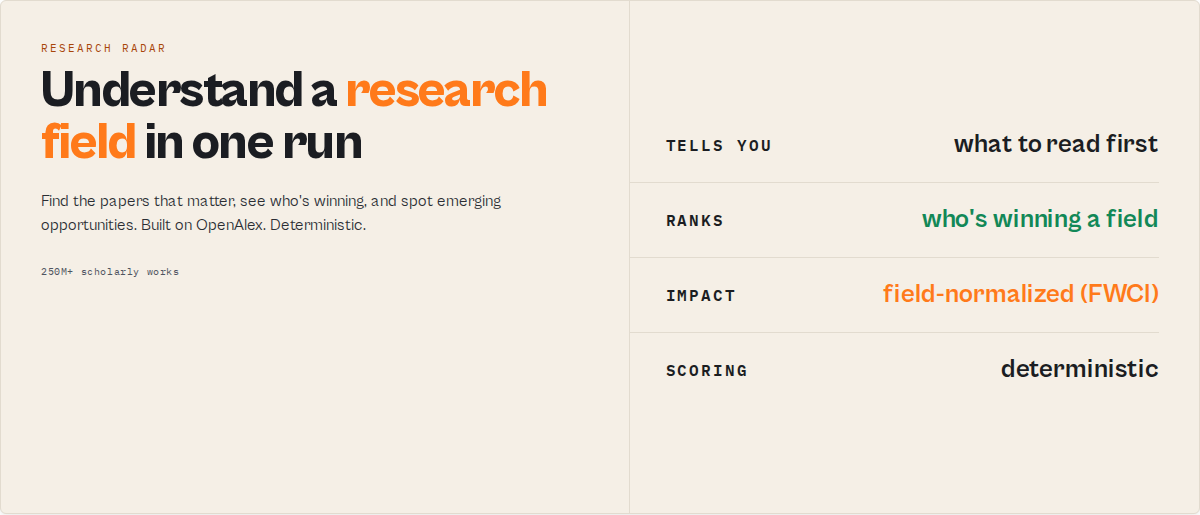
Understand a research field in one run. Point this actor at any topic and get back the landmark papers, the rising papers, the leading institutions, the dominant funders, the emerging opportunities, the competitive landscape, and the research risks behind it. Built on OpenAlex (250M+ scholarly works), fully deterministic, no LLMs.
It answers the question every OpenAlex wrapper leaves you with: "I got 10,000 papers, now what?" Instead of rows, you get decisions: which work is genuinely high-impact for its field, who is winning the field, where it's growing, and which papers are safe to read or cite first -- as structured JSON your agent, dashboard, or workflow can branch on.
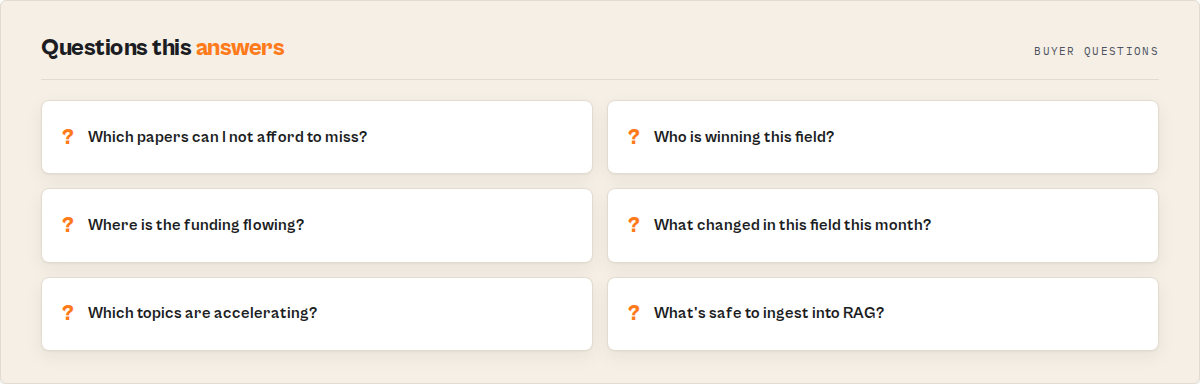
Questions this actor answers
- Which papers can I not afford to miss?
- Who is winning this field, and which institutions are emerging?
- Where is the funding flowing?
- What topics are accelerating, and which are mature or declining?
- Which opportunities are high-growth-low-competition or underfunded-but-high-impact?
- Which papers are safe to ingest into a RAG corpus?
- What changed in this field since last month?
Best for
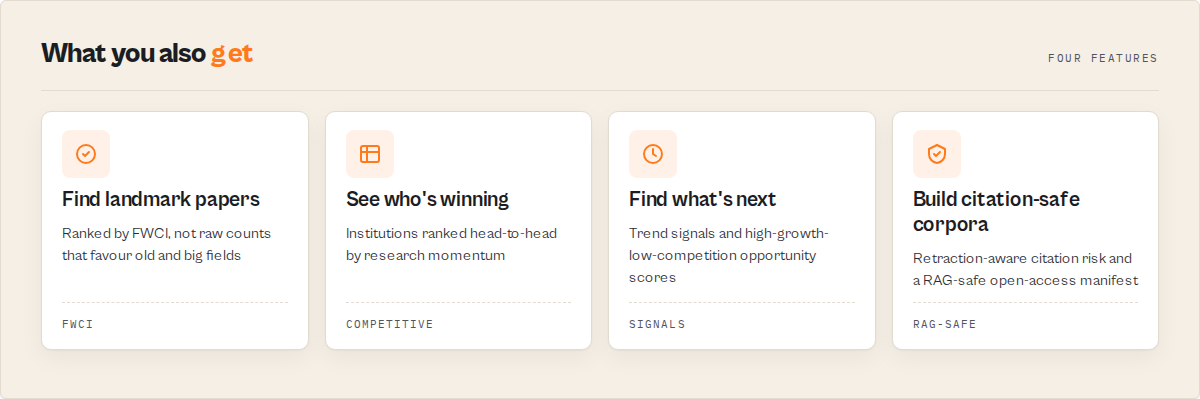
- Find the papers that matter, not just the papers that are old -- landmark and rising work ranked by impact normalized for its field.
- Map a field -- the leading institutions, countries, and funders, and how it's growing.
- See who's winning -- institutions ranked head-to-head by research momentum, with a market-map of leaders, challengers, and emerging players.
- Find where the opportunities are -- high-growth, low-competition and underfunded-high-impact areas, surfaced as deterministic signals.
- Spot what's breaking out -- young, fast-accelerating papers before their citation counts catch up.
- Monitor research shifts -- scheduled runs that surface what's new, rising, or retracted.
- Build a citation-safe / open-access corpus -- a RAG-ready manifest with retracted work excluded.
The engine underneath leans on FWCI, OpenAlex's field-weighted citation impact; the "Why this is different" section explains it. Every score is deterministic, so the same query returns the same intelligence every run.
Ready-to-run examples
One-click, pre-configured runs (edit the query and go):
- Find landmark research papers in any field -- top work ranked by field-normalized impact (FWCI), not raw citations.
- Find rising and breakout research papers -- young papers accelerating before their citation counts catch up.
- Map a research field: institutions, funders and topics -- the institution / funder / topic graph and growth behind a field.
- Build a citation-safe RAG corpus -- open-access, retraction-checked papers ready to ingest.
- Triage research papers: what to read, cite or skip -- every paper scored must-read / read / scan / skip.
- Compare research institutions head-to-head -- rank institutions by research momentum to see who's winning a field.
- Find emerging research topics and opportunities -- topic growth, trends, and high-growth-low-competition openings.
- Monitor a research field for changes -- scheduled runs that surface new, rising, and retracted work since last run.
- Who is winning a research field -- discover the leading institutions in a field, ranked by research momentum.
- Research funding landscape -- the funders behind a field, ranked by works funded and the impact of that work.
See all on the examples page.

Why this is different
Raw citation counts reward old papers and big fields. Field-weighted citation impact (FWCI) normalizes for both: a 50-citation pure-maths paper can outrank a 500-citation computer-science paper because FWCI compares each work against others in its own field and year. This actor leads with that signal -- the thing a "sort by citations" tool structurally cannot tell you -- and with the scientometric graph (institutions, countries, authors, funders) that turns "a list of papers" into "a map of who does this research, where, and on whose money."
Which academic-search actor should I use?
This actor owns the bibliometric / scientometric lane: field-normalized impact and the institution / author / funder / concept graph across all of scholarship. Reach for a sibling when your question is shaped differently:
| Your question | Use |
|---|---|
| How impactful is this work for its field, and who / where / what-funding drives the area? | This actor (OpenAlex) |
| Just give me the single decision / answer for a research question | Semantic Scholar Research Intelligence |
| Compress clinical papers into evidence units and grade the evidence | PubMed Evidence Search |
| Bulk metadata with BibTeX / OA / retraction flags from a DOI list | Crossref Academic Paper Search |
| Is this preprint safe to cite, and does it have code? | arXiv Preprint Intelligence |
What this actor surfaces that the siblings structurally can't: the institution graph (ROR IDs + country codes + type), the author graph (ORCID coverage), the funder graph, and the full concept hierarchy (topic → subfield → field → domain) -- scored and ranked across the whole corpus, then handed to you as decisions (must-read / read / scan / skip) a downstream Dify, n8n, or agent node branches on without parsing prose.
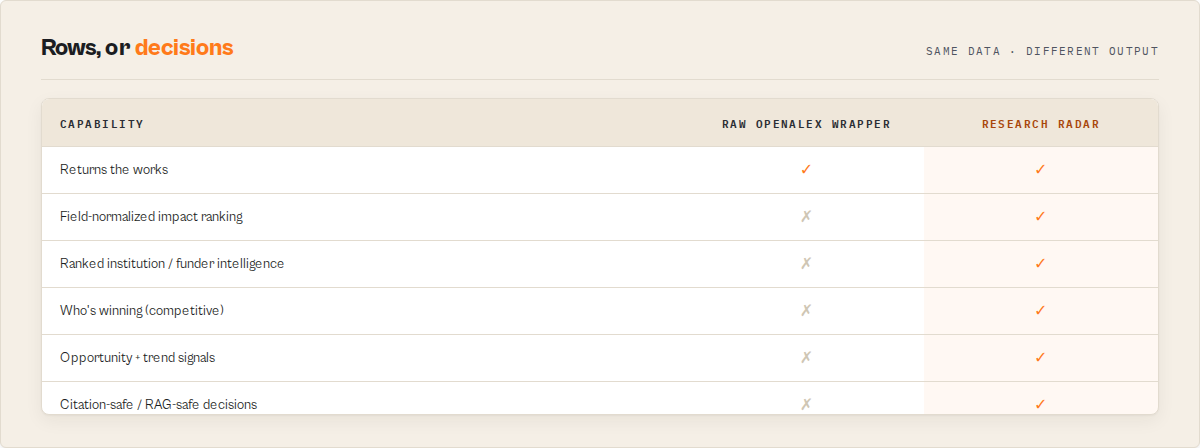
What you get from one call
Records are grouped by job (each carries a recordType). Read the brief first; reach for the rest when you need them.
Research intelligence -- understand the field
research-brief-- the hero synthesis: canonical topic, executive summary, key findings, must-read papers, ordered reading list, suggested next queries, confidence read.research-landscape-- field / concept distribution, institution and country leaderboards, funder landscape, OA profile, impact distribution, timeline, maturity, honest gaps.field-benchmark-- median FWCI vs the 1.0 field baseline, share beating the field, top-1% / top-10% counts, overperformers, under-cited-but-rising.paper-- one per work: impact class, dual-axis scores, momentum, emergence class, OA status, integrity + citation-risk, confidence + caveats, the entity graph, and a recommendation.
Research signals -- what's growing and where the openings are
trend-signal-- topic-growth class (exploding / growing / steady / declining) from true field-level volume.opportunity-signal-- deterministic, methodology-on-the-record heuristics: high-growth-low-competition, underfunded-high-impact.research-delta-- monitor mode: what's new, rising, or retracted since the last run, with the alerts that triggered.
Competitive intelligence -- who's winning
institution-comparison-- institutions ranked head-to-head by research momentum, each with dominant + emerging topics and a named leader.market-map-- institutions and countries placed in a leaders / challengers / emerging / niche quadrant with volume and impact percentiles.
Entity intelligence -- the graph behind the field
topic-profile-- maturity stage, real growth + velocity + trajectory, leading countries / institutions / funders, citation concentration, adjacent topics.institution-profile/funder-profile/author-profile/source-profile-- each entity's footprint in the result set, plus acollaboration-networkinsight (density, dominant + bridge institutions).search-plan/summary-- the interpreted query (filters, counts) and run-level headline metrics (mirrored to theSUMMARYkey-value record).
Key-value exports: SUMMARY, RESEARCH_BRIEF, RESEARCH_LANDSCAPE, FIELD_BENCHMARK, QUERY_AUDIT, and RAG_MANIFEST (citation-safe open-access subset) on every run; GRAPH_NODES / GRAPH_EDGES (for Gephi / Neo4j / Cytoscape) and BIBTEX_EXPORT / RIS_EXPORT when opted in; TOPIC_PROFILE, MARKET_MAP, INSTITUTION_COMPARISON when those modes run.
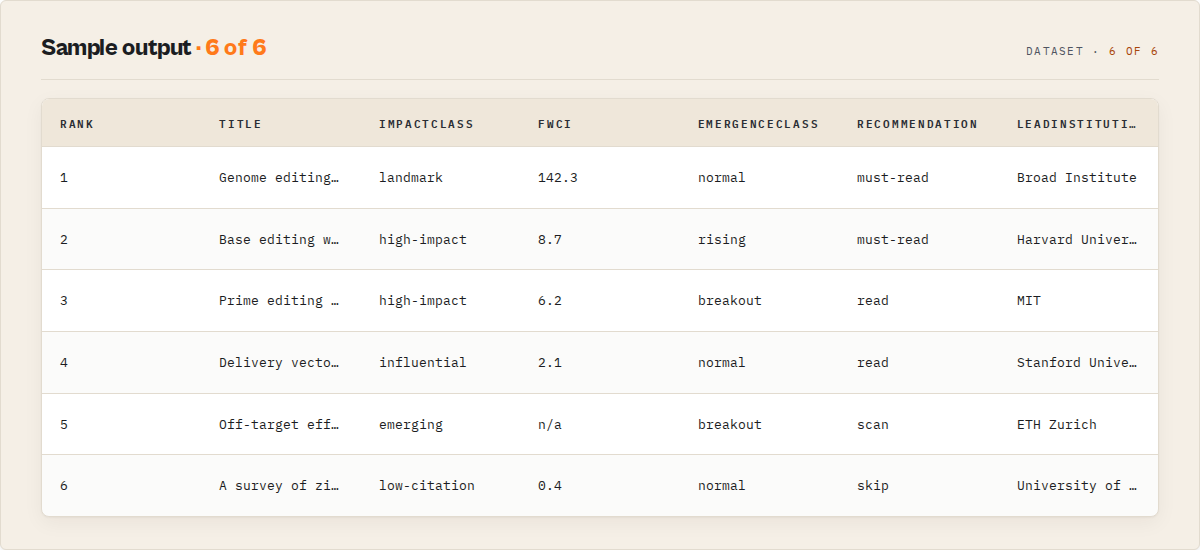
Sample output
Research brief (the record most users read first):
{
"recordType": "research-brief",
"headline": "CRISPR Gene Editing -- 100 papers, mature field, high confidence",
"mustRead": [
{ "title": "Multiplex genome engineering using CRISPR/Cas systems", "impactClass": "landmark", "fwci": 142.3, "oa": true }
],
"confidence": { "level": "high", "explanation": "100 papers analysed and 78% carry a field-normalized impact signal." }
}
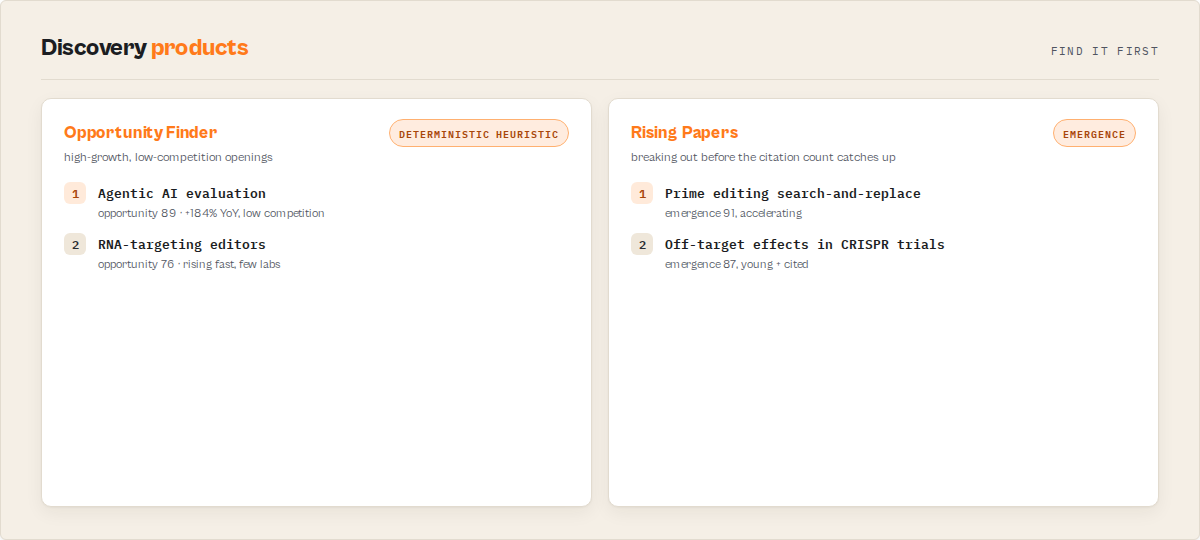
Opportunity signal:
{
"recordType": "opportunity-signal",
"signalType": "high_growth_low_competition",
"topic": "Agentic AI evaluation",
"growthScore": 92, "competitionScore": 41, "opportunityScore": 89,
"methodology": "growthScore = clamp(50 + YoY %); competitionScore = log10(field works) x 16.7; opportunityScore = growth x 0.6 + (100 - competition) x 0.4.",
"limitations": "Deterministic heuristic, not a forecast."
}
Rising paper (the breakout the citation count hasn't caught up to yet):
{
"recordType": "paper",
"title": "Toolformer: Language Models Can Teach Themselves to Use Tools",
"emergenceClass": "breakout",
"emergenceScore": 91,
"citationMomentum": "accelerating",
"recommendation": "must-read"
}
Topic profile:
{
"recordType": "topic-profile",
"topic": "Large Language Model Agents",
"maturityStage": "growth",
"publicationGrowthYoYPct": 184,
"trajectory": { "direction": "accelerating", "confidence": "high" },
"leadingInstitutions": [ { "name": "Stanford University", "papers": 9 } ]
}
Market map (quadrants are deterministic and fully auditable -- every entry carries its volume and impact percentile):
{
"recordType": "market-map",
"institutions": [
{ "name": "Massachusetts Institute of Technology", "works": 14, "avgImpact": 71, "volumePercentile": 96, "impactPercentile": 88, "quadrant": "leader" }
]
}
Research delta (monitor mode, what changed since last run):
{
"recordType": "research-delta",
"newPaperCount": 23,
"newHighImpactCount": 4,
"risingPaperCount": 11,
"triggeredAlerts": ["new_high_impact", "citation_breakout"]
}
Institution comparison (competitive mode):
{
"recordType": "institution-comparison",
"leader": "Massachusetts Institute of Technology",
"ranking": [
{ "rank": 1, "name": "Massachusetts Institute of Technology", "researchMomentum": 84, "works": 50, "highImpactShare": 0.42 }
]
}
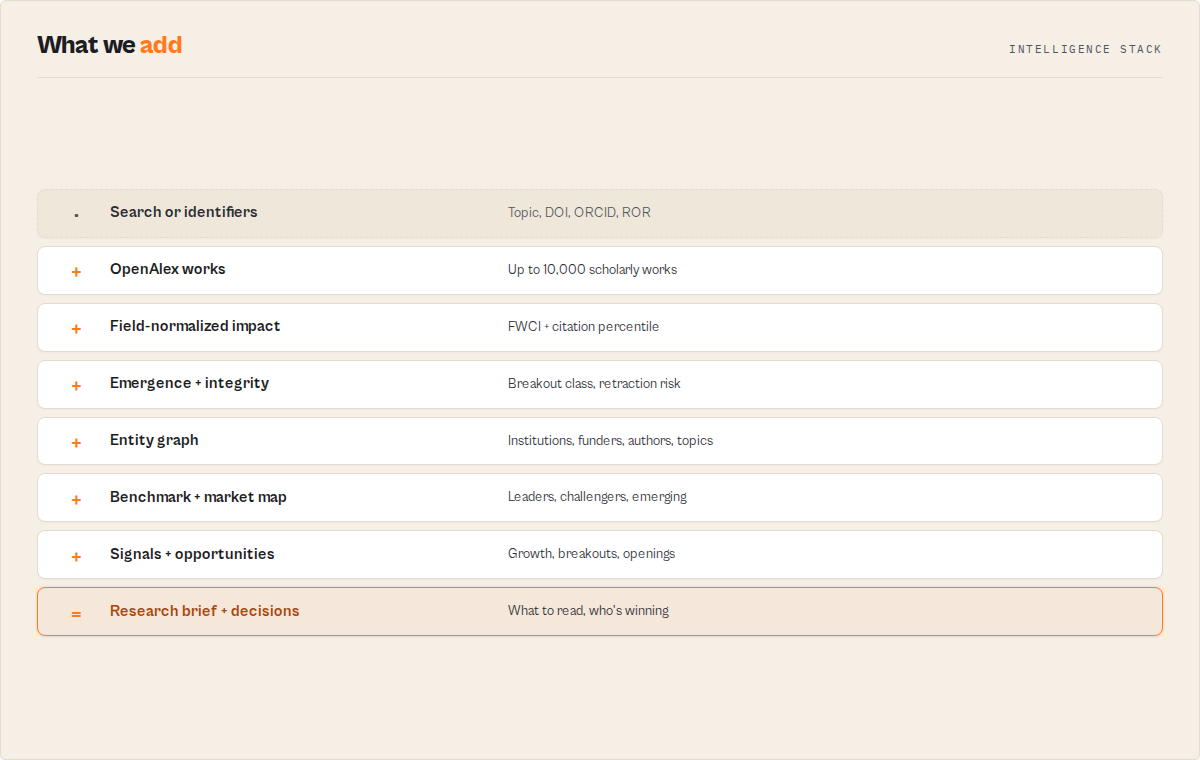
The intelligence layer (per paper)
| Signal | What it tells you |
|---|---|
impactClass | Field-normalized tier: landmark (top 1%) · high-impact (top 10%) · influential · solid · emerging · low-citation · unranked |
fwci | Field-weighted citation impact (1.0 = field average; 10+ = landmark) |
citationPercentile | Field+year normalized percentile, with top-1% / top-10% flags |
impactScore / relevanceScore | Dual axis: how influential (normalized) vs how well it fits your query -- they genuinely disagree, so you sort by the question you're asking |
score | Flagship composite (0-100), weighted by your analysis mode, with a scoreFactors breakdown |
citationMomentum | accelerating · steady · declining · new -- from the year-by-year citation trajectory |
emergenceClass / emergenceScore | breakout · rising · watch · normal -- the trajectory axis: a young, accelerating paper reads as breakout even before its FWCI settles |
scoreConfidence / knownLimitations | high · medium · low plus plain-English caveats, so a sparse-metadata or very-recent score is never read as authoritative |
openAccessStatus | gold · green · hybrid · bronze · diamond · closed, plus a free-to-read URL |
integrityStatus / citationSafe / ragSafe | Retraction and paratext flags; whether it's safe to cite and safe to feed a RAG index |
citationRisk | low · medium · high with reasons, tiered from retraction, citation-window, author concentration, and missing field-normalized signal |
field / subfield / domain / topConcepts | The concept hierarchy and Wikidata-linked concepts |
institutions / leadInstitution / countries | The affiliation graph with ROR IDs, countries, and types |
orcidShare / funders / collaborationScope | Author disambiguation coverage, funding, and single / multi-institution / international reach |
recommendation / whyRead / summary | The decision, the reasons, and an LLM-quotable one-liner |
How it works
Search query + filters
|
v
[Fetch works] -----> OpenAlex API (free polite pool, 200 per page)
|
v
[Score each work] - field-normalized impact class + dual-axis scores
| - citation momentum, OA + integrity, concept graph
| - institution / author / funder graph
v
[Build landscape] - field/concept/institution/country/funder leaderboards
| - maturity, impact distribution, honest gaps, drift
v
[Build research brief] - must-read papers, reading order, next queries
|
v
[Stream records] -----> decision-first dataset views + KV mirrors
Analysis is deterministic and computed from the works already fetched -- no extra paid API calls for the landscape or brief.
Analysis modes
Pick the mode that matches your job; it reweights the flagship score:
- Discovery -- favours query-fit (default; "what's relevant to my search?")
- Impact ranking -- favours field-normalized impact ("what are the landmark papers?")
- Landscape -- balances both ("map the whole field")
- Institutional -- emphasises the affiliation graph ("who's doing this work?")
- Monitoring -- for scheduled re-runs that track a field over time
How to use
- Open the actor in Apify Console and click Start.
- Enter a Search Query (searches titles, abstracts, and full text).
- Pick an Analysis Mode and set Max Results.
- Optionally filter by year (single or range), minimum citations, work type, country, open access, or minimum impact class.
- Run, then read the
research-brieffirst, browse the Decisions dataset view, or pull theSUMMARY/RESEARCH_BRIEF/RESEARCH_LANDSCAPEkey-value records.
No API key is required -- the public OpenAlex works endpoint is free and keyless via the polite pool (100k calls/day). Supply an OpenAlex key only if you have a premium plan and want its higher limits.
Example input
{
"searchQuery": "CRISPR gene editing",
"analysisMode": "impact-ranking",
"fromPublicationYear": 2020,
"toPublicationYear": 2024,
"minImpactClass": "influential",
"openAccessOnly": false,
"maxResults": 100
}
Python
from apify_client import ApifyClient
client = ApifyClient("YOUR_API_TOKEN")
run = client.actor("kbV7IqCW7tszfXB96").call(run_input={
"searchQuery": "transformer neural network architecture",
"analysisMode": "impact-ranking",
"fromPublicationYear": 2020,
"maxResults": 100
})
for rec in client.dataset(run["defaultDatasetId"]).iterate_items():
if rec.get("recordType") == "paper":
print(f"[{rec['impactClass']}] {rec['title']} - FWCI {rec.get('fwci')}")
Input parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
searchQuery | String (required) | -- | Keyword search across titles, abstracts, and full text (ignored in identifier mode) |
inputMode | String | query | query (keyword search) or identifiers (enrich DOIs / OpenAlex IDs, or pull an author's / institution's works) |
identifiers | String[] | -- | Identifier mode: DOIs, OpenAlex work IDs (W…), ORCIDs, author IDs (A…), RORs, institution IDs (I…) |
analysisMode | String | discovery | discovery · impact-ranking · landscape · institutional · monitoring |
maxResults | Integer | 50 | Works to analyse, 1–10,000 |
minImpactClass | String | any | Keep only solid / influential / high-impact / landmark and above (excluded works are counted, not hidden) |
excludeRetracted | Boolean | false | Drop retracted works (counted in the summary) |
openAccessOnly | Boolean | false | Only freely available works |
publicationYear | Integer | -- | Exact publication year |
fromPublicationYear / toPublicationYear | Integer | -- | Publication-year range (inclusive) |
minCitations | Integer | -- | Minimum citation count |
workType | String | -- | One OpenAlex work type (e.g. article, review, preprint) |
country | String | -- | 2-letter country code of at least one author affiliation |
sortBy | String | relevance_score:desc | relevance_score:desc · cited_by_count:desc · publication_date:desc |
outputProfile | String | standard | minimal · standard · full |
outputMode | String | papers | papers (full output) or dashboard (landscape digest only, single charge) |
emitResearchBrief | Boolean | true | Include the research-brief hero record |
includeEntityProfiles | Boolean | false | Emit institution / funder / author / source profiles + a collaboration-network insight (corpus-derived, no extra API calls) |
includeTopicIntelligence | Boolean | false | Query mode only: emit topic-profile + trend-signal + opportunity-signal (one extra group_by query for true field growth) |
compareInstitutions | String[] | -- | Competitive mode: institution names / RORs / OpenAlex IDs to rank head-to-head (optionally scoped to searchQuery) |
includeGraphExport | Boolean | false | Write GRAPH_NODES / GRAPH_EDGES to the key-value store |
includeCitationExports | Boolean | false | Write BIBTEX_EXPORT / RIS_EXPORT to the key-value store |
monitorMode | Boolean | false | Track this query across scheduled runs |
watchlistName | String | default | Name for the monitored baseline (monitor mode only) |
monitorSensitivity | String | medium | low (high-impact only) · medium · high (everything) |
alertOn | String[] | -- | Restrict monitor alerts: new_work · new_high_impact · new_landmark · citation_breakout · retraction |
apiKey | String | -- | Optional OpenAlex premium key for higher limits |
This is competitive, technology, and innovation intelligence built on the scholarly record -- not just an academic search tool.
- Strategy & management consultants -- map a technology landscape end to end: leaders, challengers, and emerging players, with the funders and institutions behind them.
- Corporate R&D & innovation teams -- track where a field is moving, who's accelerating, and which adjacent areas are opening up.
- VCs & technology scouts -- find accelerating research clusters and high-growth-low-competition openings before they're obvious.
- Universities & research offices -- benchmark institutions head-to-head, spot emerging competitors, track how a field and its funding are shifting.
- Grant writers & research funders -- see where funding concentrates and which high-impact areas look underfunded.
- AI / RAG builders -- assemble a citation-safe, open-access corpus (
ragSafe) and monitor a domain on a schedule. - Researchers & academics -- get the must-read and rising papers and an ordered reading list instead of a 500-row dump.
- AI agents -- call this for decisions (
recommendation,impactClass,decision-grade enums) they branch on without parsing prose.
Performance & cost
Deterministic analysis runs in-process on the works already fetched, so the landscape and brief add no extra API calls.
| Scenario | Papers | Approx. duration |
|---|---|---|
| Quick search | 50 | ~5–10 seconds |
| Medium batch | 500 | ~15–25 seconds |
| Large batch | 1,000 | ~25–45 seconds |
| Maximum run | 10,000 | a few minutes |
Apify platform compute charges apply. The OpenAlex public API is free.
Scoring methodology
Every score is a deterministic function of OpenAlex fields. No LLM, no randomness, the same input returns the same output.
impactScore-- field-normalized influence, led by FWCI (field-weighted citation impact, where 1.0 is the field+year average) and OpenAlex'scitation_normalized_percentile, with a citation-momentum adjustment. When a work is too new to carry an FWCI, a damped raw-citation contribution is used and the record is flagged accordingly.relevanceScore-- query fit: OpenAlex search rank (primacy), primary-topic match, and a small recency lift.score-- the flagship composite, a weighted blend of impact and relevance set byanalysisMode, with a retraction penalty.scoreFactors[]itemizes the contributions.emergenceScore/emergenceClass-- citation trajectory fromcounts_by_year(recent half vs prior half, current partial year excluded), gated on recency.breakout= young + accelerating + a real citation base.citationSafe-- false when the work is retracted or paratext.ragSafe--citationSafeAND an open full-text location is present.citationRisk--low/medium/hightiered from signals actually in the metadata (retraction, paratext, the first-year citation window, single-author-non-journal, missing field-normalized signal despite age). It does not assert citation-cartel or self-citation patterns, which would need the citing-and-referenced-works graph this actor doesn't fetch.topic-profilegrowth + maturity + trajectory -- computed from onegroup_by=publication_yearquery returning the TRUE field-level per-year volume (not the capped result sample), with the current partial year excluded.trajectoryreports whether growth itself is accelerating (a deterministic recent-vs-older comparison, never a numeric prediction).opportunity-signal-- a labelled heuristic, never a forecast, and each record carries its ownmethodology+limitations.high_growth_low_competition:growthScore = clamp(50 + YoY publication growth %)(so +50% YoY = 100),competitionScore = log10(total field works) x 16.7(so ~1M works = 100),opportunityScore = growthScore x 0.6 + (100 - competitionScore) x 0.4.underfunded_high_impact:highImpactShare x 60 + (1 - fundedShare) x 40. Growth is publication volume (not citations); competition is a volume proxy; funder coverage is incomplete -- the record says so.institution-comparisonresearch momentum --avgImpactScore x 0.5 + emergingShare x 30 + highImpactShare x 20, so it favours the accelerating challenger over the big incumbent.market-mapplaces each entity by two axes relative to the set's own medians and reports avolumePercentile+impactPercentileper entity so the quadrant is auditable, not arbitrary; "declining" is omitted from a single run because it needs a time axis (monitor mode).corpusRisk(on the summary) -- a run-level fragility read from field concentration, single-country or few-institution dominance, retraction presence, and low international collaboration. Structural facts about the result set, not a quality judgement on any paper.scoreConfidence-- reflects metadata completeness (citation history, topic assignment, institution graph) and age; capped atlowinside the first-year citation window.knownLimitations[]lists the caveats in plain English.field-benchmark-- benchmarks the corpus against the FWCI baseline of 1.0; the baseline is OpenAlex's own field normalization, not a fabricated cohort average.
What this actor does not do
- It does not claim peer-review quality or make clinical / policy recommendations -- it reports OpenAlex's metadata and deterministic scores over it.
- It does not generate any claims with an LLM. Every field is rule-derived and reproducible.
- It does not guarantee OpenAlex metadata is complete; sparse or very recent records are flagged with
scoreConfidenceandknownLimitations, never silently scored as if complete. - Very recent papers are often under-cited and carry no FWCI yet -- they surface via
emergenceClass, not as low-impact. - For bulk BibTeX / RIS from a DOI list, Crossref Paper Search is the dedicated tool; the exports here are a convenience.
- Funder-ID lookup is not supported (the OpenAlex works funder filter is unavailable); funder intelligence still ships via the funder-profile and funder landscape.
Research jobs this handles
One actor, one input (your topic or field), many jobs. Each row is a buyer job and the records that answer it:
| Job you're doing | How | What you get |
|---|---|---|
| Find landmark / seminal / most-influential papers | analysisMode: impact-ranking | papers ranked by field-normalized impact (FWCI), impactClass: landmark first |
| Find emerging / rising / breakout papers and trends | analysisMode: discovery | emergenceClass: breakout papers + trend-signal topic growth |
| Find high-growth-low-competition or underfunded-high-impact openings | includeTopicIntelligence: true | opportunity-signal records with the score's methodology on the record |
| See who's leading a field / top institutions / who's winning | analysisMode: landscape + includeEntityProfiles: true | market-map, institution leaderboard, institution-comparison |
| Map a field's funding / top funders / funding landscape | includeEntityProfiles: true | funder-profile records + the funder landscape in research-landscape |
| Build a citation-safe / open-access corpus for RAG | openAccessOnly: true | ragSafe papers, retraction-excluded, with open full-text URLs |
| Decide what to read, cite, or skip | any run | per-paper recommendation (must-read / read / scan / skip) + whyRead |
| Monitor a field for what's new, rising, or retracted | monitorMode: true | research-delta since the last run with the alerts that fired |
The field or topic is your input; the job is the actor's mode. Ready-to-run versions of the most common jobs are in Ready-to-run examples above.
FAQ
Do I need an API key? No. The public OpenAlex works endpoint is free and keyless via the polite pool (100k calls/day). Supply an OpenAlex key only if you have a premium plan and want higher limits.
What is FWCI and why does it matter? Field-weighted citation impact normalizes a paper's citations against others in the same field and year. 1.0 is the field average; 10+ is exceptional. It's the fair way to compare a maths paper to a biomedicine paper -- raw citation counts can't.
How is this different from your other paper-search actors? Semantic Scholar, Crossref, PubMed, and arXiv siblings return papers and metadata for their sources. This actor leads with OpenAlex's distinct assets -- field-normalized impact, the institution/author/funder graph, and the concept hierarchy -- and returns scored decisions and a landscape, not raw rows.
Is the scoring deterministic? Yes. Every score, class, and recommendation is computed from OpenAlex fields with fixed rules. No LLM, no randomness -- the same query returns the same output.
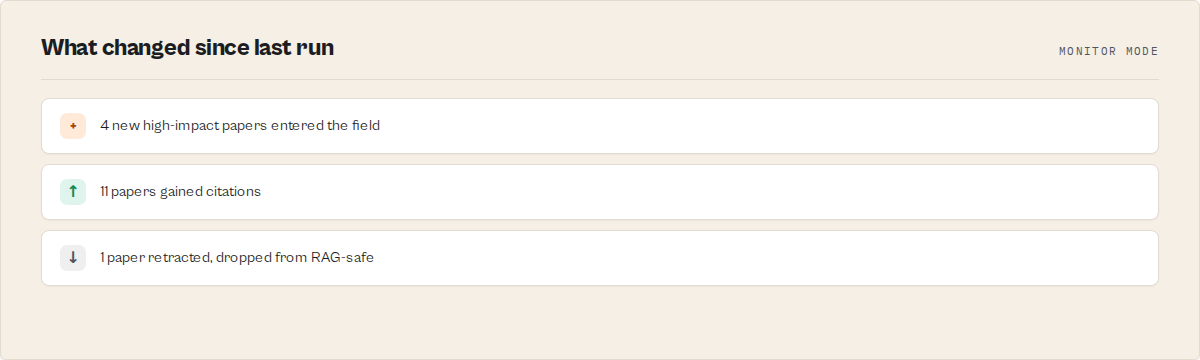
What does monitor mode do?
With monitorMode on, the actor stores a per-watchlist baseline and, on the next run, emits a research-delta listing new papers, citation risers, and impact shifts. First run captures the baseline.
Can I get only the digest?
Set outputMode to dashboard to suppress per-paper records and return only the landscape digest (charged as a single event).
What types of works are covered?
Journal articles, conference papers, reviews, book chapters, dissertations, preprints, datasets, and more. Filter with workType.
What happens with no results?
The run completes successfully and emits a no-results record. Broaden the query or relax filters.
Use in Dify
Drop this actor into Dify workflows via the Apify plugin's Run Actor node. Each paper returns scored, classified, and recommended as structured JSON: impactClass (landmark / high-impact / influential / solid / emerging / unranked) and recommendation (must-read / read / scan / skip / caution) plus the citationSafe / ragSafe booleans your downstream node branches on. A raw OpenAlex wrapper pointed at the same query returns metadata rows; this returns decisions.
- Actor ID:
ryanclinton/openalex-research-search - Sample input (rank a field by field-normalized impact, open access only, for a RAG corpus):
{
"searchQuery": "retrieval augmented generation",
"analysisMode": "impact-ranking",
"fromPublicationYear": 2022,
"openAccessOnly": true,
"minImpactClass": "influential",
"maxResults": 100
}
A Dify if/else node routes on the stable enums without parsing prose, for example:
recordType == "research-brief"→ feedexecutiveSummary+mustReadstraight into the answerrecordType == "paper"ANDragSafe == true→ index into the vector storeimpactClass == "landmark"ORrecommendation == "must-read"→ surface to the user firstintegrityStatus == "retracted"→ drop from the corpus
Opt-in modes Dify workflows can leverage: analysisMode (discovery / impact-ranking / landscape / institutional / monitoring) reweights the ranking; outputMode: "dashboard" returns a single landscape digest (one charge) when you only need the field overview; monitorMode + watchlistName make a scheduled run emit a research-delta of new and rising papers. The structured arrays the actor emits (whyRead, keyFindings, suggestedQueries, mustRead) are usable verbatim in a downstream node, no LLM rewriting required.
Related actors
| Actor | Description |
|---|---|
| PubMed Research Search | Biomedical evidence appraisal and triage via PubMed/NCBI |
| Semantic Scholar Search | Research intelligence via Semantic Scholar's knowledge graph |
| Crossref Paper Search | Scholarly metadata via the Crossref DOI registry |
| arXiv Paper Search | Preprints across physics, maths, computer science, and more |
Compare this actor
Related actors
AI Cold Email Writer — $0.01/Email, Zero LLM Markup
Generates personalized cold emails from enriched lead data using your own OpenAI or Anthropic key. Subject line, body, CTA, and optional follow-up sequence — $0.01/email, zero LLM markup.
AI Outreach Personalizer — Emails with Your LLM Key
Generate personalized cold emails using your own OpenAI or Anthropic API key. Subject lines, opening lines, full bodies — tailored to each lead's role, company, and signals. $0.01/lead compute + your LLM costs. Zero AI markup.
Bulk Email Verifier — MX, SMTP & Disposable Detection at Scale
Verify email deliverability in bulk — MX records, SMTP mailbox checks, disposable detection (55K+ domains), role-based flagging, catch-all detection, domain health scoring (SPF/DKIM/DMARC), and confidence scores. $0.005/email, no subscription.
CFPB Complaint Intelligence — Vendor Risk & Screening
Turn 5M+ CFPB consumer complaints into decisions: screen companies pass / review / fail, score complaint-handling risk, monitor what changed since last run, benchmark cohorts, and build audit-ready due-diligence packs. Filter by company, product, state, and date. No API key.
Ready to try OpenAlex Research Radar — Impact, Funders & Competitors?
Run it on your own Apify account. Apify offers a free tier with $5 of monthly credits.
Open on Apify Store