The problem: Your AI assistant cites a feature you deprecated in 2024. It answers a billing question with a help page you archived. It confidently quotes two different setup steps from two versions of the same doc. Everyone blames the model. The model is fine. The thing feeding it, your knowledge corpus, is rotting, and nobody can see it.
That rot has a name. It's documentation debt, and it's the single most underdiagnosed cause of bad AI answers I run into.
What is documentation debt? Documentation debt is the accumulated decay in a knowledge corpus (duplicate pages, stale content, orphaned pages, thin pages, and version conflicts) that quietly degrades the quality of answers a RAG system or AI assistant produces from it.
Why it matters: Retrieval-augmented generation can only return what it's fed. Retrieval-quality research consistently finds that corpus noise, not model size, drives the largest swings in answer accuracy. Debt is invisible until production answers are already wrong.
Use it when: You're building or maintaining a RAG pipeline, an AI search box over your docs, an internal knowledge assistant, or any system that embeds a website or help centre into a vector database.
Also known as: content debt, knowledge-base rot, corpus drift, stale documentation, retrieval noise, knowledge decay.
The whole chain in two lines:
Clean corpus → good retrieval → correct AI answers
Documentation debt → noisy retrieval → confident wrong answers
Same model, same prompt, same retriever. The only variable that changed is the corpus.
Quick answer
- What it is: the slow decay of a knowledge corpus (duplicates, stale, orphan, thin, version-conflicted pages) that poisons RAG retrieval.
- When it bites: after you've embedded a site once and the docs keep changing while the vector store doesn't.
- When it's not your problem: a static, single-version, hand-curated corpus of a few dozen pages. Debt accumulates slowly there.
- Typical fix path: measure the debt, filter low-value pages out of embedding, dedupe, re-embed only what changed.
- Main tradeoff: measuring corpus health by hand doesn't scale; you need it computed every crawl, not audited once a quarter.
Problems this solves:
- How to find out why my RAG system gives outdated answers
- How to detect duplicate and stale pages before embedding a website
- How to measure the quality of a knowledge corpus for AI search
- How to stop old documentation versions from leaking into AI answers
- How to cut embedding costs by skipping low-value pages
- How to re-embed only the pages that changed since the last crawl
In this article: What it is · Why it matters · How it shows up · Alternatives · Best practices · Common mistakes · Limitations · FAQ
Key takeaways
- Documentation debt comes in 5 main forms: duplicate, stale, orphan, thin, and version-conflicted pages. Each degrades retrieval differently.
- Most teams discover debt only after a wrong answer reaches a customer; by then it's been in the vector store for weeks.
- Embedding a deduplicated corpus instead of the raw crawl can cut token costs noticeably. In one run I saw a double-digit percentage of tokens were exact duplicates.
- Version conflicts (v1 docs bleeding into v3 answers) are the hardest debt to spot because both pages look "correct" in isolation.
- A corpus health score computed on every crawl turns an invisible, slow-burn problem into a number you can watch.
Documentation debt in practice
| Symptom in production | Underlying debt | What retrieval does wrong |
|---|---|---|
| AI cites a removed feature | Stale page still embedded | Returns confident, outdated text |
| Two conflicting setup steps | Version conflict (v1 + v3) | Mixes versions in one answer |
| Same answer phrased 3 ways | Duplicate pages | Wastes context window, dilutes ranking |
| AI "doesn't know" a documented thing | Orphan page never crawled | Coverage gap (content exists, isn't indexed) |
| Vague, low-confidence answers | Thin pages embedded | Empty chunks pollute the index |
What is documentation debt?
Definition (short version): Documentation debt is the accumulated, usually invisible decay in a knowledge corpus (duplicates, stale content, orphans, thin pages, and version conflicts) that lowers the accuracy of any RAG or AI-search system built on top of it.
It's the corpus-quality equivalent of technical debt. You don't pay it when it's created. You pay it later, with interest, when an AI assistant gives a wrong answer and you have no idea which of ten thousand pages caused it.
The 5 types of documentation debt
Name them and you can talk about them. The same way engineers say "that's tech debt," teams with a RAG corpus should be able to say "that's version debt":
- Duplicate Debt. The same content reachable at multiple URLs, or boilerplate repeated across pages. Inflates embedding cost and splits retrieval ranking across near-identical chunks.
- Stale Debt. Content not updated in a long time, often describing behaviour that no longer exists. The model can't tell old-and-wrong from old-and-still-true.
- Orphan Debt. Pages that exist in the sitemap but have no inbound links. They get missed by link-following crawlers, so the content is there but never indexed. A silent coverage gap.
- Thin Debt. Near-empty pages, redirect stubs, "coming soon" placeholders. They become empty or near-empty chunks that pollute the vector index.
- Version Debt. v1, v2, and v3 of the same doc all live and crawlable, so a query for "how to authenticate" retrieves three different, mutually contradictory answers.
The nasty part: none of these throw an error. Your crawl succeeds. Your embeddings generate. Your RAG pipeline returns results. Everything is "green." The debt sits in the content, not the plumbing.
Why does documentation debt cause bad AI answers?
Documentation debt causes bad AI answers because retrieval-augmented generation is only as good as what it retrieves. The model doesn't fact-check the corpus. It trusts it. Feed it a stale or contradictory page and it will quote that page back with total confidence.
Here's the mechanism. A RAG system embeds your pages into a vector database, then for each user question it pulls the top-k most similar chunks and stuffs them into the model's context. The model answers from those chunks. If the most semantically similar chunk happens to be a deprecated v1 doc, that's the answer you get.
Princeton's 2023 GEO research and multiple retrieval studies since have shown the same thing from different angles: corpus quality dominates answer quality. A bigger model on a noisy corpus loses to a smaller model on a clean one. People keep upgrading the model. The model was never the bottleneck.
And the failure is asymmetric. A missing page produces an "I don't know," annoying but honest. A stale page produces a confident, wrong, plausible answer, which is far worse, because nobody catches it until a customer acts on it.
Documentation debt is expensive
Bad answers are the visible cost. The invisible one is money. You pay to embed every page, pay to store every vector, and pay to search the whole index on every query, including the debt.
Here is the shape of it (illustrative, your numbers will differ):
1,000 pages ≈ 2,000,000 tokens
15% duplicated boilerplate → ~300,000 redundant tokens
Embed it, store it, search it on every query.
Refresh the corpus monthly → ×12.
That duplicated slice alone is millions of wasted tokens a year,
before a single user has asked a question.
Duplicate Debt and Thin Debt are pure waste: you are paying full embedding and storage cost to make your retrieval worse. Skipping the pages that should never be embedded, and re-embedding only what changed instead of the whole corpus on every refresh, is where the bill actually drops. Debt is not just an accuracy problem; it is a line item.
How does documentation debt show up in RAG?
Documentation debt shows up as confidently wrong answers, contradictory answers to the same question asked twice, citations to pages you thought were gone, and "the AI doesn't know things that are clearly documented." Each maps to a specific debt type in the corpus.
Here is what it looks like from the customer's side:
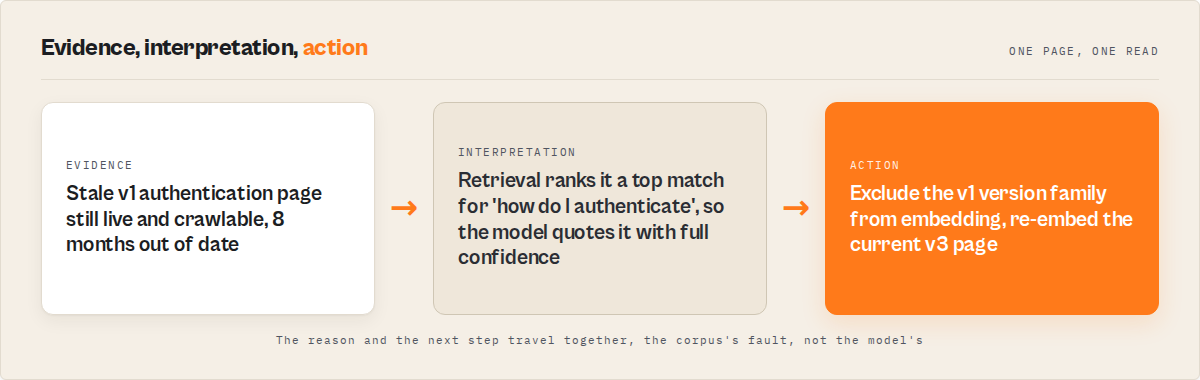
User: How do I authenticate?
AI: Use an API key in the Authorization header.
Truth: API keys were deprecated 8 months ago. OAuth is now mandatory.
The AI retrieved the stale v1 page. (Stale Debt + Version Debt)
User: How do I cancel my subscription?
AI: Go to Billing → Plans → Cancel.
Truth: That billing UI was retired in the last redesign. The archived
help page was never removed from the corpus. (Stale Debt)
Neither answer looks wrong. Both are fluent, specific, and confident. The customer follows the instructions, hits a wall, and files a ticket blaming your product. Nobody traces it back to page #4,812 in a crawl from three weeks ago.
The reason it's so hard to debug is that the symptom and the cause are far apart. The symptom is a bad chat answer in production. The cause is page #4,812 in a crawl from three weeks ago. Without something measuring the corpus itself, you're reverse-engineering a single bad answer back to one rotten page across the whole index. That's a needle-in-haystack job nobody has time for.
So most teams don't debug it. They tweak the prompt, swap the embedding model, bump top-k, and the bad answers keep coming, because the debt is still sitting in the vector store.
How does retrieval-augmented generation use a knowledge corpus?
Retrieval-augmented generation works by converting documents into vector embeddings, storing them in a vector database, retrieving the chunks most similar to a user's question, and passing those chunks to a language model as context. The model's answer is grounded in whatever was retrieved.
That last sentence is the whole story. The answer is grounded in whatever was retrieved, not in what's true, not in your latest docs, but in whatever sat closest in vector space. Curating what goes into the index is the single highest-impact thing you can do for answer quality, and it's the step most pipelines skip.
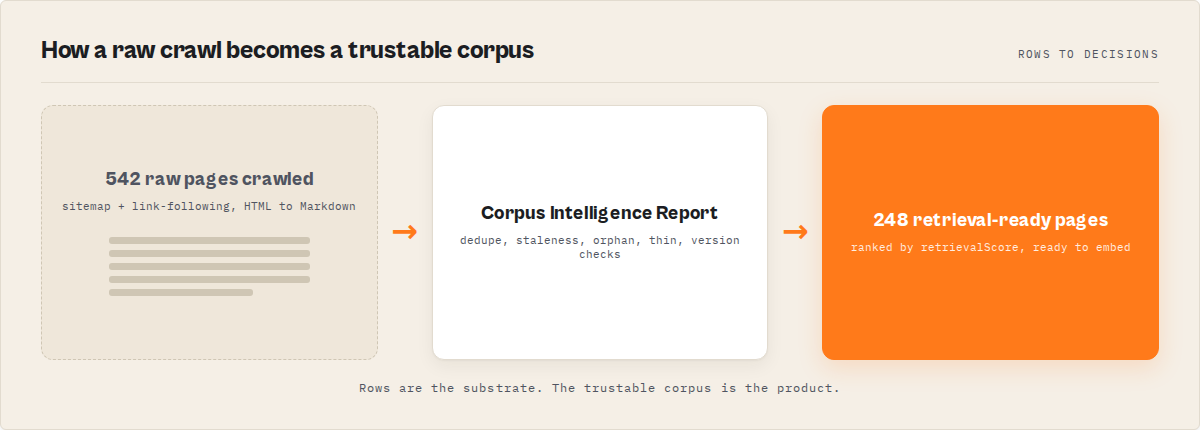
What does a corpus intelligence report look like?
A corpus intelligence report is a structured summary of a crawled knowledge corpus that grades its retrieval-readiness: typically a single corpus score plus counts of duplicate, stale, orphan, and thin pages, a coverage confidence figure, and plain-English recommendations. It turns documentation debt into measurable numbers.
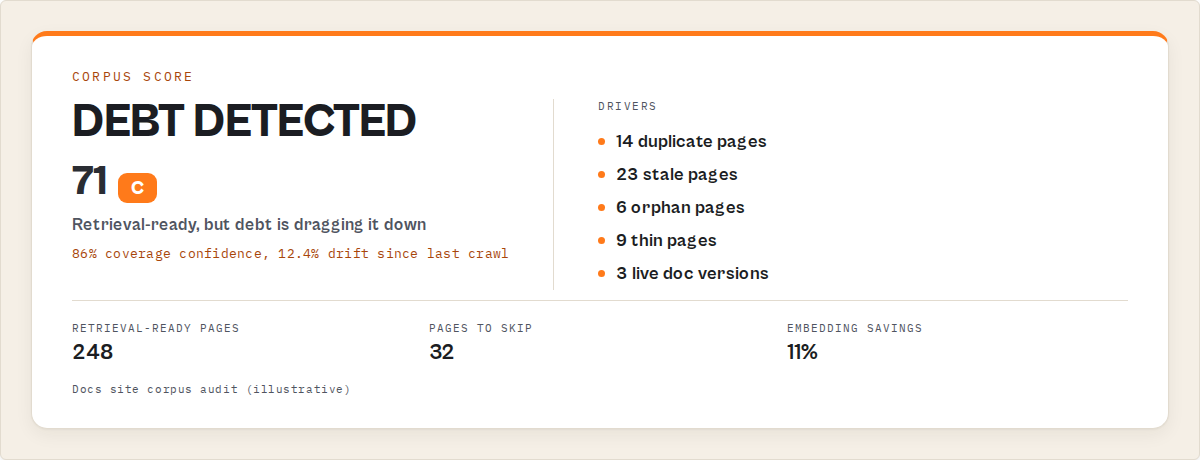
Instead of guessing, you get an object like this emitted alongside the crawl (real field shape from the Knowledge Intelligence Engine Apify actor, also on the Apify Store):
{
"corpusScore": 71,
"coverageConfidence": 86,
"corpusDrift": 12.4,
"duplicatePages": 14,
"orphanPages": 6,
"thinPages": 9,
"stalePages": 23,
"documentationDebtPages": 4,
"retrievalReadyPages": 248,
"pagesToSkip": 32,
"embeddingSavingsPct": 11,
"versions": ["v1", "v2", "v3"],
"recommendations": [
"14 duplicate page(s) detected — dedupe on canonicalUrl before embedding.",
"23 stale page(s) (not updated in over a year) — review for freshness.",
"6 orphan page(s) found (in the sitemap, no inbound links) — review site navigation.",
"11% of tokens are duplicated — embedding the deduped set saves tokens."
]
}
That's the difference between "our RAG feels off" and "skip these 32 pages, dedupe these 14, and 23 are stale." One is a vibe. The other is a work order.
What are the alternatives to measuring documentation debt?
There are a few ways teams try to deal with corpus rot. Each names a real approach; none of them are something I'd hand you a script to build, because the maintenance is the actual product.
1. Manual content audits. A human (or a quarterly committee) reviews the docs and flags what's old. Best for: tiny corpora that change rarely. The catch: it's a snapshot in time, it doesn't scale past a few hundred pages, and the debt re-accumulates the moment the audit ends. You're auditing the corpus, not the embedded index, and those drift apart fast.
2. Generic web-to-markdown crawlers (e.g. Firecrawl-style tools). These convert a site to clean markdown for embedding. Best for: the conversion step itself. But they hand you the raw crawl with no judgement about which pages deserve to be embedded. Duplicates, thin pages, and stale content go straight into your vector store at full token cost. The cleaning is on you, every run, forever.
3. Vector-database "quality" dashboards. Some vector stores show index stats. Best for: operational metrics like query latency and recall. They measure the index after the bad pages are already in it. They can't tell you a chunk came from a deprecated v1 doc; that context is gone by the time it's a vector.
4. Build-it-yourself corpus QA. You crawl, hash for dupes, score freshness, detect versions, compute coverage, and re-run it on a schedule. Best for: teams who want to own every line. Realistically, you inherit deduplication on canonical URLs, per-page freshness scoring, version-family detection, sitemap-vs-captured coverage math, cross-run drift fingerprinting, and a retrieval-readiness gate per page. That's a maintained internal service, not a weekend script. It rots the same way the docs do.
5. A crawler that emits corpus intelligence inline. Crawl the site and get the retrieval-ready markdown and the debt report in one deterministic pass. Best for: anyone who wants the measurement to happen automatically on every refresh, not as a separate project.
Each approach has trade-offs in coverage, maintenance burden, cost, and how soon you find out about debt. The right choice depends on corpus size, how often it changes, and whether you have an engineer to own corpus QA as an ongoing job.
| Approach | Detects debt automatically | Scales past 1,000 pages | Re-runs on every refresh | Maintenance burden |
|---|---|---|---|---|
| Manual audit | No | No | No | High (human time) |
| Generic markdown crawler | No | Yes | Conversion only | Medium (you clean) |
| Vector DB dashboard | After embedding | Yes | N/A | Low, but too late |
| Build-it-yourself QA | Yes (if you build it) | Depends | If you schedule it | Very high |
| Crawler + corpus report | Yes | Yes | Yes | Low |
Pricing and features based on publicly available information as of June 2026 and may change.
Best practices for keeping a corpus clean
- Measure before you embed. Score the corpus on every crawl, not once a quarter. Debt is a moving target; a quarterly audit is stale before the meeting ends.
- Filter on a retrieval-readiness score. Don't embed everything. Skip thin, empty, and near-duplicate pages before they reach the vector store.
- Dedupe on canonical URL first. The cheapest token is the one you never embed. Exact-duplicate content should be collapsed before chunking.
- Track versions explicitly. If your docs have v1/v2/v3, the corpus should know which is which, so you can exclude or down-weight old versions instead of letting them compete for retrieval.
- Watch coverage confidence. A high page count means nothing if you captured 60% of the sitemap. Orphan pages and missed pages are silent gaps, so track the ratio of captured-to-sitemap.
- Re-embed only what changed. When docs update, re-embedding the whole corpus is wasteful. Delta mode (re-embedding only new and changed pages) keeps cost and drift in check.
- Watch corpus drift between runs. A sudden 20%+ drift means a big chunk of your docs moved; that's a signal to re-check answer quality, not a routine refresh.
- Keep the report, not just the data. Store the corpus score over time so you can see debt accumulating before it shows up as a bad answer.
Common mistakes
- Blaming the model. Teams swap embedding models and bump top-k while the actual problem, a corpus full of stale pages, sits untouched. Fix the corpus first.
- Embedding the raw crawl. Dumping every crawled page into the vector store embeds duplicates, thin pages, and dead stubs at full cost and dilutes retrieval ranking.
- Treating coverage as a page count. "We indexed 5,000 pages" tells you nothing if 2,000 sitemap pages were never reached. Coverage is a ratio, not a tally.
- Ignoring version conflicts. Letting v1 and v3 docs both stay crawlable guarantees contradictory answers. Both look correct in isolation; together they poison retrieval.
- Re-embedding everything on every change. When one page changes, re-running the full corpus through embeddings wastes money and obscures what actually moved.
- Auditing once, then forgetting. A clean corpus today is a debt-laden corpus in six months. Without continuous measurement, you're back to square one by the next product launch.
Mini case study: a docs site that "felt fine"
A team I talked through this had an AI help-box over a ~280-page docs site. Users kept getting setup steps that didn't match the current UI. Engineering blamed the model and tried two embedding upgrades. No change.
When they ran a corpus crawl with intelligence reporting, the picture was obvious in one object: dozens of stale pages from an older product version were still live and crawlable, a chunk of pages were near-duplicates of migration guides, and the older version docs were outranking the current ones for setup queries. The fix wasn't a model. It was excluding the old version family, deduping the migration boilerplate, and re-embedding the filtered set. Before: confident wrong setup steps. After: answers grounded in current docs. No model change involved.
These numbers reflect one corpus. Results vary with site size, how clean the docs already are, and how aggressively you filter.
Implementation checklist
- Crawl the docs/help-centre/knowledge base into clean markdown.
- Get a corpus intelligence report in the same run (score, debt counts, coverage confidence).
- Read the recommendations. They tell you exactly which pages to dedupe, skip, or review.
- Filter pages below your retrieval-readiness threshold out of the embedding step.
- Exclude or down-weight old documentation versions.
- Embed the filtered, deduplicated set into your vector database.
- Name a watchlist so the next crawl computes corpus drift.
- On the next docs update, run delta mode and re-embed only changed pages.
Limitations
- Detection isn't deletion. A corpus report tells you which pages are debt; it doesn't edit your CMS. You still decide what to remove, redirect, or rewrite.
- JavaScript-heavy sites need care. HTTP-only crawling can return thin content on SPA docs; pages that need a browser to render are flagged, but you'll route those separately.
- Staleness is a heuristic. "Not updated in over a year" flags candidates, not certainties; some old pages are still perfectly correct. The report surfaces them for review, it doesn't judge truth.
- Version detection depends on signals. If your docs don't expose version info in URLs, paths, or metadata, version-family grouping is best-effort.
- It measures the corpus, not your retriever. A clean corpus removes one major failure source; chunking strategy, embedding model, and top-k still matter on top.
Key facts about documentation debt
- Documentation debt has five main forms: duplicate, stale, orphan, thin, and version-conflicted pages.
- RAG answers are grounded only in retrieved chunks, so corpus quality caps answer quality.
- Orphan pages create silent coverage gaps: the content exists but never gets indexed.
- Stale pages are more dangerous than missing pages because they produce confident wrong answers, not honest "I don't know" responses.
- Deduplicating a corpus before embedding can cut a double-digit percentage of token cost when boilerplate is heavy.
- Version conflicts are the hardest debt to detect because each conflicting page looks correct on its own.
- A corpus score computed on every crawl converts a slow-burn invisible problem into a watchable metric.
Glossary
- RAG (retrieval-augmented generation): an AI pattern that retrieves relevant documents and feeds them to a language model as context for its answer.
- Knowledge corpus: the full set of documents a RAG system can retrieve from.
- Embedding: a numeric vector representing a chunk of text so similar text sits nearby in vector space.
- Chunk: a slice of a page sized to fit an embedding model and a context window.
- Coverage confidence: a measure of how much of a site's sitemap a crawl actually captured, adjusted for orphan pages.
- Corpus drift: the percentage of a corpus that changed between two crawls.
Broader applicability
These patterns aren't specific to product docs. Corpus rot shows up anywhere a body of text feeds an AI system:
- Internal wikis and knowledge bases. Confluence/Notion spaces full of half-finished and superseded pages.
- Customer help centres. Old articles for retired features answering current support questions.
- Compliance and policy libraries. Superseded policy versions that must not leak into answers.
- Research and literature corpora. Duplicate preprints and retracted papers polluting a search index.
- Any AI search box. If it retrieves from documents, it inherits whatever debt those documents carry.
The universal principle: a retrieval system is a mirror of its corpus. Clean the mirror before you blame the reflection.
When you need this
You probably need to measure documentation debt if:
- You run RAG or an AI search box over a website, docs site, or help centre.
- Your AI gives outdated, contradictory, or confidently-wrong answers.
- Your docs change often but your vector store doesn't keep pace.
- You have multiple documentation versions live at once.
- Embedding costs feel higher than the amount of unique content justifies.
You probably don't need this if:
- Your corpus is a few dozen hand-curated pages that rarely change.
- You're not doing retrieval at all (pure fine-tuning, no RAG).
- Your content is single-version and tightly governed already.
Audit your corpus before you blame your model
You can't fix debt you can't see. Before swapping embedding models or tuning top-k again, get the one thing you're missing: a number for how much debt is in your corpus right now.
- Audit it. Crawl your docs, help centre, or knowledge base and get a corpus intelligence report in the same pass: a corpus score, duplicate / stale / orphan / thin / version counts, coverage confidence, and drift since last run.
- Measure the debt. Read the score and the per-page retrieval scores. Now "our RAG feels off" becomes "skip these 32 pages, dedupe these 14, 23 are stale."
- Then decide what to fix. The report is the work order; you choose what to exclude, dedupe, or refresh, and re-embed only what changed.
The Knowledge Intelligence Engine Apify actor produces that report on every crawl, deterministically, no LLM in the scoring path. The audit is the goal; the actor is just the fastest way to run it. Start with one crawl of your docs and read the corpus score.
Frequently asked questions
What causes a RAG system to give wrong answers?
Most wrong RAG answers come from the corpus, not the model. If the retrieved chunks are stale, duplicated, or from an old documentation version, the model answers confidently from bad source text. Studies on retrieval quality consistently find corpus noise drives larger accuracy swings than model size. Clean the corpus before swapping models.
How do I detect duplicate and stale pages before embedding?
Run a crawl that emits a corpus intelligence report. The Knowledge Intelligence Engine Apify actor crawls a site into clean markdown and returns counts of duplicate, stale, orphan, and thin pages plus per-page retrieval scores, deterministically, no LLM involved. You filter on those scores before embedding instead of dumping the raw crawl into your vector store.
What is the difference between documentation debt and technical debt?
Technical debt is decay in code: shortcuts that cost more to maintain later. Documentation debt is decay in a knowledge corpus: duplicate, stale, orphan, thin, and version-conflicted pages that lower the accuracy of any AI system retrieving from them. Both stay invisible until they cause a visible failure, and both compound if you don't measure them.
Does deleting old documentation fix bad AI answers?
Partly. Removing stale and conflicting pages from the corpus you embed does fix a major source of wrong answers. But you have to know which pages to remove first, and you have to keep your vector store in sync as docs change. Measuring debt on every crawl is what tells you what to remove and when it has crept back.
How does delta mode reduce embedding costs?
Delta mode re-embeds only pages that are new or changed since the last crawl, instead of the whole corpus. When you name a watchlist, the Knowledge Intelligence Engine actor stores each page's content hash and, on the next run, emits only what moved. For large docs that change a few pages at a time, that's the difference between re-embedding thousands of pages and re-embedding a handful.
How is documentation debt measured?
It's measured by crawling the corpus and computing a corpus score from the share of duplicate, stale, thin, and orphan pages, alongside a coverage-confidence figure (how much of the sitemap was captured) and corpus drift versus the previous run. The content extraction comparison shows how this differs from plain markdown crawlers that emit no quality signal at all.
Ryan Clinton publishes Apify actors and MCP servers as ryanclinton and builds developer tools at ApifyForge.
Last updated: June 2026
This guide focuses on Apify-based crawling, but the same documentation-debt patterns apply broadly to any RAG pipeline, internal wiki, or AI search system regardless of platform.