Wikipedia Research Intelligence — Topic Maps & Research Briefs is an Apify actor on ApifyForge. Turn a Wikipedia query into structured topic understanding: the primary concept, what matters, what to read first, the people and organizations around it, and the gaps. It costs $0.001 per article-fetched. Best for investigators, analysts, and risk teams conducting due diligence, regulatory tracking, or OSINT research. Not ideal for real-time surveillance or replacing classified intelligence systems. Maintenance pulse: 90/100. Last verified March 27, 2026. Built by Ryan Clinton (ryanclinton on Apify).
Wikipedia Research Intelligence — Topic Maps & Research Briefs
Wikipedia Research Intelligence — Topic Maps & Research Briefs is an Apify actor available on ApifyForge at $0.001 per article-fetched. Turn a Wikipedia query into structured topic understanding: the primary concept, what matters, what to read first, the people and organizations around it, and the gaps. Returns a deterministic research brief, topic map, and scored, classified results across 15 languages.
Best for investigators, analysts, and risk teams conducting due diligence, regulatory tracking, or OSINT research.
Not ideal for real-time surveillance or replacing classified intelligence systems.
What to know
- Limited to publicly available and open-source information.
- Report depth depends on the availability of upstream government and public data sources.
- Requires an Apify account — free tier available with limited monthly usage.
Maintenance Pulse
90/100Cost Estimate
How many results do you need?
Pricing
Pay Per Event model. You only pay for what you use.
| Event | Description | Price |
|---|---|---|
| article-fetched | Charged per Wikipedia article record retrieved. | $0.001 |
Example: 100 events = $0.10 · 1,000 events = $1.00
Documentation
Discover, map, and understand any topic using Wikipedia's knowledge graph. This Apify actor identifies the primary concept, ranks what matters, builds a research surface of the people, organizations, and fields around a topic, explains why each result is important, highlights knowledge gaps, and produces a deterministic research brief, all from one query. Every result carries a topic role (core / supporting / adjacent / peripheral), a centrality score (importance 0-100) distinct from article quality, a Wikidata entity type (business, film, human, …), a routing recommendation, and a plain-English why. It works across 15 language editions and is fully deterministic with no LLM, so the same query always returns the same structured output. Built for researchers, SEO teams, data analysts, and AI workflow builders (Dify, n8n, LangGraph, CrewAI) that need to understand a topic, not just retrieve rows.
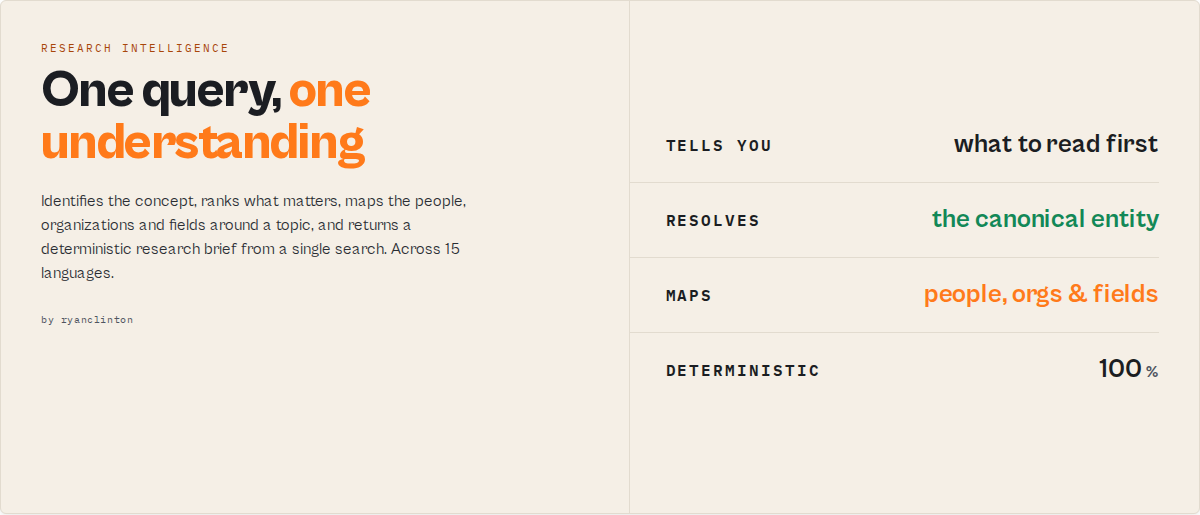
One query, one understanding
Most tools return articles. This actor returns a research brief: one object that tells you what a topic is, what matters, what to read, and what you are missing.
{
"recordType": "research-brief",
"topic": { "canonicalName": "Quantum computing", "entityType": "field of study" },
"whatMatters": ["Quantum computing", "Quantum algorithm", "Qubit"],
"learningPath": { "startHere": ["Quantum computing"], "nextRead": ["Quantum algorithm"] },
"suggestedQueries": ["Qubit", "Quantum error correction"],
"gaps": ["Quantum volume"]
}
That is the product. Everything below supports it.
Before and after
Without this actor:
Search Wikipedia
Open an article
Open its links
Open more links
Lose the thread
Try to piece the topic together
With this actor:
Search once
Get the primary concept and what matters
Get a reading order and a learning path
Get the people, organizations, and fields
Get the knowledge gaps and what to search next
One call replaces an afternoon of tab-hopping.
How it compares
Every tool returns articles. The real question is whether it answers what you actually need:
| Question you actually have | Wikipedia API | LLM chat tools | This actor |
|---|---|---|---|
| What is the topic, exactly? | no | partial | yes |
| What matters most? | no | partial | yes |
| What should I read first? | no | partial | yes |
| What am I missing? | no | no | yes |
| Can I automate it? | yes | no | yes |
| Same result every run? | yes | no | yes |
A new category: research intelligence
Search tools help you find documents. Research intelligence tools help you understand a topic. This actor is the second kind. It does not just retrieve Wikipedia pages; it identifies the concept, ranks what matters, maps the surrounding entities, and tells you where to start and what you are missing, in one deterministic pass.
Built for AI agents
Most search APIs return documents. AI agents need decisions. Every result carries the fields an agent branches on directly:
{ "topicRole": "core", "importance": 97, "recommendation": "recommended" }
So a Dify, n8n, LangGraph, CrewAI, or Flowise node knows what to read, what to ignore, and what matters, without another model call. The default research brief hands the agent the whole topic in one object, turning a retrieval step into a single call instead of a fan-out-and-summarise loop. This is context-selection infrastructure for retrieval pipelines.
Why not just use ChatGPT?
An LLM can explain a topic. It cannot guarantee the same output tomorrow, structured fields, or stable routing decisions. This actor is fully deterministic: the same query returns the same structured result every run, with no model in the scoring path. That is what makes it safe to wire into production automations (Dify, n8n, LangGraph, CrewAI), where a workflow has to behave the same way every time. Determinism here is a business property, not a technical footnote.
What customers use this for
- Researchers build a research surface around a topic and know where to start.
- SEO teams discover topic structure, content depth, and gaps.
- AI builders select the right context before retrieval, without an extra model call.
- Analysts understand a domain quickly from a single query.
- Knowledge-graph builders extract entities (people, organizations, fields, events) and their relationships.
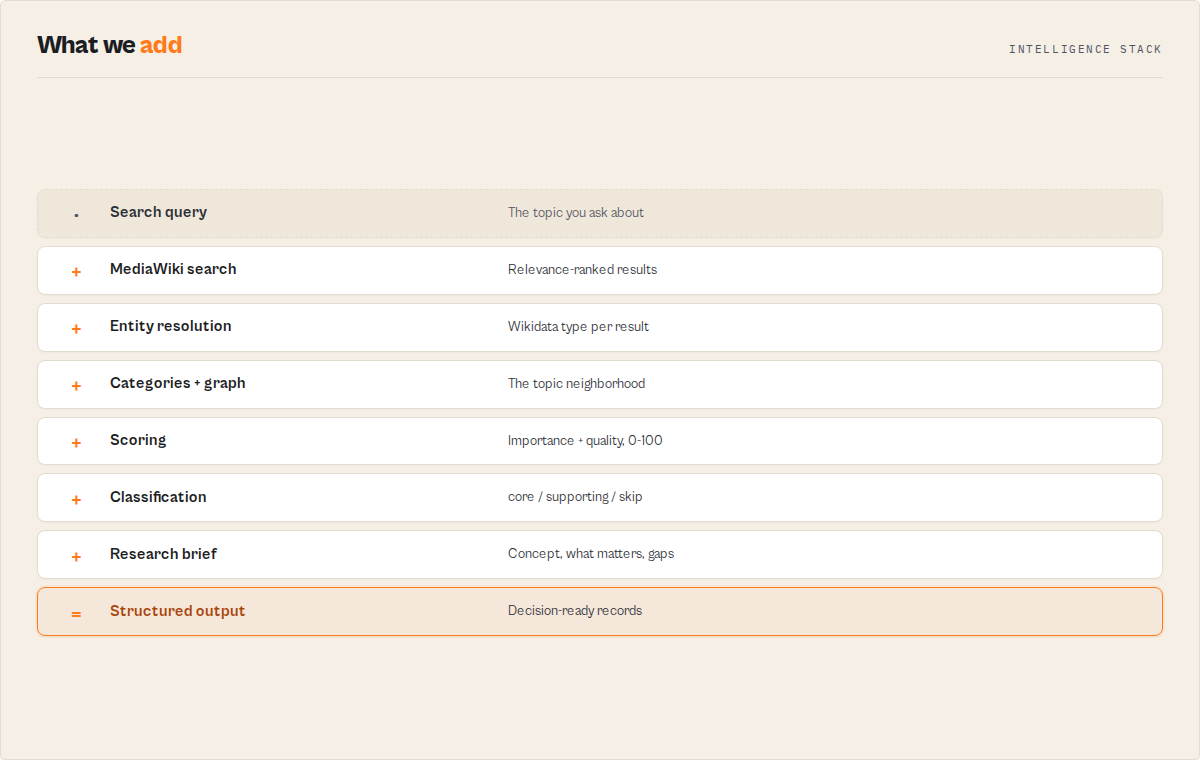
How a query becomes understanding
Query
-> Primary concept (the entity you meant)
-> What matters (ranked by importance)
-> Reading order and learning path
-> Topic map (people / organizations / fields / events)
-> Knowledge gaps and suggested next queries
Why use Wikipedia Research Intelligence?
- Entity resolution, not just titles -- every result is resolved to its Wikidata semantic type, so "apple" the company and "apple" the fruit come back as structured, distinguishable entities.
- Topic intelligence -- score, classify, and role-tag every result (
core/supporting/adjacent/peripheral), and optionally map the people, organizations, and fields around a concept into a research surface. - Knowledge-graph enrichment -- categories, Wikidata IDs, and the related-article graph turn a flat result list into a connected topic structure.
- Research-ready datasets -- reading order, primary-concept selection, content-gap depth analysis, and cross-language coverage, all deterministic and ready for export.
- Agent-ready outputs -- stable enums, one-line summaries, and lean output profiles that AI agents branch on without parsing prose.
- Multilingual -- search and compare coverage across 15 Wikipedia language editions.
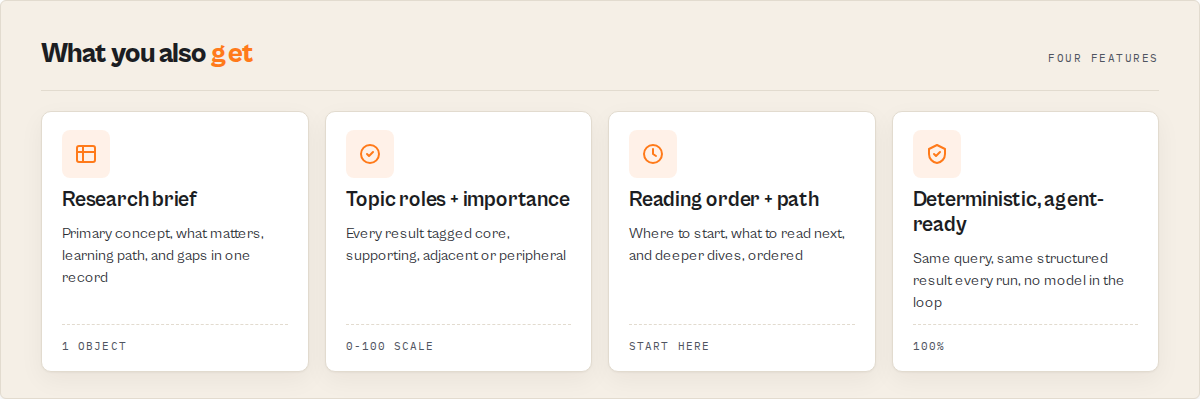
Key features
- Research brief -- every run emits a single
research-briefrecord: the canonical topic (resolved entity + type), the primary concept, a plain-English executive summary, what matters, a learning path (start here, next read, deeper dives, experts, organizations), suggested next queries, reading order, and gaps. The 5-minute understanding of a topic, assembled deterministically with no LLM - Topic composition (Topic DNA) -- with
expandTopic, the topic-map record reports the structural make-up of a topic: how many concepts, people, organizations, fields, and events surround it - Topic centrality (
importance0-100) -- a distinct axis from qualityscore: how central a result is to the queried topic, not just how good the article is (a core stub is high importance, low score) - Self-explaining results -- every result carries a
whyarray of plain-English reasons it landed at its role and rank, so you never have to reverse-engineer the score - Full-text search across all Wikipedia articles using the MediaWiki Action API with relevance-ranked results
- Quality scoring (0-100) -- every result is scored on a deterministic blend of search relevance, article depth, page structure, edit recency, and metadata completeness, with a
scoreTierband (excellent/good/fair/poor) - Search intent modes --
general/research/recent/overviewreweight the same five scoring signals for your use case (research favours depth, recent favours freshness, overview favours relevance) - Article classification -- each result is typed as
comprehensive,substantial,stub,list, ordisambiguation, so you can filter out navigation pages and thin stubs in one pass - Wikidata entity types -- each result is resolved to its semantic type via Wikidata
instance of(P31), e.g.business,film,human,academic discipline-- the entity-aware layer that turns "apple" the fruit vs the company into structured data - Primary concept flag --
isPrimaryConceptmarks the canonical article for the query (top-ranked, non-disambiguation), so agents know which page the search actually refers to - Categories -- visible Wikipedia categories per article (maintenance/hidden categories filtered) for topic clustering and taxonomy work, fetched in batched calls at no per-article cost
- Related-article graph (opt-in) --
includeRelatedattaches Wikipedia's own related-pages graph to each result, turning the actor into a lightweight knowledge-graph builder - Multi-language coverage (opt-in) --
compareLanguagesreports how broadly a topic is covered across language editions, with a 0-100 coverage score - Reading order -- the run summary returns a ranked "read these in this order" list across all results
- Routing recommendation -- a per-result
recommendationenum (recommended/reference/skip) plus a run-levelprimaryArticlepointer telling you the single best match for your query - Plain-English summary -- every record includes a one-line, LLM-quotable
summaryan agent can read without joining fields - Run summary record -- a final
recordType: "summary"row (mirrored to theSUMMARYkey-value record) with coverage counts, article-type breakdown, recommendation breakdown, average and top score, and the primary article - Output profiles --
minimal/standard/fullcontrol how much detail ships per record, from lean agent-friendly rows to the full per-component scoring breakdown - Summary enrichment via the Wikipedia REST API adds plain-text extracts, descriptions, Wikidata IDs, and thumbnails for each result
- 15 language editions -- English, German, French, Spanish, Japanese, Chinese, Russian, Portuguese, Italian, Arabic, Dutch, Korean, Polish, Swedish, and Vietnamese
- Up to 500 results per search query in a single run, matching the Wikipedia API's maximum capacity
- Wikidata cross-referencing -- use the returned
wikidataIdto link articles across language editions and external knowledge bases like DBpedia - Graceful error handling -- if an individual summary enrichment request fails, the actor skips it and continues processing remaining results without crashing
Implementation details (HTML-cleaned snippets, the 200ms enrichment throttle, flat self-contained records, retry and rate-limit handling) are covered in the "How it works" and "Responsible use" sections below.
How to use Wikipedia Research Intelligence
Using the Apify Console
- Go to the Wikipedia Research Intelligence actor page on Apify and click Try for free.
- Enter your Search Query -- the topic or keywords you want to find articles about (e.g., "machine learning", "Roman Empire", "climate change").
- Select a Language from the dropdown. The default is English (
en). All 15 supported language editions are available in the selector. - Choose whether to Include Article Summary. Enabling this adds a plain-text extract, description, Wikidata ID, and thumbnail for each result. Disabling it makes runs faster but returns less data per article.
- Set the Max Results to control how many articles to return (1 to 500, default 20).
- Click Start to run the actor.
- When the run finishes, view your results in the Dataset tab. Export as JSON, CSV, Excel, or access programmatically via the Apify API.
- Optionally, set up a Schedule to run the same search on a recurring basis (daily, weekly, monthly) to track content changes over time.
Using the API
You can also start the actor programmatically by sending a POST request with your input as JSON. See the API & Integration section below for complete Python, JavaScript, and cURL examples. The API supports both synchronous execution (wait for results) and asynchronous execution (start the run and poll for results later).
Input parameters
| Field | Type | Required | Default | Description |
|---|---|---|---|---|
query | String | Yes | -- | Search query for Wikipedia articles. Supports natural language phrases and specific topic names. |
language | String | No | en | Wikipedia language code. Options: en, de, fr, es, ja, zh, ru, pt, it, ar, nl, ko, pl, sv, vi. |
includeSummary | Boolean | No | true | Fetch article summary/extract for each result via the REST API. Richer data and higher scoring confidence, but slower runs. |
maxResults | Integer | No | 20 | Maximum number of articles to return. Range: 1--500 (Wikipedia API limit). |
outputProfile | String | No | standard | How much detail per record: minimal (title, URL, recommendation, score, summary), standard (the above plus type, entity type, categories, tier, word count, freshness, metadata), or full (everything, including the per-component scoring breakdown and confidence object). |
intent | String | No | general | Scoring lens: general (balanced), research (depth-first), recent (freshness-first), or overview (relevance-first). Reweights the same five signals; does not change which articles are returned. |
includeRelated | Boolean | No | false | Attach Wikipedia's related-pages graph to each result. Adds one request per article (slower); useful for knowledge-graph building. |
compareLanguages | Array | No | [] | Additional language codes (e.g. ["de","fr","ja"]) to compare topic coverage. Adds a languageCoverage map and coverageScore to the run summary. Main results still come from language. |
expandTopic | Boolean | No | false | Build a research-surface topic map (core concepts + people + organizations + related fields) as a separate topic-map record. Adds a few requests. |
emitResearchBrief | Boolean | No | true | Emit a single research-brief record synthesising the run into a 5-minute understanding of the topic. On by default; turn off for raw rows only. |
Input example
{
"query": "quantum computing",
"language": "en",
"includeSummary": true,
"maxResults": 25,
"outputProfile": "standard",
"intent": "research",
"includeRelated": false,
"compareLanguages": ["de", "fr", "ja"],
"expandTopic": true,
"emitResearchBrief": true
}
Tips for best results
- Use specific, multi-word queries -- "machine learning neural networks" returns more targeted results than "computers". Wikipedia's search engine ranks by relevance, so precise phrasing matters.
- Disable summaries when speed matters -- If you only need titles, URLs, word counts, and snippets, set
includeSummarytofalseto skip per-article REST API calls and finish much faster. - Search in the relevant language -- An article may exist in one Wikipedia edition but not another. For regionally significant topics, use the appropriate language code (e.g.,
jafor Japanese history topics,defor German political figures). - Leverage Wikidata IDs -- The
wikidataIdfield (e.g.,Q3552) uniquely identifies a concept across all Wikipedia language editions and links to external structured knowledge bases like DBpedia, Google Knowledge Graph, and Freebase. - Combine with scheduling -- Use Apify's scheduler to run the same query weekly or daily and track how article word counts and content evolve over time.
- Start with fewer results -- Begin with 10-20 results to verify your query returns relevant articles before scaling up to 500.
Output
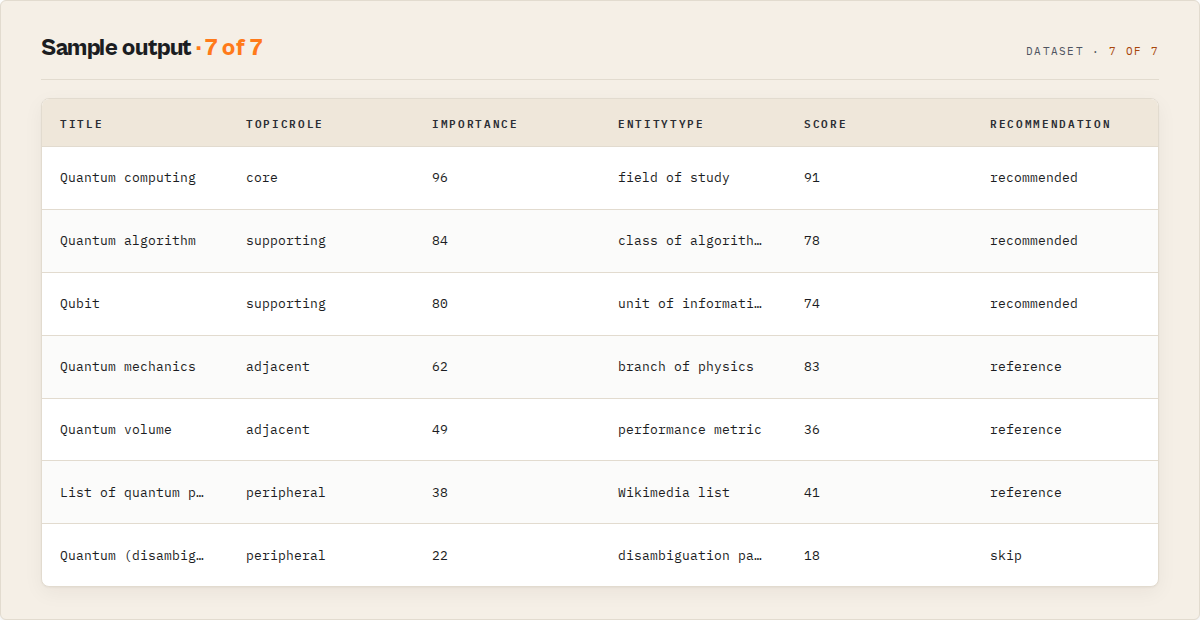
Output example -- article record (standard profile)
Each article is a flat JSON object in the Apify dataset, with the intelligence layer attached:
{
"recordType": "article",
"schemaVersion": "2.0.0",
"title": "Quantum computing",
"pageId": 25202,
"recommendation": "recommended",
"topicRole": "core",
"importance": 96,
"importanceFactors": { "searchRelevance": 45, "primacy": 20, "connectivity": 16, "recommendationFit": 15 },
"score": 91,
"scoreTier": "excellent",
"articleType": "comprehensive",
"entityType": "field of study",
"entityTypeId": "Q2267705",
"isPrimaryConcept": true,
"why": ["Primary concept for the query", "Top relevance match", "Comprehensive article (12,485 words)", "High quality score (91)"],
"categories": ["Quantum computing", "Quantum information science", "Theoretical computer science"],
"categoryCount": 3,
"description": "Computation using quantum-mechanical phenomena",
"extract": "A quantum computer is a computer that exploits quantum mechanical phenomena...",
"snippet": "A quantum computer is a computer that exploits quantum mechanical phenomena. On small scales...",
"summary": "Quantum computing — comprehensive article (12,485 words), relevance #1, last edited 14 days ago. Recommended read.",
"wordCount": 12485,
"relevanceRank": 0,
"recencyDays": 14,
"freshness": "fresh",
"wikidataId": "Q3552",
"articleUrl": "https://en.wikipedia.org/wiki/Quantum_computing",
"thumbnailUrl": "https://upload.wikimedia.org/wikipedia/commons/thumb/6/6e/Bloch_sphere.svg/320px-Bloch_sphere.svg.png",
"relatedArticles": null,
"extractedAt": "2026-06-08T14:30:12.456Z"
}
The full profile additionally includes sizeBytes, timestamp, and a confidence object with the per-component scoring breakdown (relevance, depth, structure, recency, metadata). The minimal profile keeps only recordType, schemaVersion, title, articleUrl, recommendation, score, and summary. When includeRelated is enabled, relatedArticles is an array of { title, description, url }. When includeSummary is false, the enrichment fields (description, extract, thumbnailUrl) are null and scoring confidence drops accordingly (the metadata signal is unavailable), but the score, type, entity type, categories, and recommendation are still computed (entity type and categories come from batched calls keyed on the page ID, so they do not require summaries).
Output example -- run summary record
The final record in every run is a summary (also mirrored to the SUMMARY key-value record):
{
"recordType": "summary",
"schemaVersion": "2.0.0",
"query": "quantum computing",
"language": "en",
"intent": "research",
"topic": { "canonicalName": "Quantum computing", "entityType": "field of study" },
"coverage": { "requested": 20, "returned": 20, "totalAvailable": 5962 },
"primaryArticle": { "title": "Quantum computing", "articleUrl": "https://en.wikipedia.org/wiki/Quantum_computing", "score": 91 },
"articleTypeBreakdown": { "disambiguation": 1, "list": 2, "stub": 3, "substantial": 9, "comprehensive": 5 },
"recommendationBreakdown": { "recommended": 11, "reference": 6, "skip": 3 },
"readingOrder": [
{ "rank": 1, "title": "Quantum computing", "articleUrl": "https://en.wikipedia.org/wiki/Quantum_computing", "score": 91, "recommendation": "recommended" },
{ "rank": 2, "title": "Quantum algorithm", "articleUrl": "https://en.wikipedia.org/wiki/Quantum_algorithm", "score": 78, "recommendation": "recommended" }
],
"avgScore": 64,
"topScore": 91,
"contentGap": {
"avgWordCount": 6200,
"deepestSubtopics": [
{ "title": "Quantum computing", "wordCount": 12485 },
{ "title": "Quantum algorithm", "wordCount": 8900 }
],
"underdevelopedSubtopics": [
{ "title": "Quantum volume", "wordCount": 420 }
]
},
"languageCoverage": [
{ "language": "en", "totalHits": 5962 },
{ "language": "de", "totalHits": 1840 },
{ "language": "fr", "totalHits": 1502 },
{ "language": "ja", "totalHits": 980 }
],
"coverageScore": 100,
"summary": "Found 20 articles for \"quantum computing\" (5,962 total matches). Best result: Quantum computing (score 91). 11 recommended, 6 reference, 3 low-priority.",
"extractedAt": "2026-06-08T14:30:13.001Z"
}
Output example -- topic-map record
When expandTopic is enabled, a topic-map record (also mirrored to the TOPIC_MAP key-value record) maps the research surface around the query:
{
"recordType": "topic-map",
"schemaVersion": "2.0.0",
"query": "quantum computing",
"language": "en",
"coreConcepts": ["Quantum computing", "Quantum algorithm", "Qubit"],
"relatedConcepts": ["Quantum entanglement", "Superposition principle"],
"people": ["Peter Shor", "David Deutsch"],
"organizations": ["IBM Quantum", "Google Quantum AI"],
"relatedFields": ["Quantum mechanics", "Theoretical computer science"],
"events": [],
"composition": { "concepts": 5, "people": 2, "organizations": 2, "relatedFields": 2, "events": 0 },
"extractedAt": "2026-06-08T14:30:13.500Z"
}
Output example -- research-brief record
Emitted by default (emitResearchBrief), also mirrored to the RESEARCH_BRIEF key-value record. The 5-minute understanding of the topic, assembled deterministically from the run's own data:
{
"recordType": "research-brief",
"schemaVersion": "2.0.0",
"query": "quantum computing",
"language": "en",
"intent": "research",
"topic": { "canonicalName": "Quantum computing", "entityType": "field of study" },
"primaryConcept": { "title": "Quantum computing", "articleUrl": "https://en.wikipedia.org/wiki/Quantum_computing", "score": 91, "entityType": "field of study" },
"executiveSummary": "Start with Quantum computing (field of study). 4 core and 7 supporting articles for \"quantum computing\". 2 key people. 2 organizations. Deepest coverage: Quantum computing. Thinly covered: Quantum volume.",
"suggestedQueries": ["Quantum algorithm", "Qubit", "Quantum information science", "Quantum error correction"],
"whatMatters": ["Quantum computing", "Quantum algorithm", "Qubit"],
"learningPath": {
"startHere": ["Quantum computing"],
"nextRead": ["Quantum algorithm", "Qubit"],
"deeperDives": ["Topological quantum computer"],
"experts": ["Peter Shor", "David Deutsch"],
"organizations": ["IBM Quantum", "Google Quantum AI"]
},
"readingOrder": [
{ "rank": 1, "title": "Quantum computing", "articleUrl": "https://en.wikipedia.org/wiki/Quantum_computing", "score": 91, "recommendation": "recommended" }
],
"coreConcepts": ["Quantum computing", "Quantum algorithm"],
"keyPeople": ["Peter Shor", "David Deutsch"],
"keyOrganizations": ["IBM Quantum", "Google Quantum AI"],
"relatedFields": ["Quantum mechanics", "Theoretical computer science"],
"gaps": ["Quantum volume"],
"coverage": { "requested": 25, "returned": 25, "totalAvailable": 5962 },
"languageCoverage": null,
"coverageScore": null,
"extractedAt": "2026-06-08T14:30:13.600Z"
}
Output fields -- article record
| Field | Type | Description |
|---|---|---|
recordType | String | "article" for result rows, "summary" for the run summary, "warning" / "error" for edge cases |
schemaVersion | String | Output shape version (semver), currently "2.0.0" |
title | String | Article title as displayed on Wikipedia |
pageId | Integer | Unique Wikipedia page identifier |
recommendation | String | Routing decision: recommended, reference, or skip |
topicRole | String | Role relative to the query: core (the concept), supporting (strongly related), adjacent (context), peripheral (tangential) |
importance | Integer | Topic-centrality score 0-100 -- how central this result is to the topic. Distinct from score: a core stub is high importance, low score |
importanceFactors | Object | Breakdown of importance: searchRelevance, primacy, connectivity, recommendationFit (points summing to the score) |
why | Array | Plain-English reasons this result landed at its role/rank |
score | Integer | Article-quality score, 0-100 (depth, structure, recency, relevance, metadata) |
scoreTier | String | Banded score: excellent (>=75), good (>=55), fair (>=35), poor (<35) |
articleType | String | comprehensive, substantial, stub, list, or disambiguation |
entityType | String or null | Wikidata semantic type (instance of / P31), e.g. business, film, human. Null when no Wikidata link |
entityTypeId | String or null | Wikidata QID of the entity type |
isPrimaryConcept | Boolean | True when this is the top-ranked substantive page for the query (the canonical article) |
categories | Array | Visible Wikipedia categories (maintenance/hidden excluded) |
categoryCount | Integer | Number of visible categories |
relatedArticles | Array or null | Related-pages graph { title, description, url } when includeRelated is on; otherwise null |
description | String or null | Short article description from Wikidata (requires includeSummary) |
extract | String or null | Plain-text summary of the article introduction (requires includeSummary) |
snippet | String | Search-relevant excerpt with query term context, HTML stripped |
summary | String | One-line, LLM-quotable summary of the article and its recommendation (<=280 chars) |
wordCount | Integer | Total word count of the full article |
relevanceRank | Integer | 0-based position in Wikipedia's relevance-ranked results |
recencyDays | Integer or null | Days since the article's last edit |
freshness | String | fresh (<=30d), recent (<=180d), aging (<=730d), stale, or unknown |
wikidataId | String or null | Wikidata entity ID for cross-language linking (requires includeSummary) |
articleUrl | String | Canonical URL to the Wikipedia article |
thumbnailUrl | String or null | URL to the article's lead thumbnail image (requires includeSummary) |
sizeBytes | Integer | Article page size in bytes (full profile only) |
timestamp | String | ISO 8601 timestamp of the article's last edit (full profile only) |
confidence | Object | Score confidence { score, level, components[] } (full profile only) |
extractedAt | String | ISO 8601 timestamp of when the data was extracted by this actor |
Output fields -- summary record
| Field | Type | Description |
|---|---|---|
recordType | String | Always "summary" |
query / language | String | Echoed input |
intent | String | Scoring lens used (general / research / recent / overview) |
coverage | Object | { requested, returned, totalAvailable } |
primaryArticle | Object or null | The single best substantial/comprehensive result { title, articleUrl, score } |
articleTypeBreakdown | Object | Count of each article type in the run |
recommendationBreakdown | Object | Count of each recommendation in the run |
readingOrder | Array | Ranked "read these in this order" list { rank, title, articleUrl, score, recommendation } |
avgScore / topScore | Integer | Average and highest quality score across results |
contentGap | Object | SEO topic-depth view: avgWordCount, deepestSubtopics[], underdevelopedSubtopics[] |
languageCoverage | Array or null | Per-language hit counts when compareLanguages is set; otherwise null |
coverageScore | Integer or null | 0-100 share of compared languages with results; null when no comparison requested |
summary | String | Plain-English run summary |
Use cases
- Academic research -- Quickly gather structured metadata on hundreds of Wikipedia articles for a literature survey, content analysis, or knowledge mapping project. Export word counts and timestamps to analyze article maturity and editorial activity across topics.
- SEO and content strategy -- Identify high-authority Wikipedia pages related to your target keywords. Use word counts and article sizes to gauge topic depth and find content gaps that your own articles could fill. Compare article coverage across multiple keywords to prioritize content creation.
- Knowledge base construction -- Use Wikidata IDs and article extracts as a foundation for building structured knowledge graphs, chatbot training data, FAQ databases, or reference systems. The Wikidata IDs enable linking to external datasets like DBpedia and Google Knowledge Graph.
- Multilingual content analysis -- Compare how topics are covered across different Wikipedia language editions. Track which articles exist in which languages and measure their relative depth by word count. Useful for localization teams and international content strategies.
- Trend monitoring -- Schedule recurring searches on current event topics to track when new articles appear, how quickly they grow in word count, and when they stabilize after initial creation. Combine with the Website Change Monitor actor for deeper tracking.
- Data enrichment -- Feed Wikipedia summaries, descriptions, and thumbnails into existing datasets to add context to company names, scientific terms, geographic locations, or historical events in your applications. The flat JSON output makes it easy to join with existing data.
API & Integration
Python
from apify_client import ApifyClient
client = ApifyClient("YOUR_API_TOKEN")
run = client.actor("CkESJHQpPf1x2RL68").call(run_input={
"query": "renewable energy",
"language": "en",
"includeSummary": True,
"maxResults": 50,
})
# Iterate over results and process each article
for item in client.dataset(run["defaultDatasetId"]).iterate_items():
print(f"{item['title']} — {item['wordCount']} words")
print(f" URL: {item['articleUrl']}")
print(f" Description: {item['description']}")
print(f" Wikidata: {item['wikidataId']}")
print()
JavaScript
import { ApifyClient } from "apify-client";
const client = new ApifyClient({ token: "YOUR_API_TOKEN" });
const run = await client.actor("CkESJHQpPf1x2RL68").call({
query: "renewable energy",
language: "en",
includeSummary: true,
maxResults: 50,
});
const { items } = await client.dataset(run.defaultDatasetId).listItems();
items.forEach((item) => {
console.log(`${item.title} — ${item.wordCount} words`);
console.log(` URL: ${item.articleUrl}`);
console.log(` Description: ${item.description}`);
console.log(` Wikidata: ${item.wikidataId}`);
console.log();
});
cURL
# Start the actor run
curl "https://api.apify.com/v2/acts/CkESJHQpPf1x2RL68/runs" \
-X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_TOKEN" \
-d '{
"query": "renewable energy",
"language": "en",
"includeSummary": true,
"maxResults": 50
}'
# Retrieve results from the dataset (after the run completes)
curl "https://api.apify.com/v2/datasets/DATASET_ID/items?format=json" \
-H "Authorization: Bearer YOUR_API_TOKEN"
Integrations
Wikipedia Research Intelligence outputs clean, structured JSON that integrates seamlessly with Apify's ecosystem and third-party tools:
- Zapier -- Trigger workflows in 5,000+ apps whenever a Wikipedia search run completes. Automatically route new results to your CRM, project management tool, or notification system.
- Make (Integromat) -- Build multi-step automations that process Wikipedia data alongside other sources. Combine with other Apify actors for enriched research pipelines.
- Google Sheets -- Export results directly to a spreadsheet for collaborative review and filtering using Apify's built-in integration. Ideal for team research projects.
- Webhooks -- Receive HTTP POST notifications when runs finish, enabling real-time data pipelines and event-driven architectures.
- Slack / Email -- Set up alerts to notify your team when new results match specific criteria or when scheduled searches detect changes.
- Apify API -- Access results programmatically in any language via the REST API or official client libraries for JavaScript, Python, and PHP. Supports both synchronous and asynchronous execution patterns.
Use in Dify
Drop this actor into Dify workflows via the Apify plugin's Run Actor node. Each result comes back scored, classified, and routed as structured JSON -- recommended / reference / skip plus the articleType and scoreTier enums your downstream node branches on. A generic Wikipedia scraper pointed at the same query returns a flat list of rows; this returns the decision about which row to read.
- Actor ID:
ryanclinton/wikipedia-article-search - Sample input (pick the canonical article for a topic, agent-friendly output):
{
"query": "transformer neural network",
"language": "en",
"includeSummary": true,
"maxResults": 15,
"outputProfile": "minimal"
}
A Dify if/else node routes cleanly on the stable enums, with no prose parsing:
topicRole == "core"-> the article that is the concept; pass itsextract+articleUrlinto the next LLM/answer nodetopicRole == "supporting"/"adjacent"-> keep as background/context sourcestopicRole == "peripheral"-> drop from the context windowarticleType == "disambiguation"-> branch to a "needs clarification" path instead of answeringentityType == "business"(orfilm/human/ …) -> route the query by what the topic actually is, not just its titlerecordType == "summary"-> readprimaryArticlefor the single best result,readingOrderfor the ranked sequence, andcoveragefor how exhaustive the search wasrecordType == "topic-map"-> readcoreConcepts/people/organizations/relatedFieldsto fan out a research workflow across the whole topic surfacerecordType == "research-brief"-> the single most useful object for an agent: readprimaryConcept,executiveSummary,whatMatters, andreadingOrderto understand a topic in one step, then branch into deeper retrieval
Sort the article records by importance for "what's central to this topic" or by score for "what's the best-written article" -- two different questions, two fields.
The per-record summary string is written to be quoted verbatim by an LLM node -- no field-joining required -- and the run summary record gives an agent a one-line picture of the whole search before it spends tokens reading individual extracts. Set outputProfile: "minimal" to keep agent context lean.
How it works
The actor combines search relevance, rich article metadata, and a deterministic scoring layer in one pipeline:
Input Query --> MediaWiki Search --> Batched metadata --> REST Enrichment --> Score + Classify --> Structured Output
(/w/api.php) (categories + (/api/rest_v1/) (deterministic) (Apify Dataset)
Wikidata P31)
Step 1: Search phase
The actor sends your query to the MediaWiki Action API endpoint (/w/api.php?action=query&list=search) on the selected language edition of Wikipedia. The API performs a full-text search across all articles in that edition and returns a ranked list of matching results. Each result includes basic metadata: article title, page ID, word count, page size in bytes, last-edit timestamp, and a search snippet showing where your query terms appear.
Step 2: Enrichment phase (optional)
If includeSummary is enabled, the actor iterates through each search result and calls the Wikipedia REST API (/api/rest_v1/page/summary/{title}) to fetch additional data for that article. This enrichment adds: a plain-text extract of the article's introductory section, a short Wikidata description, the Wikidata entity ID, a thumbnail image URL, and the canonical article URL. A 200ms delay between requests ensures compliance with Wikipedia's rate-limit policies.
Step 3: Data cleaning
Search snippets from the MediaWiki API contain raw HTML tags and encoded entities. The actor cleans these using a built-in stripHtml() function that removes all HTML tags and decodes common entities including ", &, <, >, and '. This ensures that every snippet field in the output contains clean, readable plain text.
Step 4: Scoring & classification (deterministic, no extra API calls)
Every result is scored and classified purely from data already fetched, so the intelligence layer adds zero network latency. The score (0-100) is a weighted blend of five components: search relevance (rank position), article depth (word count), page structure (size in bytes), edit recency (days since last edit), and metadata completeness (description, extract, Wikidata ID, thumbnail present). Each result is classified by articleType (comprehensive / substantial / stub / list / disambiguation) and assigned a recommendation (recommended / reference / skip). The scoring is fully deterministic -- the same article always produces the same score -- with no LLM or randomness in the path. When summaries are disabled, the metadata component is dropped and the remaining weights are renormalised so scores stay comparable, with confidence lowered to reflect the missing signal.
Step 5: Output
Each article is pushed to the Apify dataset as a flat JSON object, followed by a run summary record. The dataset is immediately available for export in JSON, CSV, Excel, or XML format through the Apify Console. You can also access it programmatically via the Apify API or stream it into connected integrations.
The actor identifies itself with the User-Agent string ApifyWikipediaSearch/1.0 as required by the Wikimedia API policy. If any individual summary enrichment request fails (e.g., due to a network timeout or a redirect page), the actor gracefully skips that enrichment and continues processing remaining results.
Performance & cost
Wikipedia Research Intelligence uses minimal compute resources (256 MB memory). The primary factor affecting run time is whether summary enrichment is enabled, since each article requires an additional API call with a 200ms throttle delay.
| Scenario | Results | Est. time | Est. cost |
|---|---|---|---|
| Quick search, no summaries | 20 | ~3 seconds | ~$0.001 |
| Standard search with summaries | 20 | ~10 seconds | ~$0.001 |
| Medium batch with summaries | 100 | ~30 seconds | ~$0.002 |
| Large batch with summaries | 500 | ~2 minutes | ~$0.005 |
| Large batch, no summaries | 500 | ~5 seconds | ~$0.001 |
The Wikipedia API itself is completely free with no usage fees or rate-limit charges. Your only cost is Apify platform compute time, making this actor one of the most cost-efficient data extraction tools available. Free-tier Apify accounts include $5 of monthly platform credits, which is enough for thousands of Wikipedia searches. Even at maximum scale (500 articles with summaries), a single run costs less than one cent.
Limitations
- 500 results per run -- The Wikipedia search API returns a maximum of 500 results per query. This is a hard limit imposed by the MediaWiki API. For broader coverage, run multiple searches with different query variations or narrower subtopics.
- No full article text -- The actor returns article summaries (introduction paragraphs), not the complete article body. The
extractfield typically contains the first 1-3 paragraphs. For full content extraction, consider a dedicated web scraping approach. - Search relevance depends on Wikipedia -- Result ranking is controlled by Wikipedia's internal CirrusSearch algorithm. The actor does not re-rank, deduplicate, or filter results beyond what the API returns.
- Language editions vary in coverage -- Smaller language Wikipedias may have fewer articles or less detailed content on certain topics compared to the English edition, which has over 6.8 million articles.
- Summary enrichment adds latency -- The 200ms throttle delay per article means 500 results with summaries takes approximately 2 minutes. Disable summaries if speed is critical for your workflow.
- No disambiguation handling -- If your query matches a disambiguation page, it will appear in results like any other article. Check the
descriptionfield to identify disambiguation pages (they typically say "Wikimedia disambiguation page"). - Thumbnails not always available -- Not every Wikipedia article has a lead image. Stub articles, lists, and newly created pages often return
nullforthumbnailUrl. - Single query per run -- Each run processes one search query. To search for multiple different topics, you need to start separate runs for each query.
Responsible use
This actor accesses Wikipedia's free, public API and follows Wikimedia's API etiquette guidelines. Please use it responsibly:
- Rate limiting -- The built-in 200ms delay between enrichment requests prevents excessive load on Wikipedia's servers, staying well within Wikimedia's recommended request rates for automated tools.
- User-Agent identification -- Every request includes the
ApifyWikipediaSearch/1.0User-Agent header as required by the Wikimedia API usage policy. This allows Wikimedia to identify and contact the operator if needed. - Content licensing -- Wikipedia content is licensed under Creative Commons Attribution-ShareAlike 4.0. If you republish article extracts or descriptions, provide proper attribution and comply with the license terms. Metadata fields like
wordCountandpageIdare factual data not subject to copyright. - No scraping of full articles -- This actor uses official API endpoints rather than scraping rendered HTML pages, which aligns with Wikimedia's preferred access method for programmatic data retrieval.
- Minimal data footprint -- The actor retrieves only metadata and summaries, not full article HTML, keeping data transfer and storage requirements low.
- Fair scheduling -- If you set up recurring scheduled runs, use reasonable intervals (daily or weekly rather than hourly) to avoid unnecessary load on the Wikipedia API infrastructure.
FAQ
Do I need a Wikipedia API key? No. Wikipedia's API is free and open. No API key, token, or registration is needed. You only need an Apify account to run the actor on the platform.
What is the difference between snippet and extract?
The snippet is a short, search-relevant excerpt returned by the MediaWiki Search API. It shows where your query terms appear in the article text and is always available. The extract is a longer, human-readable summary of the article's introductory section, fetched from the Wikipedia REST API. The extract is only available when includeSummary is enabled.
Can I search non-English Wikipedia editions? Yes. The actor supports 15 language editions: English, German, French, Spanish, Japanese, Chinese, Russian, Portuguese, Italian, Arabic, Dutch, Korean, Polish, Swedish, and Vietnamese. Select your language in the input settings.
How do Wikidata IDs work?
Each Wikipedia article is linked to a Wikidata entity (e.g., Q3552 for "Quantum computing"). This ID is universal across all Wikipedia language editions and connects to the broader Wikidata knowledge base. You can use it to find the same topic in other languages or to link Wikipedia data with other structured datasets like DBpedia.
Can I use this data commercially? Wikipedia content is licensed under CC BY-SA 4.0. You may use it commercially as long as you provide attribution and share derivative works under the same license. Always review the Wikimedia Terms of Use for your specific use case.
What happens if an article has no thumbnail?
The thumbnailUrl field will be null. Not all Wikipedia articles have a lead image. This is common for stub articles, lists, and recently created pages.
How do I get more than 500 results for a topic? Run the actor multiple times with different query variations. For example, instead of one search for "artificial intelligence", try separate searches for "machine learning", "deep learning", "neural networks", and "natural language processing" to cover the topic more broadly.
Does the actor handle redirects and disambiguation pages?
Redirect pages are resolved automatically by the MediaWiki Search API, so you will receive the target article rather than the redirect itself. Disambiguation pages, however, appear as regular search results. You can identify them by checking the description field, which typically contains "Wikimedia disambiguation page" for these entries.
What is the sizeBytes field useful for?
The sizeBytes field represents the total size of the article's wiki markup source in bytes. It is a rough proxy for article depth and detail. Articles with higher byte counts generally contain more sections, references, and inline content. This can be useful for filtering out stub articles or identifying the most comprehensive articles on a topic.
Related actors
| Actor | Description | Link |
|---|---|---|
| OpenAlex Research Paper Search | Search 250M+ academic papers from the OpenAlex database | View on Apify |
| Semantic Scholar Paper Search | Find academic papers with citation data and AI-generated summaries | View on Apify |
| Crossref Academic Paper Search | Search scholarly articles by DOI, author, title, or keyword | View on Apify |
| Internet Archive Search | Search the Internet Archive's collections of books, audio, video, and more | View on Apify |
| Wayback Machine Search | Look up historical snapshots of any web page over time | View on Apify |
| DBLP Publication Search | Search computer science publications from the DBLP bibliography | View on Apify |
| PubMed Biomedical Literature Search | Search biomedical and life science articles from the PubMed database | View on Apify |
| ArXiv Preprint Paper Search | Search preprint papers across physics, math, CS, and more from ArXiv | View on Apify |
| CORE Open Access Papers | Search 300M+ open access research papers and articles | View on Apify |
| Europe PMC Literature Search | Search European life science literature and abstracts | View on Apify |
Related actors
AI Cold Email Writer — $0.01/Email, Zero LLM Markup
Generates personalized cold emails from enriched lead data using your own OpenAI or Anthropic key. Subject line, body, CTA, and optional follow-up sequence — $0.01/email, zero LLM markup.
AI Outreach Personalizer — Emails with Your LLM Key
Generate personalized cold emails using your own OpenAI or Anthropic API key. Subject lines, opening lines, full bodies — tailored to each lead's role, company, and signals. $0.01/lead compute + your LLM costs. Zero AI markup.
Bulk Email Verifier — MX, SMTP & Disposable Detection at Scale
Verify email deliverability in bulk — MX records, SMTP mailbox checks, disposable detection (55K+ domains), role-based flagging, catch-all detection, domain health scoring (SPF/DKIM/DMARC), and confidence scores. $0.005/email, no subscription.
CFPB Complaint Intelligence — Vendor Risk & Screening
Turn 5M+ CFPB consumer complaints into decisions: screen companies pass / review / fail, score complaint-handling risk, monitor what changed since last run, benchmark cohorts, and build audit-ready due-diligence packs. Filter by company, product, state, and date. No API key.
Ready to try Wikipedia Research Intelligence — Topic Maps & Research Briefs?
Run it on your own Apify account. Apify offers a free tier with $5 of monthly credits.
Open on Apify Store