Research Integrity Screening MCP is an MCP (Model Context Protocol) server on ApifyForge. Research integrity MCP connecting AI agents to 7 academic sources. Screen researchers for retractions, detect paper mills, flag citation manipulation via Benford's law, audit NIH grant linkages. It costs $0.04 per screen_researcher_integrity. It exposes 9 tools: screen_researcher_integrity, check_publication_flags, assess_journal_quality, detect_citation_anomalies, audit_grant_research_link, compare_institutional_integrity, generate_integrity_report, assess_coauthor_network, verify_researcher_identity. Best for AI developers and agent builders who need structured real-world data inside Claude, Cursor, or other MCP-compatible clients. Not ideal for non-AI workflows or use cases that don't involve an MCP-compatible client. Maintenance pulse: 90/100. Last verified March 27, 2026. Built by Ryan Clinton (ryanclinton on Apify).
Research Integrity Screening MCP
Research Integrity Screening MCP is an MCP (Model Context Protocol) server available on ApifyForge at $0.04 per screen_researcher_integrity. Research integrity MCP connecting AI agents to 7 academic sources. Screen researchers for retractions, detect paper mills, flag citation manipulation via Benford's law, audit NIH grant linkages. Composite Integrity Score 0-100. Pay-per-event.
Best for AI developers and agent builders who need structured real-world data inside Claude, Cursor, or other MCP-compatible clients.
Not ideal for non-AI workflows or use cases that don't involve an MCP-compatible client.
Tools exposed
Each pricing event corresponds to a tool your AI agent can call through MCP.
screen_researcher_integrity · $0.04/callcheck_publication_flags · $0.04/callassess_journal_quality · $0.04/calldetect_citation_anomalies · $0.04/callaudit_grant_research_link · $0.04/callcompare_institutional_integrity · $0.04/callgenerate_integrity_report · $0.04/callassess_coauthor_network · $0.04/callverify_researcher_identity · $0.04/callExample prompts
Natural language queries you can ask your AI assistant that would trigger this MCP server.
What to know
- Requires an MCP-compatible client (Claude Desktop, Cursor, Windsurf, or similar).
- Tool call results depend on the availability of upstream public APIs.
- Requires an Apify account and API token for authentication.
Maintenance Pulse
90/100Cost Estimate
How many results do you need?
Pricing
Pay Per Event model. You only pay for what you use.
| Event | Description | Price |
|---|---|---|
| screen_researcher_integrity | $0.04 | |
| check_publication_flags | $0.04 | |
| assess_journal_quality | $0.04 | |
| detect_citation_anomalies | $0.04 | |
| audit_grant_research_link | $0.04 | |
| compare_institutional_integrity | $0.04 | |
| generate_integrity_report | $0.04 | |
| assess_coauthor_network | $0.04 | |
| verify_researcher_identity | $0.04 |
Example: 100 events = $4.50 · 1,000 events = $45.00
Documentation
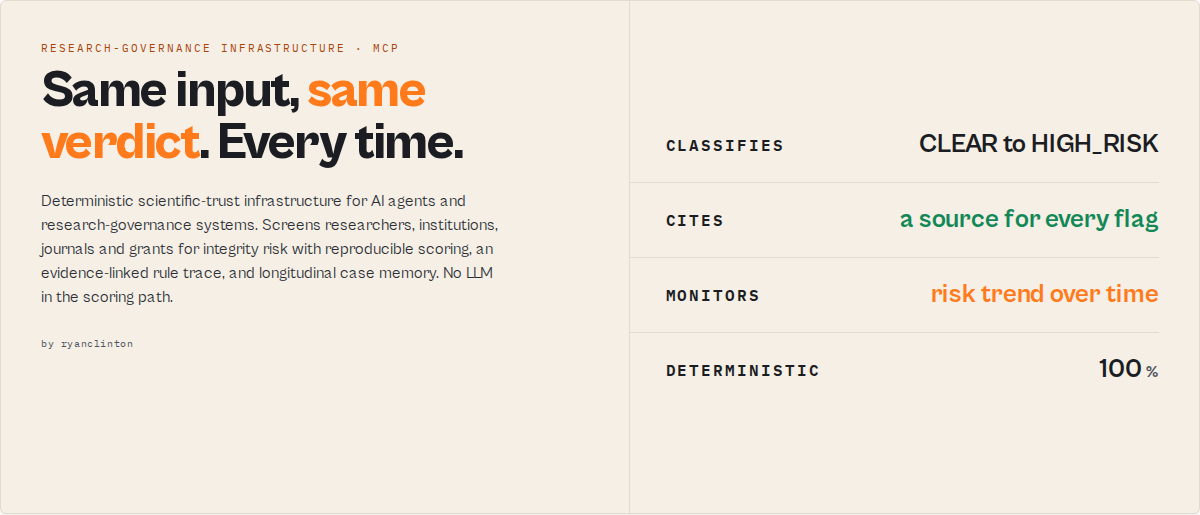
Research Integrity Screening MCP is deterministic scientific-trust infrastructure for AI agents and research-governance systems.
It screens researchers, institutions, journals, and grants for integrity risk using reproducible scoring, evidence-linked rules, longitudinal monitoring, and institutional case memory. Built for publishers, universities, grant agencies, and research-integrity operations teams.
The category
Research Integrity Screening MCP is deterministic research-governance infrastructure. Unlike plagiarism detectors (which only compare manuscript text) or LLM-based integrity assistants (which produce non-reproducible, non-auditable guesses), it produces reproducible, evidence-linked integrity assessments built for institutional review workflows: research-risk triage, audit-grade evidence, case-based review, and longitudinal research-risk monitoring.
In one sentence
Screen a researcher, institution, or paper topic for retractions, paper-mill output, citation manipulation, predatory-venue exposure, co-author network risk, and funding red flags in a single MCP tool call.
What you get from one call
generate_integrity_report fans out to all 7 sources in parallel and returns:
- Composite Integrity Score (0-100) and a CLEAR-to-HIGH_RISK verdict
- Four independent sub-scores: researcher integrity, paper-mill, journal quality, funding risk
evidence[]structured items naming the source and finding behind every flagdecisionprimitives:recommendedAction(auto_clear / monitor / manual_review / investigate / escalate), urgency, requiresHumanReviewconfidenceband reporting how many of the 7 sources actually returned datatopContributors: which of the four dimensions drove the scoreriskMemory: integrity-score trend and a 30-day linear projection across prior runs of the same entityrunSummary: exactly which sources delivered, failed, or were skipped
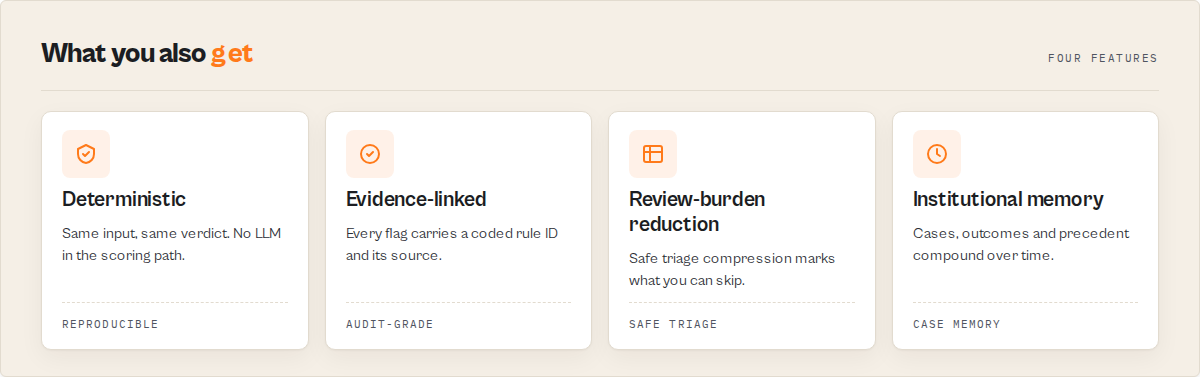
What makes this different
- Deterministic, no LLM in the scoring path. The same input produces the same verdict every time, so a result is defensible in front of an integrity committee.
- Source-honest. Every result names which of the 7 sources delivered data. A failed upstream source never silently reads as a clean bill of health.
- Stateful. Re-run the same entity on a schedule and the actor reports the integrity-score trend over time, not just a one-off snapshot.
Before vs after
| Without this MCP | With this MCP |
|---|---|
| Open OpenAlex, ORCID, PubMed, Semantic Scholar, Crossref, CORE, and NIH RePORTER in seven tabs | One tool call, all seven queried in parallel |
| Eyeball citation counts for manipulation | Benford's-law digit analysis plus a uniformity check, computed |
| Note retractions paper by paper | Retraction Watch flags (via Crossref) surfaced automatically |
| Re-screen from scratch every quarter | riskMemory reports the trend since the last screen |
| Inconsistent reviewer judgement | Deterministic, reproducible composite score |
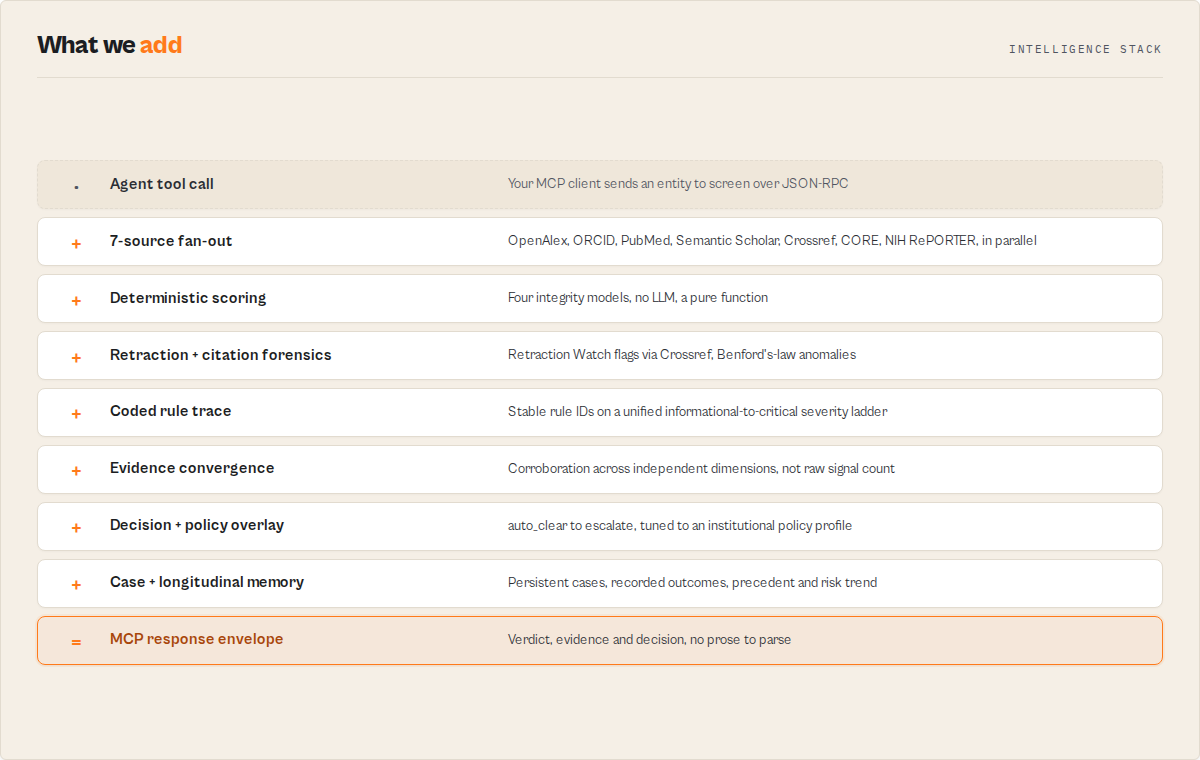
Architecture
7 scholarly sources → normalization layer → 4 scoring models + co-author / identity / topic models
(OpenAlex, ORCID, (one canonical paper ↓
PubMed, S2, shape, retraction flags) coded rule engine (RI / PM / JQ / FR / CX)
Crossref, CORE, ↓ ↓
NIH RePORTER) composite score + verdict decision primitives + confidence
↓ ↓
KV snapshot memory → trend + 30-day projection + drift events
↓
stable response envelope (recordType + runSummary + contentHash)
Why deterministic matters
This is the moat. The scoring path contains no LLM and no probabilistic model: the same researcher, screened twice on the same corpus, produces the same score, the same triggered rules, and the same verdict every time.
That matters because the output has to survive scrutiny. A research-integrity finding may be challenged by the researcher, reviewed by a committee, or cited in a funding decision. An "AI said it looks suspicious" verdict cannot be defended. A coded rule trace ("RI-001 fired because 6 retraction flags were found across these specific DOIs") can. Deterministic scoring gives you reproducibility, explainability, and an audit trail an LLM-driven tool cannot.
Why not an LLM-based integrity tool?
| LLM "integrity" tool | This actor | |
|---|---|---|
| Same input, same output | No (sampling varies) | Yes, always |
| Cite the exact source per flag | Rarely | Every flag links its rule ID and source |
| Defensible in a committee | "The model thought so" | Coded rule trace + DOIs |
| Can hallucinate a retraction | Yes | No, flags come from source data only |
| Auditable months later | No | scoringSchemaVersion + contentHash reproduce it |
In integrity review, a confident-but-wrong answer is worse than no answer. A hallucinated retraction or an invented co-author defames a real person. This actor never generates a claim: every signal is computed from source records, and every flag names the rule and the data behind it.
Severity taxonomy
Every triggered rule carries one severity from a single unified ladder, so downstream automation routes on one enum instead of per-model labels:
| Severity | Meaning | Typical action |
|---|---|---|
informational | No integrity signal | No action |
advisory | Minor signal worth noting | Monitor |
elevated | Pattern warrants a look | Human review |
severe | Strong signal | Open an investigation |
critical | Confirmed-level signal or HIGH_RISK verdict | Escalate |
ruleEngine.maxSeverity is the headline; ruleEngine.triggeredRules[] carries each coded rule (e.g. RI-001, PM-001) with its severity and rationale.
False-positive philosophy
This tool detects statistical anomalies, not misconduct. Every signal it raises has legitimate explanations: a high-output year can be a large consortium, a single-journal concentration can be an editor publishing in their own venue, a broad topic range can be a genuine polymath or two researchers sharing a name. The actor is built for triage, not accusation:
- Scores are conservative and evidence-linked, never a verdict on a person.
confidenceandrunSummarytell you how complete the screen was, so a thin screen is never mistaken for a clean one.requiredActionsnames the human checks to run next, rather than implying a conclusion.
Use the output to prioritise where a human integrity officer looks first. Do not use a score as the sole basis for an adverse decision.
The point is not to flag more. It is safe triage compression: reviewComplexity.safeToDeprioritize marks the low-risk cases a team can clear without escalation, so finite human review time goes to the cases that actually warrant it. The win for an overwhelmed integrity office is how many cases they can safely not escalate, with an auditable reason for each.
What this replaces
- Manual cross-database integrity screening across seven separate tabs
- Spreadsheet-based citation-anomaly review
- Ad hoc paper-mill triage
- Disconnected ORCID / OpenAlex / PubMed identity checks
- Inconsistent integrity-committee workflows and one-off reviewer judgement calls
- Lost institutional memory when reviewers change
Operational outcomes
Research Integrity Screening MCP helps research-governance teams:
- Reduce unnecessary escalations via safe triage compression (
reviewComplexity.safeToDeprioritize) - Standardize integrity-review decisions across reviewers with deterministic scoring and policy profiles
- Compress manual triage workload by routing only corroborated, high-confidence cases to humans
- Maintain audit-grade review trails with persistent cases and recorded outcomes
- Detect emerging research-risk drift early through longitudinal monitoring
- Preserve institutional consistency through accumulated case memory and precedent
Why institutions adopt this
Institutions adopt Research Integrity Screening MCP because it:
- standardizes integrity-review decisions across reviewers, committees, and time (reduces reviewer drift)
- reduces unnecessary escalations through safe triage compression
- preserves institutional memory via case-based governance: persistent cases, recorded review outcomes, and precedent
- creates audit-grade evidence trails that are reproducible and defensible
- detects emerging research-risk drift early through longitudinal monitoring
- scales research-governance operations without scaling headcount
Most integrity tools produce ephemeral analysis. This one accumulates governance memory: every case, outcome, and precedent compounds into institutional decision consistency.
Built for
Research integrity officers at universities, journal managing editors and publication-ethics committees, grant program officers (NIH / NSF / Wellcome), biotech and pharma due-diligence analysts, tenure and hiring committees, and scientific recruiters who need a reproducible integrity signal before a funding, publication, or hiring decision.
This server runs in Standby mode on the Apify platform. It orchestrates OpenAlex, ORCID, PubMed, Semantic Scholar, Crossref, CORE, and NIH Research Grants in parallel, applies four independent scoring models plus co-author-network and identity-verification models, and returns structured JSON your AI agent reasons over directly.
Questions this MCP answers
- "Has this researcher had any papers retracted?"
- "Is this grant applicant's publication record trustworthy?"
- "Does this author's citation pattern show signs of manipulation?"
- "Is this submission likely paper-mill output?"
- "Are any of this researcher's co-authors connected to retracted work?"
- "Is this ORCID identity consistent with the publication record, or could it be fabricated?"
- "How has this researcher's integrity profile changed since we last screened them?"
- "Which of these two institutions carries more research-integrity risk?"
For AI agents
- First tool to reach for when a prompt mentions research integrity, academic fraud, retractions, paper mills, citation manipulation, predatory journals, or grant due diligence.
- One call replaces seven lookups.
generate_integrity_reportcovers all sources; do not chain seven separate database tools. - Branch on
decision.recommendedAction, not the raw score.escalate/investigateroute to a human;monitorschedules a re-run;auto_clearneeds no action. Lowconfidenceis neverauto_clear. - Call
get_researcher_memoryfirst (it is free). Check accumulated history before paying for a fresh screen. - Read
runSummary.sourcesReturnedDatabefore trusting a CLEAR verdict: a clear result on 2 of 7 sources is low-confidence, and theconfidenceblock says so.
Use this MCP when an AI agent needs to:
- assess research trustworthiness or publication integrity
- triage an integrity-review queue and decide what to escalate
- investigate paper-mill or citation-manipulation indicators
- monitor research-risk drift for a researcher over time
- support grant, publication, or hiring due diligence
- generate audit-ready, evidence-linked integrity findings
- route suspicious cases to human review with a defensible rationale
What data can you access?
| Data Point | Source | Example |
|---|---|---|
| 📄 Publication metadata, citation counts, DOIs | OpenAlex | 247 papers, avg 18.3 citations |
| 👤 Researcher profiles, affiliations, employment history | ORCID | Dr. M. Petrov, MIT 2018-present |
| 🔬 Biomedical literature, MeSH terms, abstracts | PubMed | "Expression of Concern: oncology study" |
| 📊 AI citation analysis, influence scores, paper embeddings | Semantic Scholar | Influence score 94, 12 highly-cited papers |
| 🔗 DOI metadata, reference lists, journal metadata | Crossref | 10.1016/j.cell.2023.04.021 |
| 📂 Open access full-text repository coverage | CORE | 61% OA ratio across publication set |
| 💰 Federal grant awards, PI names, funding amounts | NIH Grants | R01CA123456, $1.2M, University of Chicago |
| 🚩 Retraction / correction / expression of concern flags | OpenAlex + PubMed | 3 retraction flags, 2 corrections detected |
| 📈 Publication velocity by year, year-over-year spike detection | OpenAlex + PubMed | 47 papers in 2022, velocity spike flagged |
| 🏦 Funding concentration index (HHI), terminated grant flags | NIH Grants | HHI 0.82, single-source dependency risk |
Why use Research Integrity Screening MCP?
Most institutional integrity review is:
- manual and slow (2-3 hours per researcher across OpenAlex, ORCID, PubMed, Semantic Scholar, Crossref, and NIH RePORTER)
- inconsistent across reviewers and not reproducible over time
- disconnected across data sources
- unable to preserve longitudinal case memory
This MCP turns that into one reproducible governance assessment. A single tool call queries all seven sources in parallel, applies deterministic scoring, and returns an evidence-linked verdict your AI agent acts on directly. It is built to reduce reviewer drift and standardize integrity-review decisions across committees, institutions, and time: research governance, not a one-off check.
- Scheduling: run periodic integrity sweeps on Apify Scheduler; flag new anomalies automatically
- API access: trigger screenings from Python, JavaScript, or any HTTP client using standard MCP protocol
- Parallel data fetching: all seven data sources queried simultaneously, not sequentially
- Monitoring: receive Slack or email alerts when HIGH_RISK verdicts are returned via Apify webhooks
- Integrations: pipe results into Notion, Airtable, or any webhook-compatible grant management system
Features
Detection signals (all deterministic, all evidence-linked)
- Citation forensics: Benford's-law leading-digit analysis + coefficient-of-variation uniformity check across the full citation set.
- Paper-mill fingerprints: repeated 5-word title templates, single-journal over-concentration, low author-set diversity.
- Publication velocity: flags impossible annual output and 3x+ year-over-year spikes; surfaces inflection points on the timeline.
- Retraction detection: Retraction Watch flags (via Crossref) plus correction/erratum/expression-of-concern scanning across sources.
- Funding risk: paper-to-grant ratio outliers, HHI funder concentration, terminated/withdrawn grant detection.
- Co-author network: guilt-by-association on retracted collaborators, authorship-inflation trajectory, contamination score.
- Identity: ORCID completeness, ORCID-vs-OpenAlex consistency, name-ambiguity, identity-stability.
- Topic coherence: implausible field-range detection from research concepts.
Scoring + decision layer
- Four independent models (researcher integrity, paper-mill, journal quality, funding) → weighted composite + CLEAR-to-HIGH_RISK verdict, with CRITICAL/CONFIRMED_MILL hard overrides.
- Coded rule engine (
triggeredRules[]with stable IDs, categories, and a unifiedinformational→criticalseverity ladder). - Decision primitives (
recommendedAction, urgency, requiresHumanReview) + confidence band with per-axis decomposition. - Evidence-first synthesis: deterministic
integrityNarrative,mitigatingFactors(balancing evidence),evidenceDensity,crossSourceConsistency, and a structuredreviewPackage.
Monitoring layer
- KV snapshots →
riskMemory(trend, velocity, 30-day projection, drift events, rule persistence, signal freshness) and a freeget_researcher_memorytool.
Quickstart workflows
Publisher / editorial pipeline
submission arrives
→ check_publication_flags (author or topic)
→ if paperMillDetection.millLevel >= PROBABLE
→ generate_integrity_report (author)
→ branch on decision.recommendedAction: investigate/escalate → route to integrity editor
Grant agency / pre-award screening
applicant list
→ for each PI: get_researcher_memory (free) → skip if recently cleared
→ generate_integrity_report (PI)
→ sort by ruleEngine.maxSeverity; reviewPackage.suggestedQuestions seeds the reviewer file
Hiring / tenure committee
candidate
→ verify_researcher_identity (confirm ORCID before anything else)
→ generate_integrity_report (candidate)
→ read integrityNarrative + mitigatingFactors together; do not act on score alone
Use cases for research integrity screening
Pre-award grant screening
Grant programme officers at federal agencies and private foundations need to vet principal investigators before committing funds. A single screen_researcher_integrity call cross-references the applicant's publication record across four databases, applies Benford's law to their citation history, checks for retraction history, and verifies their ORCID profile. Officers get a scored, reproducible result they can attach to the application file, replacing hours of manual database lookups with a 90-second workflow.
Journal submission integrity review
Peer review coordinators can run check_publication_flags against a submitted manuscript's author list or topic before assigning reviewers. The paper mill detection model checks for repeated title templates, journal over-concentration in the author's history, and author-group uniformity, the three most reliable early indicators of paper mill output. A PROBABLE or higher mill score routes the submission to an integrity editor rather than standard peer review.
Faculty hiring due diligence
Provosts and department chairs screening candidates can run generate_integrity_report to receive a full composite view before making offers. The tool verifies ORCID identity, assesses publication velocity for implausible output rates, checks for retraction history, and evaluates whether the candidate's journal choices reflect credible venues. This takes 90 seconds rather than three days of reference checking.
Research institution partnership assessment
Before formalising a collaboration, compliance teams can run compare_institutional_integrity to benchmark two institutions side-by-side on journal quality and funding risk. The tool queries OpenAlex and NIH Grants for both entities simultaneously and returns a structured comparison with a quality advantage indicator, useful for partnership decision memos.
Funding portfolio audit
Agencies managing large research portfolios use audit_grant_research_link to identify grants where the paper-to-grant ratio is anomalously high or low, where grants have been terminated, or where funding concentration risk is elevated. Batch screening surfaces the highest-risk items for prioritised review without manually checking each grant record.
Citation manipulation investigation
When a researcher is under investigation for suspected citation ring participation, detect_citation_anomalies returns the full Benford's law digit-by-digit comparison with observed vs. expected percentages and deviation scores for digits 1-9. This provides the statistical evidence base that integrity committees need before escalating to formal misconduct proceedings.
How to connect this research integrity screening MCP
Claude Desktop
Add to your claude_desktop_config.json:
{
"mcpServers": {
"research-integrity-screening": {
"url": "https://research-integrity-screening-mcp.apify.actor/mcp",
"headers": {
"Authorization": "Bearer YOUR_APIFY_TOKEN"
}
}
}
}
Cursor, Windsurf, or Cline
Use the same URL and token in your MCP server settings panel. The server communicates via standard MCP protocol over HTTP POST to /mcp.
Python (via requests)
import requests
response = requests.post(
"https://research-integrity-screening-mcp.apify.actor/mcp",
headers={
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_APIFY_TOKEN"
},
json={
"jsonrpc": "2.0",
"method": "tools/call",
"params": {
"name": "generate_integrity_report",
"arguments": {"entity": "Dr. Marcus Webb Global Health Institute"}
},
"id": 1
}
)
result = response.json()
report = result["result"]["content"][0]["text"]
print(report)
JavaScript
const response = await fetch(
"https://research-integrity-screening-mcp.apify.actor/mcp",
{
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_APIFY_TOKEN"
},
body: JSON.stringify({
jsonrpc: "2.0",
method: "tools/call",
params: {
name: "screen_researcher_integrity",
arguments: { researcher: "Dr. Elena Sokolova 0000-0002-7831-4412" }
},
id: 1
})
}
);
const data = await response.json();
const report = JSON.parse(data.result.content[0].text);
console.log(`Integrity level: ${report.researcherIntegrity.integrityLevel}`);
console.log(`Score: ${report.researcherIntegrity.score}/100`);
cURL
# Screen a researcher for integrity flags
curl -X POST "https://research-integrity-screening-mcp.apify.actor/mcp" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_APIFY_TOKEN" \
-d '{
"jsonrpc": "2.0",
"method": "tools/call",
"params": {
"name": "generate_integrity_report",
"arguments": { "entity": "Dr. James Chen Stanford University" }
},
"id": 1
}'
Environment variables
All seven core data sources are free public academic APIs and need no key. One optional key unlocks a third paper source for paper-mill and journal-quality screening:
| Variable | Required | Purpose |
|---|---|---|
CORE_API_KEY | Optional | Free key from core.ac.uk/services/api. When set, the CORE open-access corpus joins check_publication_flags, assess_journal_quality, and generate_integrity_report. When absent, CORE is skipped and surfaced as a Skipped: note in runSummary.sourcesSkipped, the other sources still produce a full result. |
STANDBY_IDLE_TIMEOUT_SECS | Optional | Standby idle-shutdown window in seconds (default 300). The instance exits after this idle period to release platform compute; the next request cold-starts a fresh one. |
MCP tools
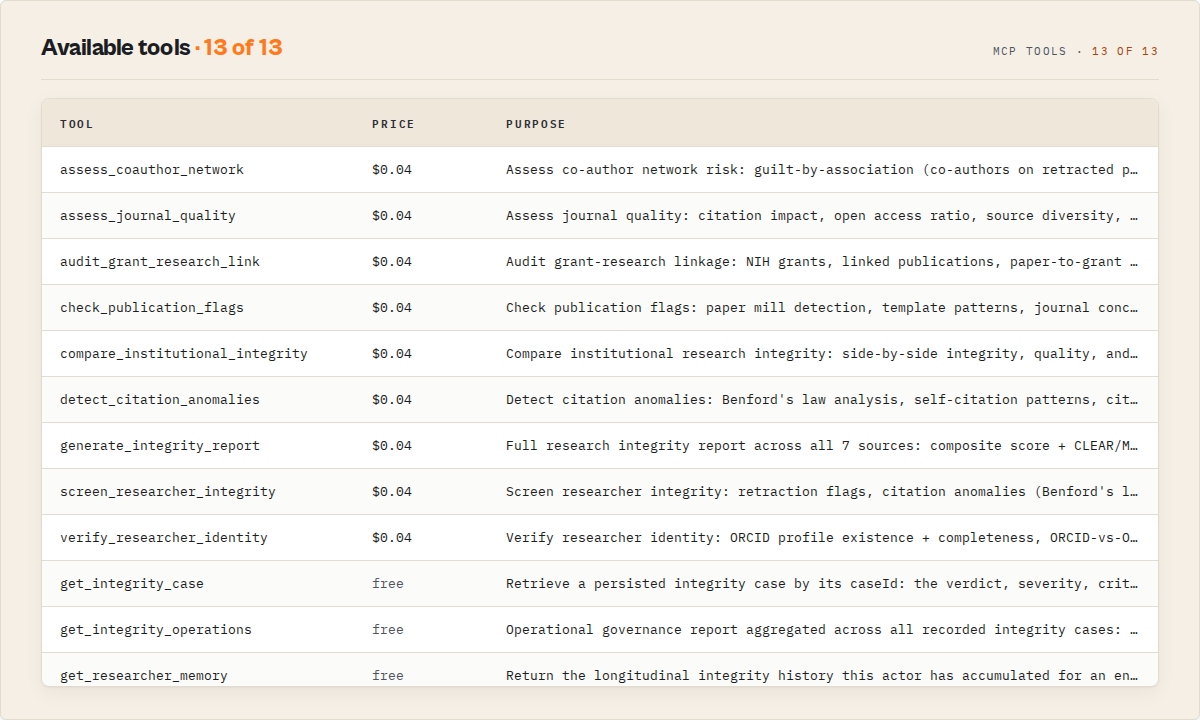
| Tool | Input | Price | What it returns |
|---|---|---|---|
screen_researcher_integrity | researcher, name or ORCID ID | $0.045 | Integrity Score 0-100, retraction flags, citation anomaly score, velocity red flags, ORCID verification status, CLEAN-to-CRITICAL level |
check_publication_flags | query, title, DOI, researcher, or topic | $0.045 | Paper mill score 0-100, template flags, journal concentration, author diversity, UNLIKELY-to-CONFIRMED_MILL verdict |
assess_journal_quality | query, journal name, topic, or researcher | $0.045 | Quality score 0-100, citation impact, open access ratio, source diversity, PREDATORY-to-ELITE verdict |
detect_citation_anomalies | researcher, name or institution | $0.045 | Benford's law digit 1-9 analysis: observed %, expected %, deviation per digit; citation min/max/mean |
audit_grant_research_link | researcher, PI name; topic, optional filter | $0.045 | Funding risk score, grant list, paper-to-grant ratio, HHI concentration, terminated grant flags, LOW-to-CRITICAL level |
compare_institutional_integrity | institution_a, institution_b | $0.045 | Side-by-side journal quality and funding risk for two institutions, quality advantage indicator |
assess_coauthor_network | researcher, name or ORCID ID | $0.045 | Co-author network risk: co-authors on retracted papers (guilt-by-association), authorship-inflation trajectory, collaboration concentration, top collaborators |
verify_researcher_identity | researcher, name or ORCID ID | $0.045 | ORCID profile completeness, ORCID-vs-OpenAlex publication-count consistency, name-ambiguity, identity-confidence level |
generate_integrity_report | entity, researcher, institution, or topic | $0.045 | Full composite report: 4 model scores, weighted composite 0-100, CLEAR-to-HIGH_RISK verdict, structured evidence[], confidence, decision, topContributors, and longitudinal riskMemory |
get_researcher_memory | entity, researcher, institution, or topic | Free | KV-only read of accumulated history for an entity: prior snapshots, integrity-score trend, and 30-day projection. No upstream fetch, no charge |
get_integrity_case | caseId | Free | Retrieve a persisted case: verdict, severity, critical signals, review state, and the full log of human review outcomes. The institutional-memory handle |
record_case_outcome | caseId, outcome, operatorId, optional notes | Free | Append a human review decision (confirmed_concern / false_positive / no_action / escalated / under_review / resolved) to a case. Builds the audit trail and feeds false-positive calibration |
get_integrity_operations | (none) | Free | Governance report across all recorded cases: totals, review-state distribution, resolution patterns (false-positive / confirmed / escalation rates), recurring dismissed-signal patterns. The system evaluating itself |
generate_integrity_report also accepts an optional policyProfile (standard / journal_editor / grant_reviewer / university_committee / strict / lenient) that adjusts the recommended action to your institution's risk tolerance. The base verdict never changes; the policyEvaluation block shows the policy-adjusted action.
Tool input reference
| Tool | Parameter | Type | Required | Description |
|---|---|---|---|---|
screen_researcher_integrity | researcher | string | Yes | Researcher name (e.g. "Dr. Wei Zhang Beijing University") or ORCID ID (e.g. "0000-0002-1234-5678") |
check_publication_flags | query | string | Yes | Paper title, DOI, researcher name, or research topic |
assess_journal_quality | query | string | Yes | Journal name, research topic, or researcher name |
detect_citation_anomalies | researcher | string | Yes | Researcher name or institution name |
audit_grant_research_link | researcher | string | Yes | Principal investigator name or institution |
audit_grant_research_link | topic | string | No | Research topic to narrow the NIH grant search |
compare_institutional_integrity | institution_a | string | Yes | First institution name (e.g. "Stanford University") |
compare_institutional_integrity | institution_b | string | Yes | Second institution name (e.g. "Duke University") |
assess_coauthor_network | researcher | string | Yes | Researcher name or ORCID ID |
verify_researcher_identity | researcher | string | Yes | Researcher name or ORCID ID |
generate_integrity_report | entity | string | Yes | Researcher name, institution, or paper topic for full cross-source screening |
get_researcher_memory | entity | string | Yes | Entity that was previously screened with generate_integrity_report |
Output example
{
"schemaVersion": "1.1",
"recordType": "integrity_report",
"captureTimestamp": "2026-05-21T10:14:02.118Z",
"actorVersion": "1.1.0",
"contentHash": "sha256:9f3c1a7e2b04d8a5",
"entity": "Dr. Marcus Webb Global Health Institute",
"compositeScore": 58,
"verdict": "INVESTIGATION_NEEDED",
"researcherIntegrity": {
"score": 42,
"publicationCount": 89,
"retractionFlags": 6,
"citationAnomalies": 5,
"velocityRedFlags": 3,
"integrityLevel": "SUSPICIOUS",
"signals": [
"Retraction/correction flags detected, 6 points",
"Citation distribution suspiciously uniform, potential citation manipulation",
"47 publications in 2021, suspiciously high output",
"Publication spike: 12 → 47 papers (2020 → 2021)"
]
},
"paperMill": {
"score": 44,
"suspiciousPatterns": 3,
"templateFlags": 4,
"millLevel": "PROBABLE",
"signals": [
"Repeated title pattern (4x): \"role of inflammation in...\", possible template",
"31 papers in single journal \"international journal of molecular biology\", over-concentration",
"Low author diversity, same author groups across many papers"
]
},
"journalQuality": {
"score": 34,
"totalPapers": 89,
"highCitationPapers": 8,
"openAccessRatio": 0.28,
"qualityLevel": "LOW",
"signals": [
"Low citation impact: avg 1.7, possible predatory venue"
]
},
"fundingRisk": {
"score": 38,
"grantCount": 3,
"flaggedGrants": 1,
"fundingConcentration": 0.78,
"riskLevel": "ELEVATED",
"signals": [
"High funding concentration, single-source dependency risk",
"1 terminated/withdrawn grants, compliance concern"
]
},
"allSignals": [
"Retraction/correction flags detected, 6 points",
"Citation distribution suspiciously uniform, potential citation manipulation",
"47 publications in 2021, suspiciously high output",
"Publication spike: 12 → 47 papers (2020 → 2021)",
"Repeated title pattern (4x): \"role of inflammation in...\", possible template",
"31 papers in single journal \"international journal of molecular biology\", over-concentration",
"Low author diversity, same author groups across many papers",
"Low citation impact: avg 1.7, possible predatory venue",
"High funding concentration, single-source dependency risk",
"1 terminated/withdrawn grants, compliance concern"
],
"requiredActions": [
"Review retracted publications, determine scope of affected research",
"Paper mill indicators, investigate authorship and submission patterns",
"Publications in suspected predatory venues, verify journal legitimacy",
"Review terminated/withdrawn grants for compliance issues",
"Citation pattern anomalies, check for citation rings or manipulation"
],
"evidence": [
{ "source": "researcherIntegrity", "recordType": "retraction", "count": 6, "detail": "6 retraction/correction flag points across publications" },
{ "source": "paperMill", "recordType": "paper_mill", "detail": "31 papers in single journal, over-concentration" },
{ "source": "fundingRisk", "recordType": "funding", "count": 1, "detail": "1 terminated/withdrawn grant" }
],
"confidence": { "level": "HIGH", "sourcesReturned": 6, "sourcesAttempted": 7, "ratio": 0.86, "recommendedHandling": "automate" },
"decision": {
"requiresHumanReview": true,
"recommendedAction": "investigate",
"monitoringPriority": "high",
"urgency": "72h",
"escalationReason": "Investigation threshold reached (composite 58)"
},
"topContributors": [
{ "dimension": "researcherIntegrity", "contributedPoints": 12.6, "weight": 0.3, "direction": "raises_concern", "reason": "Integrity level SUSPICIOUS" },
{ "dimension": "paperMill", "contributedPoints": 11, "weight": 0.25, "direction": "raises_concern", "reason": "Paper-mill level PROBABLE" }
],
"riskMemory": {
"snapshotCount": 3,
"riskTrend": "worsening",
"velocityPointsPerDay": 0.42,
"projectedScore30d": 71,
"projectedVerdict30d": "HIGH_RISK",
"deltaSinceFirst": 13
},
"runSummary": {
"elapsedMs": 4821,
"sourcesAttempted": 7,
"sourcesReturnedData": ["openalex-research-papers", "orcid-researcher-search", "pubmed-research-search", "semantic-scholar-search", "crossref-paper-search", "nih-research-grants"],
"sourcesFailed": [],
"sourcesSkipped": ["core-academic-search"]
},
"dataSourceErrors": { "core-academic-search": "Skipped: no CORE_API_KEY env var set (free key at core.ac.uk)" }
}
Every paid tool returns the same envelope header (schemaVersion, recordType, captureTimestamp, actorVersion, contentHash) plus runSummary. The confidence, decision, topContributors, evidence, and riskMemory blocks are specific to generate_integrity_report. The contentHash lets scheduled monitoring loops detect "nothing changed since last run" without storing the full body.
Output fields
The headline fields below are what most consumers branch on. The full enum surface for every decision-relevant field is in the research-integrity://schemas/decision-contract MCP resource (readable via resources/read, no tool call), and each scoring dimension also returns its own score, signals[], and level enum.
Decision layer (branch on these)
| Field | Type | Description |
|---|---|---|
compositeScore / verdict | number / string | 0-100 risk + CLEAR / MINOR_CONCERNS / INVESTIGATION_NEEDED / HIGH_RISK |
decision.recommendedAction | string | auto_clear / monitor / manual_review / investigate / escalate, branch on this, not the raw score |
decision.requiresHumanReview / urgency | boolean / string | Review gate + 24h / 72h / 7d / 30d / none |
confidence.level / recommendedHandling | string | HIGH / MODERATE / LOW + automate / human_review / advisory_only |
evidenceConvergence | object | Corroboration across independent dimensions (the strongest "is this real?" signal) |
reviewComplexity.safeToDeprioritize | boolean | True when a case can be cleared without escalation, the triage-compression signal |
policyEvaluation.actionUnderPolicy | string | Action adjusted to the selected policyProfile |
Evidence + explainability
| Field | Type | Description |
|---|---|---|
evidence | object[] | Structured findings with source, recordType, detail, and references |
ruleEngine | object | Coded triggeredRules[] (id / severity / category / rationale) + maxSeverity, the audit trace |
integrityNarrative | object | Deterministic summary + supporting + contradictory signals + recommended interpretation |
mitigatingFactors | string[] | Balancing/exculpatory evidence |
topContributors / integrityHeatmap | object | Ranked dimension drivers + 0-100 per-axis risk map |
crossSourceConsistency | object | Publication/identity agreement across sources (disagreement is a signal) |
reviewPackage | object | reviewType, criticalSignals, recommendedChecks, suggestedQuestions for the reviewer |
Behavioral + identity
| Field | Type | Description |
|---|---|---|
researcherArchetype | object | primary/secondary archetype + confidence |
integrityTimeline | object | Year-by-year velocity, retractions, journals, authors + inflectionEvents |
topicCoherence / careerStage | object | Field-coherence signal + coarse maturity heuristic (not a cohort percentile) |
coauthorNetwork / identityVerification | object | Run on the same fetched data, no extra cost |
Monitoring + governance
| Field | Type | Description |
|---|---|---|
riskMemory | object | Trend, velocity, 30-day projection, driftEvents, rulePersistence, archetypeTransitions, emergentSignals |
caseId | string | Persistent case handle (get_integrity_case / record_case_outcome) |
precedent | object | How similar prior cases resolved (accrues as cases are resolved) |
escalationConfidence | object | How sure the escalation is |
Provenance
| Field | Type | Description |
|---|---|---|
runSummary | object | sourcesReturnedData / sourcesFailed / sourcesSkipped + elapsedMs |
contentHash / scoringSchemaVersion | string | Dedup hash + pinnable scoring-model version for reproducibility |
How much does it cost to screen researchers?
Research Integrity Screening MCP uses pay-per-event pricing: you pay $0.045 per paid tool call. Platform compute costs are included. The get_researcher_memory tool is free: it reads accumulated history from the key-value store with no upstream fetch, so an agent can check what is already known before paying for a fresh screen.
| Scenario | Tool calls | Cost per call | Total cost |
|---|---|---|---|
| Quick test, single researcher screen | 1 | $0.045 | $0.045 |
| Integrity check plus citation anomaly analysis | 2 | $0.045 | $0.09 |
| Full integrity report (all 7 sources, 4 models) | 1 | $0.045 | $0.045 |
| Screen 10 grant applicants | 10 | $0.045 | $0.45 |
| Monthly journal submission workflow, 200 submissions | 200 | $0.045 | $9.00 |
You can set a maximum spending limit per run to control costs. The actor stops when your budget is reached, returning a structured error your pipeline can handle gracefully.
Apify's free tier includes $5 of monthly platform credits: enough for over 100 tool calls before you need to add payment. Compare this to institutional research integrity software priced at $3,000-15,000 per year. Most teams using this MCP spend under $20/month with no subscription commitment.
How it works
- Parallel fan-out. Each tool calls 2-7 source actors via
Promise.allSettled, so a slow or failing source degrades the result instead of blocking it. The full per-source map (and which key each needs) is in thecoverage/source-mapMCP resource. - Four deterministic models score the merged corpus: researcher integrity (retractions, Benford citation anomaly, velocity, ORCID completeness), paper-mill (title templates, journal concentration, author diversity), journal quality (citation impact, open-access ratio, venue diversity), funding risk (paper-to-grant ratio, HHI concentration, terminated grants).
- Composite + verdict. Weighted composite (integrity 30% + mill 25% + inverted journal-quality 25% + funding 20%) maps to CLEAR / MINOR_CONCERNS / INVESTIGATION_NEEDED / HIGH_RISK, with CRITICAL integrity or CONFIRMED_MILL forcing HIGH_RISK.
- Synthesis + memory. The decision, evidence, narrative, convergence, and review layers compose over those scores; a KV snapshot + case persist for longitudinal monitoring and precedent.
Every step is deterministic and reproducible. Full formulas and thresholds are in the methodology/scoring MCP resource, kept out of the README to keep it readable.
Tips for best results
-
Include institution in the researcher query. "Dr. Sarah Kim" returns less precise results than "Dr. Sarah Kim Yale School of Medicine". Disambiguation improves all seven data sources simultaneously.
-
Use ORCID IDs when available. If you have a researcher's ORCID ID (format: 0000-0002-XXXX-XXXX), pass it as the
researcherparameter. The ORCID actor returns the exact profile rather than a name search, eliminating false positives from common names. -
Run
detect_citation_anomaliesbeforegenerate_integrity_reportfor formal investigations. The citation anomaly tool returns the full Benford's law table, useful for building an evidence dossier. The full integrity report returns only the summary flag. -
Set spending limits for batch workflows. When screening 50 or more grant applicants, set a
maxTotalChargeUsdon the Apify run to cap exposure. The server returns a structured error when the limit is reached so your pipeline can handle it gracefully. -
Use
compare_institutional_integrityfor partnership due diligence. Rather than running two separate full reports, this tool queries both institutions in parallel and returns a structured side-by-side comparison in a single call. -
Add a topic filter to grant audits. Pair
audit_grant_research_linkwith a specifictopicparameter to narrow NIH grant results. "Elizabeth Torres CRISPR" is more targeted than "Elizabeth Torres" alone when a researcher has a large grant portfolio. -
Treat PROBABLE mill level as an escalation trigger, not a verdict. Title template patterns can arise from legitimate research programmes, clinical trial series, systematic reviews, and multi-part studies all use consistent naming conventions. Use the tool output to route submissions to a specialist reviewer.
Combine with other Apify actors
| Actor | How to combine |
|---|---|
| Researcher Integrity Check | Run this actor for deep single-researcher profiling; use the MCP for conversational AI workflows and batch screening |
| Company Deep Research | Combine when screening biotech or pharma companies whose leadership has academic publishing histories |
| ORCID Researcher Search | Pull raw ORCID profile data directly before feeding into integrity analysis |
| PubMed Research Search | Pull full biomedical literature sets for manual review of flagged publications |
| NIH Research Grants | Query NIH grants independently for portfolio-level funding analysis outside the MCP |
| SEC EDGAR Filing Analyzer | Cross-reference publicly traded biotech and pharma researchers against disclosed financial conflicts |
| B2B Lead Qualifier | Score academic-to-industry transition candidates using both research integrity and commercial signals |
Limitations
- Citation data completeness depends on source coverage. OpenAlex and Semantic Scholar have strong coverage for STEM fields; humanities and social sciences have lower citation indexing rates. Scores for non-STEM researchers may understate citation activity.
- Benford's law requires at least 10 cited papers to be statistically meaningful. Early-career researchers with fewer than 10 cited papers will not trigger the citation distribution check. Scores for these researchers are computed from the other three models only.
- Paper mill template detection uses 5-word title prefix matching. Legitimate research programmes such as multi-paper clinical trial series with consistent naming conventions can produce false positives. Always read the
signalsarray to assess whether the flagged pattern reflects the researcher's actual methodology. - NIH grant data covers US federal funding only. Researchers primarily funded by European, Asian, or private foundation grants will receive a "no grants found" penalty. Use the
topicparameter inaudit_grant_research_linkto reduce false positives for international researchers. - ORCID completeness scoring penalises sparse profiles. Some senior researchers maintain sparse ORCID profiles by choice. A low ORCID sub-score alone should not drive a negative verdict without corroborating signals.
- This tool detects statistical anomalies, not fraud. Anomalous patterns have legitimate explanations. The output is a screening signal for human review, not a forensic determination.
- Query resolution depends on name disambiguation. Common researcher names without institutional context return mixed results from multiple individuals. Always include institution name or ORCID ID for definitive identification.
- Child actor timeout is 120 seconds. If a data source is slow, it times out and returns an empty array for that source. The composite score is computed on available data; missing sources reduce confidence in low-risk verdicts.
Integrations
- Apify API, trigger integrity screenings programmatically from grant management systems or editorial workflow software
- Webhooks, push HIGH_RISK verdicts to Slack, email, or case management tools the moment a screening completes
- Zapier, connect to Airtable or Google Sheets grant trackers; auto-log integrity scores when new applicants are added
- Make, build editorial submission workflows that auto-route papers to integrity review queues based on the mill level verdict
- Google Sheets, export batch researcher screening results to shared spreadsheets for committee review
- LangChain / LlamaIndex, embed research integrity screening as a tool in LLM agent pipelines for automated due diligence workflows
Troubleshooting
Composite score is 0 despite querying a well-known researcher. This usually means the researcher's name did not resolve correctly across the data sources and all actors returned empty datasets. Try adding the institution name to the query. For common names (e.g. "Wei Zhang"), add the specific field ("Wei Zhang computational biology MIT") or use the ORCID ID directly.
Tool returns "error": true, "message": "Spending limit reached". Your Apify run has hit the maximum charge limit configured for the run. Increase maxTotalChargeUsd in your run configuration, or purchase additional platform credits in the Apify console.
Paper mill score is high for a legitimate systematic review programme. The template detection model flags repeated title prefixes. Systematic reviews and meta-analyses legitimately use series naming conventions ("Systematic review of X in Y: Part 1, 2, 3"). Check the specific pattern in signals, if it matches the researcher's known methodology, contextualise the flag as a false positive in your assessment.
audit_grant_research_link shows no grants for a funded researcher. NIH data covers only US federal grants. Non-NIH funding (NSF, DOD, DARPA, private foundations, international funders) will not appear. Add a topic parameter to improve NIH search relevance and note the limitation in your assessment.
Child actor timeouts causing incomplete results. Empty data arrays in the detailed output indicate that one or more source actors timed out. Re-run the same query, subsequent runs typically succeed. If a specific source consistently times out, treat the generate_integrity_report result as partial and note which sources were unavailable.
Responsible use
- All data accessed by this server comes from publicly available academic databases and federal grant records.
- Research integrity screening results are statistical indicators, not forensic findings. Do not use scores as the sole basis for adverse employment, funding, or publication decisions without independent expert review.
- Comply with applicable data protection regulations when storing or sharing screening outputs that include personal information about researchers.
- Do not use this tool to harass, defame, or discriminate against researchers based on screening scores alone.
- For guidance on web scraping and data use legality, see Apify's guide.
FAQ
How does research integrity screening with Benford's law work?
Benford's law predicts that in naturally occurring numerical datasets, the digit 1 appears as the leading digit about 30.1% of the time, digit 2 about 17.6%, down to digit 9 at 4.6%. Citation counts across a large publication set follow this distribution naturally. When a researcher's citation counts deviate significantly, particularly when digit 1 appears far less than expected, it can indicate artificial inflation of specific citation counts. The detect_citation_anomalies tool returns the per-digit observed vs. expected comparison so your team can assess the magnitude of deviation for each digit independently.
What is a paper mill and how does research integrity screening detect it?
Paper mills are commercial services that produce fake or plagiarised academic manuscripts for sale to researchers who need publication credits. Their output tends to share structural fingerprints: repeated title templates across papers, excessive concentration in a small number of accepting journals, and the same tight author groups appearing across many unrelated papers. The check_publication_flags tool detects all three patterns using title prefix frequency analysis (5-word prefixes appearing 3+ times), journal concentration scoring (above 50% in one journal), and author-set uniqueness ratios (below 30% unique across 10+ papers).
Can research integrity screening definitively identify academic fraud?
No. The MCP identifies statistical anomalies and red flags associated with integrity concerns. Abnormal patterns have legitimate explanations, a researcher who publishes exclusively in one journal may be the editor of that journal, or may work in a narrow field with few suitable venues. Use the output to prioritise human review, not to substitute for it. The requiredActions field identifies the specific checks a human reviewer should perform next.
How accurate is the publication velocity check? The velocity model flags any year where a researcher's publication count exceeds 30 papers, and flags year-over-year increases of 3x or more with at least 10 papers in the latter year. These thresholds are calibrated against typical academic output (most researchers publish 3-8 papers per year). A single high-output year is possible for researchers leading large collaborative projects or clinical trial consortia. Consistent multi-year high velocity is a stronger signal.
How long does a typical research integrity screening take?
The screen_researcher_integrity and check_publication_flags tools query 3-4 data sources in parallel and typically complete in 60-90 seconds. The generate_integrity_report tool queries all 7 sources in parallel and typically completes in 90-150 seconds, depending on API response times from the underlying academic databases.
How many researchers can I screen in one session? There is no hard per-session limit. For batch screening, run tool calls sequentially or in parallel depending on your client's concurrency. Each call is independently priced at $0.045. For screening 200 or more researchers, consider scheduling Apify runs via the API and processing results asynchronously.
How is research integrity screening different from iThenticate or Turnitin? iThenticate and Turnitin detect textual plagiarism by comparing manuscript text against known sources. This MCP does not analyse manuscript text, it analyses publication metadata, citation patterns, grant records, and researcher profiles. The two approaches are complementary: use plagiarism detection for submitted manuscripts and this MCP for researcher-level pattern analysis and pre-award screening.
Does research integrity screening detect conflicts of interest? Not directly. The funding risk model identifies grant-publication linkages and funding concentration, which can reveal financial relationships. For explicit conflict of interest screening, including industry payments, equity holdings, or consulting relationships, combine with financial disclosure databases. The SEC EDGAR Filing Analyzer can identify researchers with disclosed financial interests in publicly traded companies.
Is it legal to use this tool for researcher screening? All underlying data sources are publicly available: OpenAlex, ORCID, PubMed, Crossref, CORE, and NIH Grants are open academic databases. Accessing and analysing public records for research integrity purposes is a standard practice in academic administration and grant management. See Apify's guide on web scraping legality for broader context.
Can I schedule research integrity screening to run periodic sweeps? Yes. Use the Apify Scheduler to trigger the actor on a daily, weekly, or monthly cadence. Configure a webhook to push HIGH_RISK verdicts to your notification system. This is useful for ongoing monitoring of a research portfolio, alerting when a previously CLEAR researcher's score moves to INVESTIGATION_NEEDED after new publications appear.
What happens when a data source returns no results? The scoring functions handle empty arrays gracefully, each source defaults to an empty array when its actor times out or returns no matches. Scores are computed on available data. When ORCID returns nothing, the completeness model adds a 10-point penalty to the integrity sub-score and emits a "No ORCID profile found" signal. Treat results where multiple sources returned empty with more caution than results backed by all seven sources.
How is research integrity screening different from running each academic database search manually? Manual cross-database research takes 2-3 hours per researcher. This MCP queries all seven sources in parallel in under 2 minutes, applies four scoring algorithms automatically, and returns machine-readable structured output that your AI agent can reason over. It eliminates transcription errors between databases and produces consistent, comparable scores across every researcher you screen.
Help us improve
If you encounter issues, you can help us debug faster by enabling run sharing in your Apify account:
- Go to Account Settings > Privacy
- Enable Share runs with public Actor creators
This lets us see your run details when something goes wrong, so we can fix issues faster. Your data is only visible to the actor developer, not publicly.
Support
Found a bug or have a feature request? Open an issue in the Issues tab on this actor's page. For custom solutions or enterprise integrations, reach out through the Apify platform.
Related actors
AI Cold Email Writer — $0.01/Email, Zero LLM Markup
Generates personalized cold emails from enriched lead data using your own OpenAI or Anthropic key. Subject line, body, CTA, and optional follow-up sequence — $0.01/email, zero LLM markup.
AI Outreach Personalizer — Emails with Your LLM Key
Generate personalized cold emails using your own OpenAI or Anthropic API key. Subject lines, opening lines, full bodies — tailored to each lead's role, company, and signals. $0.01/lead compute + your LLM costs. Zero AI markup.
Bulk Email Verifier — MX, SMTP & Disposable Detection at Scale
Verify email deliverability in bulk — MX records, SMTP mailbox checks, disposable detection (55K+ domains), role-based flagging, catch-all detection, domain health scoring (SPF/DKIM/DMARC), and confidence scores. $0.005/email, no subscription.
CFPB Complaint Intelligence — Vendor Risk & Screening
Turn 5M+ CFPB consumer complaints into decisions: screen companies pass / review / fail, score complaint-handling risk, monitor what changed since last run, benchmark cohorts, and build audit-ready due-diligence packs. Filter by company, product, state, and date. No API key.
Ready to try Research Integrity Screening MCP?
Run it on your own Apify account. Apify offers a free tier with $5 of monthly credits.
Open on Apify Store